How to Use a cURL Proxy to Scrape Websites (With Interactive Examples)
Tutorials

Vilius Dumcius
A cURL proxy is the easiest way to scrape data without getting blocked.
cURL is an amazing tool. It is easy to use, flexible, and widely available in many programming languages and operating systems.
For this reason, cURL is a great option for scraping data from websites. The problem is, if you just use cURL commands, you will get blocked really fast.
Therefore our goal for today is to see how you can use cURL to scrape websites effectively.
You’ll learn how to use cURL in general terms, when you should use it, how to set up proxy authentication , and other methods to avoid detection.
And let’s make this even better. Instead of just reading the commands and trying to memorize them, we have live examples. You can follow along and test them using the tools linked in each section.
Let’s get started!
What Is the cURL Tool Used For?
cURL (Client URL) is a tool that allows you to communicate with a specific URL, send any data you want, and read what is sent back.
Therefore, it allows you to perform any browser-like connections, such as loading a page, connecting to an API, and sending form data. You can learn how to download curl file in our blog post.
For this reason, it’s very powerful when it comes to web scraping.
You can use 200+ prebuilt commands to fine-tune what you want to do.
You can run simple commands such as getting a page:
curl https://www.google.com
( Try it )
Which returns this:

But you can mix up different options and run complex commands, such as requesting a range of pages at once using a specific proxy:
curl -U user:password -x http://proxyurl:port https://en.wikipedia.org/wiki/[1-9]
( Try it - make sure to replace the username, password, and proxy URL/port)
This command sends nine different requests at once (pages 1 to 9), each with its own response.
This method of using a variable in your request is called URL globbing.
It’s important to notice that cURL is not a parser. It sends and requests data. But don’t expect it to behave like a headless browser, creating complex DOMs and dynamically loading components.
With that in mind, cURL is amazing to scrape data from:
- Plain websites (without dynamic content)
- XHR requests
- APIs
How Do You Pass Proxy Details in cURL Command?
There are three main ways to use proxy authentication in cURL:
- Use it directly in the command line
- Use variables or aliases
- Use a .curlrc file
If you haven’t already, sign up for IPRoyal’s Residential Proxy service . It is the best way to ensure you won’t get blocked while running your scraping tasks.
Once you do it, you get two options to proxy your requests. You can use the regular authentication available in your client area:
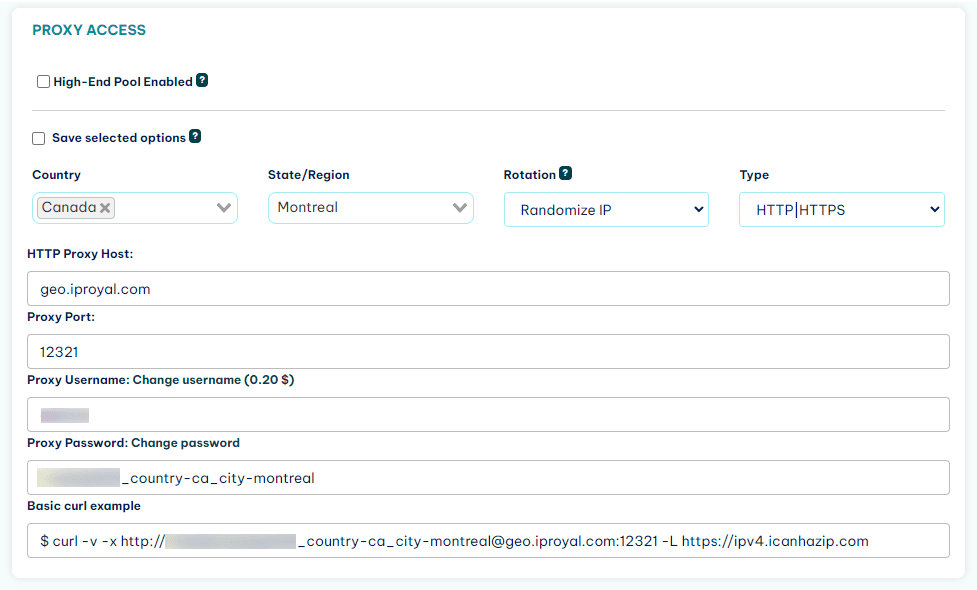
Or you can whitelist your IP, which allows you to use it without authentication.
