Java Web Scraping Without Getting Blocked — The Ultimate 2024 Guide


Vilius Dumcius
Last updated -
In This Article

Ready to get started?
Java web scraping just got much easier. Web scraping is an excellent tool for modern businesses. With it, you can collect data at scale, automate actions, monitor market changes, and much more. Information is power, and web scraping is a reliable source of endless information.
But it’s hard.
Each target site requires a specific code. You can also get blocked. It might be hard to extract data from HTML. Most importantly, most guides about Java web scraping are completely outdated. Old parsers, unsupported libraries, regular expressions. Scratch all that.
Today you will learn a simple way to scrape any website with Java, no matter how complex it is. In addition, you will learn how to avoid getting blocked and how to take screenshots and extract data with your web scraper.
Let’s get started!
Java Web Scraping — How It Works?
There are quite a few ways to scrape pages in general. In the past, a common way to do it was to get the HTML code from your target site. Then you would use regular expressions to extract data.
This method can work for basic sites, but it is quite challenging to set up. Also, you need to find the perfect rule to extract the elements you want to.
Sometime after that, a few code parsers appeared. They were libraries to mimic a browser. They were a step forward, but still very limited. Considering that most sites nowadays rely heavily on dynamic elements, that’s not good enough.
That’s where most tutorials stop. And here we are to tell you - there is a better way.
The Best Java Web Scraping Library is Playwright
The best way to perform web scraping is by using a headless browser. Headless browsers allow you to command browser actions using a programming language. There are many good options out there. One of the most popular options is Puppeteer .
However, there’s no Puppeteer library for Java. But there’s something even better - Playwright .
Playwright is the evolution of Puppeteer. It has the same actions and more, and it’s just as easy to use. With it, you can create a browser window, store it in a variable, navigate to a page, perform actions, and also extract data.
It allows you to target elements using xPath, vue/react selectors, layout attributes (to the left of a specific element), or CSS code. You can also target them by text contents, or even combining CSS and text selectors. For example, if you are building a price monitor, you can target an element with “Price” in it, as well as inside the main container.
In addition, headless browsers can work well with regular data collection, such as connecting with APIs or getting data from XHR calls.
Now let’s see what you can do.
Playwright, Java, and Some Examples
Today, we are going from zero to data scraping. In other words, we’ll cover everything from the very basics of installing an IDE, to processing your data.
Here are our main goals:
- Install a Java IDE
- Install Playwright
- Fix common issues
- Connect to a site
- Take a screenshot
- Connect to a site using authenticated proxies
- Collect data
Here is how you can do it.
Web Scraping With Java - The First Steps
One of the benefits of web scraping with Java is that it runs everywhere. Once you compile the code, you can run it on any OS you want. This is handy in case you have multiple computers and you need to jump around between them.
For this reason, you need a code editor and compiler. So if you haven’t already, install an IDE. We recommend using Eclipse, as it is quite easy to get started.
Then you need Maven . If you are using Eclipse, you don’t need to install it, but depending on your IDE, you will need it. With Maven, you can easily build projects with external dependencies without manually downloading them.
In Eclipse, go to File > New > Other (Command + N) . Search for Maven and select Maven Project :
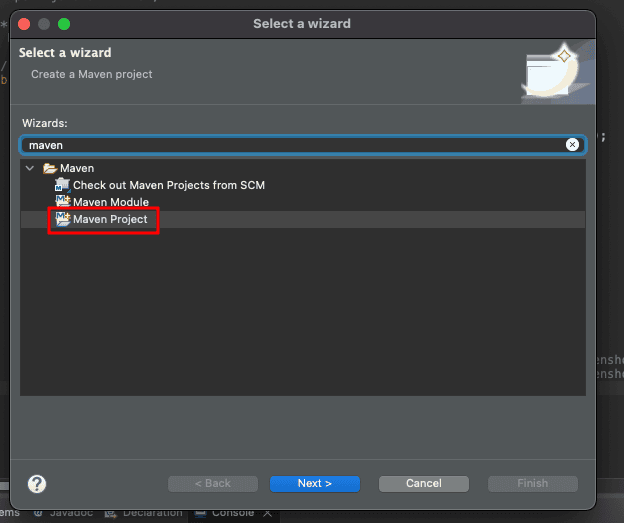
Click on Next . Select your location and check the simple project option to skip the archetype selection. Add your Group ID , Artifact ID , and further details about your project. Finally, click on Finish .