In terms of using it, as you saw before, the most basic syntax is to use the -U command to set a user:password pair and the -x command to set the proxy URL/port.
These are the short commands. Their respective long versions are --proxy-user and --proxy. In case you are wondering, all short cURL commands have a long version, and most long commands have a short version.
So you can use it like this:
curl --proxy-user user:password --proxy http://proxyurl:port https://en.wikipedia.org/wiki/[1-9]
( Try it )
Or like this:
curl -U user:password -x http://proxyurl:port https://en.wikipedia.org/wiki/[1-9]
( Try it )
Both commands are exactly the same, they just use a short or a long version name.
Keep in mind that this method might expose the credentials to other users on the same system. Also, it can get quite annoying to type down the user/password in each of your requests.
For this reason, the following methods might be a better option since they allow you to store and retrieve the credentials.
Does cURL Use Proxy Environment Variables?
You can use cURL with proxy as environment variables. This allows you to save your proxy data once and retrieve it at any time.
The syntax is quite simple - you can set environment variables with the “export” command. And you can view them with echo $variable_name.
So you can use this:
export http_proxy="http://username:password@proxyURL:1234"
export https_proxy="https://username:password@proxyURL:1234"
echo $http_proxy
echo $https_proxy
( Try it )
If you run this code, you’ll see that the correct values are saved to the environment variables.
Now, whenever you run a curl command, no matter how simple it is, it uses that proxy.
Great! Right?
Well, since your proxy is on the shell variables, it means that any other command that uses these variables will use the proxy credentials as well.
If that’s what you want, go for it. If not, let’s keep reading so we can find a better solution.
How Do I Run an Alias?
Aliases are short notations for a command. You could, for example, replace all calls for “curl’ with a different command, which could include your proxy data,
But you can take a better approach.
You can create a new command, so you’ll always know that when you run it, you are using the proxy credentials.
For example, you can use this:
alias curlp="curl --proxy-user user:password --proxy http://proxyurl:port "
curlp http://wikipedia.com
(no live examples for this one - the online editor doesn’t allow storing aliases)
In this code, you are creating an alias with the name curlp. When you load it, the command line actually expands curlp to the entire curl declaration and appends the URL to it. Therefore, your curlp command already includes proxy authentication at all times.
In addition, you can save this alias to your profile files ( ~/.bashrc or equivalent ) to make it available at all times.
How Do I Create a Curlrc File?
Another method to set up a cURL proxy is to use a .curlrc file. You can create a file in your home directory under ~/.curlrc (or _curlrc on Windows). Thus, whenever you run a cURL command, this file is loaded automatically.
In this file, you can include many options. You can write them as a command or as a key=value pair, like this:
proxy http://proxyURL:port
proxy-user=username:password
This means that whenever you run a new cURL command, it will use these settings.
How Do I Pass Multiple Headers in a cURL Command?
In addition to proxies, you can use headers to avoid getting blocked. Most browsers pass their user agent and information, so you’ll look suspicious if you don’t do it.
You can use the exact same methods you used for proxies to set up headers.
Thus, you can set headers in your command line like this:
curl https://www.google.com --header "CustomSetting: CustomValue" --header "AnotherCustomSetting: AnotherCustomValue" --verbose
( Try it )
With the verbose command, you should see the entire request, and there you’ll find:
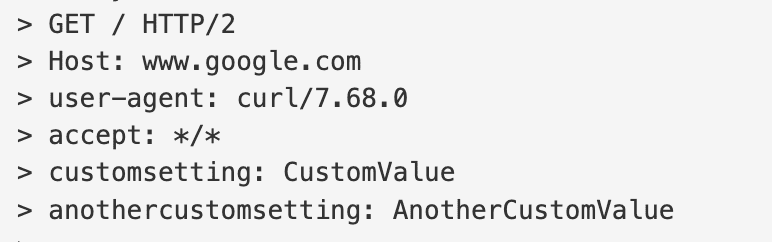
So you can pass as many headers in a cURL command as you want. You can use the --header command or just -H.
If you are wondering how you can find realistic headers, you can use your own browser for that.