You should see a new project in your Package Explorer . Wait a few seconds, and you’ll see the files and dependencies being created.
Moving on, open the pom.xml file. This is the file that tells Maven what this project is, what kind of dependencies it has, and so on. This is the original file:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.iproyal</groupId>
<artifactId>com.iproyal.webscraper</artifactId>
<version>0.0.1-SNAPSHOT</version>
</project>You need to add some data to load Playwright before the closing the </project> tag. You can use something like this:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.iproyal</groupId>
<artifactId>com.iproyal.webscraper</artifactId>
<version>0.0.1-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>com.microsoft.playwright</groupId>
<artifactId>playwright</artifactId>
<version>1.27.0</version>
</dependency>
</dependencies>
</project>That’s pretty much it in terms of setup. Now let’s create your package and your main class.
Right click the src/main/java folder, and select New package . Make sure you keep the Create package-info.java option unchecked.

And inside the package we need to create a class. Right click the package and click on New class . Check the option to create a public static void main , to save you a bit of typing:
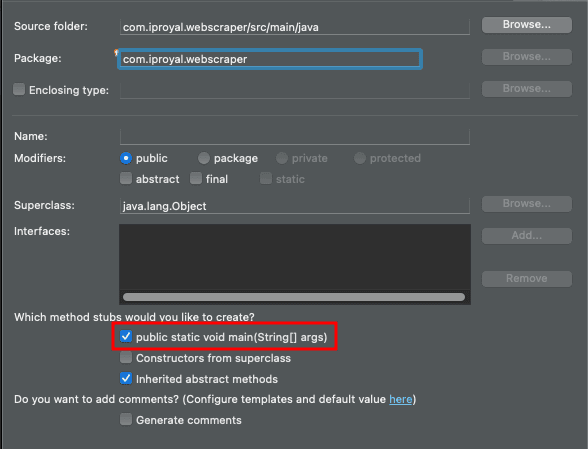
And that’s it. You are ready to code!
Java Screen Scraping
Now you just need to add your scraper code there, compile it, and you’ll see the results in the console. If there are any errors, your IDE should highlight them to you.
Let’s start with a simple example, taking screenshots. To make it easier, use this code at the beginning of your file for all examples. You’ll see some warnings sometimes that the package isn’t used, but you can ignore them.
package com.iproyal.com.iproyal.scraper;
// import playwright and the proxy packages
import com.microsoft.playwright.*;
import com.microsoft.playwright.options.Proxy;
// import some useful packages
import java.nio.file.Paths;
import java.util.Arrays;
import java.util.List;Next, use this code as your public static void main class:
public static void main(String[] args) {
try (Playwright playwright = Playwright.create()) {
BrowserType.LaunchOptions launchOptions = new BrowserType.LaunchOptions();
try (Browser browser = playwright.chromium().launch(launchOptions)) {
BrowserContext context = browser.newContext();
Page page = context.newPage();
page.navigate("https://ipv4.icanhazip.com/");
page.screenshot(new Page.ScreenshotOptions().setPath(Paths.get("screenshot-" + playwright.chromium().name() + ".png")));
System.out.println("Screenshot taken");
context.close();
browser.close();
}
}
}
}This code tries to open Playwright with Playwright.create(). Then it saves the LaunchOptions, but more on that later. Next, the code snippet opens a Chromium browser instance with playwright.chromium().launch(launchOptions).
Then it is quite similar to Puppeteer. Open a new page with newPage(), and navigate with page.navigate(“ https://ipv4.icanhazip.com/ “). You can take a screenshot with page.screenshot(new Page.ScreenshotOptions().setPath(Paths.get(“screenshot-“ + playwright.chromium().name() + “.png”)));
Each of these methods has customizing options. For example, if you want to specify a browser window size, you can do it. And you can add a specific file name for your screenshot like we did here.
Run this code, and if you didn’t change anything else in your Eclipse settings you should see… an error. Something like this:
<span style="font-weight: 400;">Exception in thread "main" java.lang.Error: Unresolved compilation problem:</span>
<span style="font-weight: 400;"> References to interface static methods are allowed only at source level 1.8 or above</span>
``But it’s an easy fix. Right-click on your project, select Properties . Then go to the Libraries tab and click on your JRE version > Edit .
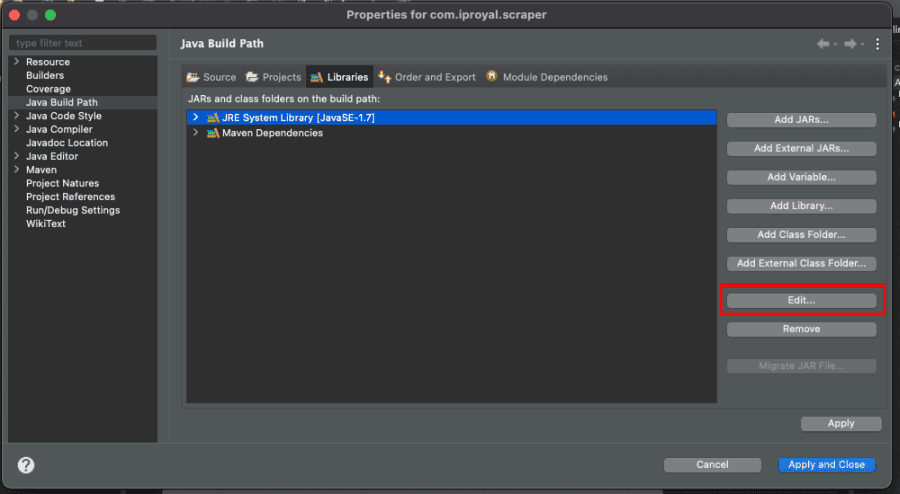
Select Java 11 (or 8) and save. Click on Apply and Close . That’s it, the error is gone.
Now run it again, and you should see this nice message:

Nice! But where did it go?
Go to your home folder /eclipse-workspace/[project]/ and you’ll see your screenshot there. It should be titled screenshot-chromium.png. It’s worth mentioning that you can scrape using Chrome and Firefox just as easily. Instead of chromium(), use their respective methods.
If you do this a couple of times, it’s likely that your target site is going to block you. Let’s see how you can avoid this.
Java Scraping Without Getting Blocked — Playwright Authenticated Proxies
Web scraping is perfectly legal. However, companies don’t like giving away information. For this reason, it’s quite common for a website to block you when you are just starting your web scraping efforts. And in order to avoid getting blocked, you need to understand how websites block scrapers in the first place.
There are a few things that can tell them right away. For example, a request without any user metadata (browser, OS, and other information) is likely coming from a software. Unless you manually add headers, many coding libraries won’t add them for you.
But Playwright fixes this for you. Since your Java web scraping request uses a real browser, the entire request is 100% legitimate. It is just controlled by your code.
Then they look at other points, such as your IP. If you request a lot of pages, leave quickly and come around the same time, it’s a sign that you are a bot. But the main way they do it is by checking your IP address.
So, the solution is to use IPRoyal’s Residential Proxies service. With it, you can use rotating IP addresses from real residential users. This allows you to hide your real address, so the website owners just can’t connect the dots.