Open the developer tools, go to the network tab and reload the page. Right-click any of the requests and copy the headers or even the entire cURL command:
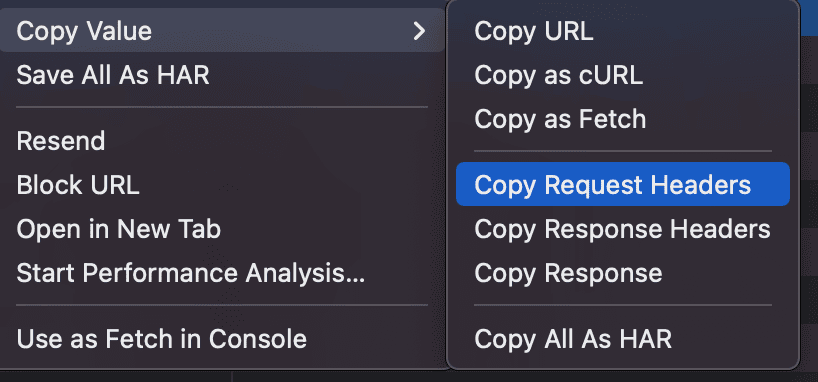
You can use this to mimic a realistic country, user agent, locale and many other settings. You can even use multiple headers combinations to go full stealth mode.
Then, once you have your headers set up, you can store them as variables, aliases or in a .curlrc file. This allows you to automatically load cURL proxy and multiple headers effortlessly.
How Do I POST JSON With cURL?
You can use the -- json command to post JSON data with cURL. In reality, the --json command is a shortcut for three commands:
- --data [arg]
- --header "Content-Type: application/json"
- --header "Accept: application/json"
You can try it out like this:
curl http://example.com --json '{ "scraping": "yes" }'
( Try it )
Now, if you test it, it’s likely that it won’t work. That’s because the json command isn’t available in all cURL versions. But since it is just an alias for three commands you can create your own JSON command if you want (as an alias). Or you can use the original version:
curl http://example.com --data '{ "scraping": "yes" }' --header "Content-Type: application/json" --header "Accept: application/json"
( Try it )
In addition to simple JSON data in the command line, you can reference files using the @[filename] pattern. For example, @data.json, or even @data.txt.
How to Get Data From Any Site With cURL and Grep
Now you can safely interact with almost any site. But how do you extract information from it?
There are quite a few options.
If you are reading data from an API or XHR requests, you can use a command like jq. However, if you are loading a static site, it’s likely that you’ll need grep.
Grep (Global Regular Expression Print) is a tool that allows you to search data using regular expressions.
Therefore, in this case you need to use curl to get the HTML contents of a page, then use grep to match it against a pattern.
For example, you can get the last edit date of a wikipedia page using this command:
curl https://en.wikipedia.org/wiki/The_Beatles --silent | grep -Eoi '<li id="footer-info-lastmod">(.*)</li>'
( Try it )
But whenever possible, try to load structured data instead. For example, Wikipedia provides you with a raw version that is much easier to work with. And a lot of sites provide you APIs, so you don’t need to deal with complex regular expressions.
Conclusion
Today you learned how to perform cURL calls with proxy authentication. In addition, you saw many other methods to stay undetected and to extract data from sites in general.
We hope you enjoyed it, and see you again next time!
FAQ
Runtime Error With cURL and Grep
Sometimes you might get a runtime error in your cURL proxy. The first step is to remove the grep command and check the actual output from the cURL operation. If there’s no HTML code, then check the cURL command, URL, and redirects. If needed, enable the verbose mode.
If there is HTML code, then check the regex in the grep command. Also, check if all the grep parameters are correct.
Curl error 28: Operation timed out
There are many reasons for operation timeouts, from something simple such as a slow connection to more complex issues, such as a hosting provider catching your scraping efforts.
curl: (3) URL using bad/illegal format or missing URL
URLs can only contain properly scraped values. Make sure you aren’t using special characters there, such as spaces, non-Latin letters, and others.
Empty contents
If the cURL operation returns no content, check if there are any redirects. Sometimes there are redirects from HTTP to HTTPS, or even from non-www to www versions of a site. If you don’t enable redirects in cURL, it will just stop at the first request.
cURL command not found
This usually happens when cURL itself isn’t available in your system. Update your libraries manager, and install it.