Sign up for the service (it starts at $4), and you’ll get access to the client area. In it you can see the proxy URL and set up your credentials:
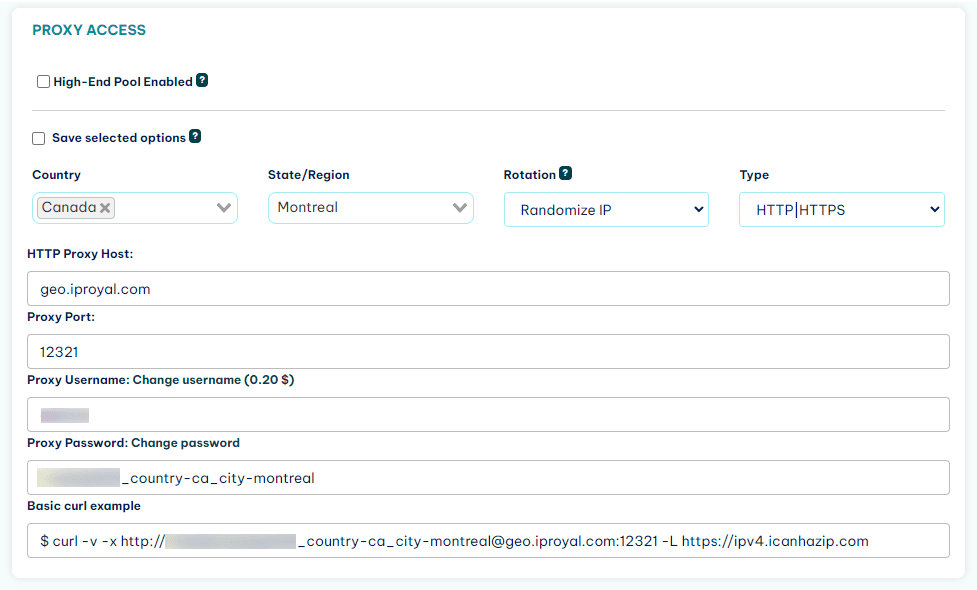
Now you just need to use this information in your Java web scraper and you are good to go.
In the first step, you saved a screenshot with your IP address. It’s something like this:
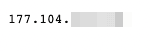
You can use the LaunchOptions to connect to IPRoyal and use a proxy in your request. This is the main class to do it:
public static void main(String[] args) {
try (Playwright playwright = Playwright.create()) {
BrowserType.LaunchOptions launchOptions = new BrowserType.LaunchOptions();
launchOptions.setProxy(
new Proxy("http://geo.iproyal.com:12321")
.setUsername("username")
.setPassword("password")
);
try (Browser browser = playwright.chromium().launch(launchOptions)) {
BrowserContext context = browser.newContext();
Page page = context.newPage();
page.navigate("https://ipv4.icanhazip.com/");
page.screenshot(new Page.ScreenshotOptions().setPath(Paths.get("screenshot-" + playwright.chromium().name() + ".png")));
System.out.println("Screenshot taken");
context.close();
browser.close();
}
}
}The entire main class stays the same, but now you are using the setProxy method to use a proxy, then add a username and password. This is the screenshot using a proxy in your Java web scraper:

It’s a completely different IP address. So, as far as the website owner knows, these are two different users visiting their site. If you enable the IP rotation, this address also changes for every request, making it very hard to detect.
Data Scraping With Java
In addition to screenshots, you can take custom screenshots (full page, specific elements), get data from page elements, and interact with pages.
Let’s see some examples.
To make things easier, the following examples all go inside this block:
try (Browser browser = playwright.chromium().launch(launchOptions)) {
}If you want to select an element, you can do it with the .locator method. Then you can extract the text contents of it if you want. For example:
BrowserContext context = browser.newContext();
Page page = context.newPage();
page.navigate("https://playwright.dev/java/");
String title = page.locator(".hero__title").innerText();
System.out.println("Hero title: " + title);
context.close();
browser.close();This code loads the Playwright site. Then it looks for the .hero__title CSS class and extracts its text. You can do anything you want with this variable. In our example, it’s a simple print. However, you could manipulate it, save it to a DB, check it against other values, and so on.
You can click on elements using the .click() method after the locator, like this:
BrowserContext context = browser.newContext();
Page page = context.newPage();
page.navigate("https://playwright.dev/java/");
page.locator(".DocSearch-Button").click();
page.screenshot(new Page.ScreenshotOptions().setPath(Paths.get("screenshot-1.png")));
System.out.println("Screenshot taken");
context.close();
browser.close();This code should save a screenshot with the search field highlighted:

Similarly, you can interact with form elements. For example, you can fill a text box using the fill() method after a locator.
BrowserContext context = browser.newContext();
Page page = context.newPage();
page.navigate("https://playwright.dev/java/");
page.locator(".DocSearch-Button").click();
page.locator("#docsearch-input").fill("test");
page.screenshot(new Page.ScreenshotOptions().setPath(Paths.get("screenshot-1.png")));
System.out.println("Screenshot taken");
context.close();
browser.close();Here is the result:
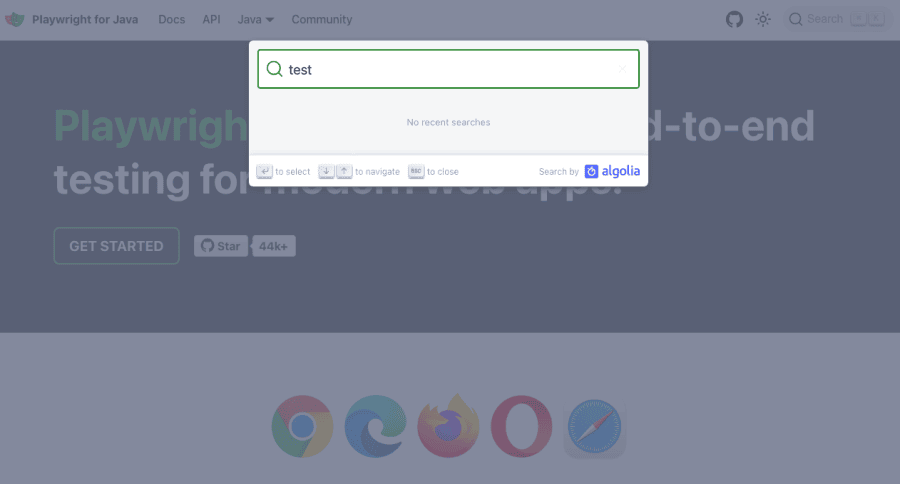
This is just a starting point. There are many other options in terms of locators, interactions, and mimicking user actions. You can do virtually anything a real user would do with Playwright Java.
Conclusion
Today you learned how to perform Java web scraping without getting blocked. We also explored many modern technologies you can use to get and process data for your business easily.
Playwright is an amazing tool. There are many other options in terms of selectors, interactions, and data processing, but hopefully this was a good starting point.
We hope you enjoyed it, and see you again next time!
FAQ
Must declare a named package eclipse because this compilation unit is associated to the named module.
Delete the module-info.java file from your project and this error will go away.
References to interface static methods are allowed only at source level 1.8 or above.
Like we’ve explored in the article, you can fix this under Project (right click) > Properties > Libraries > Select the JRE of your project > Edit > Select a different Java version (11 is good) > Finish > Apply and close.
If you don’t see Java 11 as an option, you can download it to your OS. You can find it here .
Playwright Proxy cannot be resolved to a type > import.
If you see this error in your project, make sure that you add this in the beginning of your file:
import com.microsoft.playwright.options.Proxy;
Sometimes even with the playwright.* line the proxy options aren’t loaded.
Author
Vilius Dumcius
Product Owner
With six years of programming experience, Vilius specializes in full-stack web development with PHP (Laravel), MySQL, Docker, Vue.js, and Typescript. Managing a skilled team at IPRoyal for years, he excels in overseeing diverse web projects and custom solutions. Vilius plays a critical role in managing proxy-related tasks for the company, serving as the lead programmer involved in every aspect of the business. Outside of his professional duties, Vilius channels his passion for personal and professional growth, balancing his tech expertise with a commitment to continuous improvement.
Learn more about Vilius Dumcius

