No-Code Web Scrapers: Simplifying Data Extraction Without Coding
Tutorials

Vilius Dumcius
Before the no-code web scrapers, gathering online data required extensive programming knowledge. Understanding web development essentials like HTML, CSS, and the JavaScript coding language was paramount to targeting website elements accurately. At the same time, Python and Ruby knowledge helped build web scrapers from scratch.
This limited the availability of web scrapers to tech-savvy specialists and businesses that could afford them. Nowadays, when big data powers numerous enterprises , access to online information is a must-have to remain competitive. A no-code web scraper lets you scrape data without writing a single line of code, greatly broadening scraping accessibility.
In this article, we will elaborate on this rather new technology and how you can deploy it to streamline numerous business tasks.
What Is a No-Code Web Scraper?
A no-code scraper is a software application that enables data extraction from online sources without writing a single line of code. Its main advantage is user-friendliness, which allows non-IT professionals to get the required data in a format ready for further analysis.

The demand for data primarily fueled the demand for no-code web scrapers. A Harvard Business Review research reveals that businesses that have a clear data-driven strategy outperform their counterparts in fields like revenue, customer retention, and operational efficiency.
Just as important is cost reduction. Web scraping software automates the tedious process of gathering online data manually. It’s a time-consuming task that could take weeks for large data sets, and the repetitiveness increases the likelihood of human error.
To illustrate the benefits of a no-code scraper better, let’s juxtapose it with a traditional scraping tool that requires extensive programming knowledge. Take a look at the table below for a detailed comparison.
| Comparison criteria | No code scraper | Traditional scraper |
|---|---|---|
| User-friendliness | Designed to be highly user-friendly and suited for beginners | Unsuited for web scraping beginners without a focus on user-friendliness |
| Availability | Available to all specialists who require scraped data | Limited to IT professionals with coding knowledge |
| Customization | Limited customization options | Highly customizable |
| Maintenance | Does not require continuous surveillance, relatively easy to upkeep | Requires constant attention |
| Scalability | Limited scalability | Scalable for projects of all sizes |
| Learning curve | Easy to learn | Steep learning curve |
| Cost | Low cost or free | Can get pricey due to development and upkeep costs |
As you can see, both have advantages and disadvantages. Small-to-medium businesses without a demand for gigantic online datasets can fulfill their web scraping needs with no-code web scraping tools. On the other hand, corporations or enterprises that deal with big data will find them lacking due to limited customization options.
Simultaneously, no-code scrapers are suited for personal use for users without coding knowledge. Understandably, web scraping has been considered a business task for a long time, but it is becoming more popular among casual users.
For example, people can scrape real estate websites to compare prices while looking for house purchase or rent options. The same applies to plane tickets, holiday discounts, and much more. Let’s go over no-code scrapers use cases in more detail.
Price Monitoring
Comfortable for personal use to save time, price monitoring is extremely important for all businesses. After all, setting adequate prices is one of the leading marketing steps that will either lure customers or drive them away. No-code web scraping allows targeting retail websites to extract data about commodity prices and exclusive discounts.
What’s more, it lets you automate the task of continuously monitoring price changes, so that you can adapt yours whenever the market situation shifts. Keep in mind that extracting data from retail is more complicated than it sounds, as many have anti-scraping protection. However, it is certainly possible to use rotating residential proxies to extract data with a changing IP address, which bypasses the blocks.
Market Research
Similar to price monitoring, market research is paramount for business longevity. Enterprises scrape data from social networks, competitor websites, news sites, and blogs to learn about the industry. This scraped data is invaluable because it reveals the ins and outs of a particular field, which can be used to spot a lucrative investment opportunity or avoid a bad one.
Simultaneously, your business gets information on consumer behavior, competitor marketing strategies, market size, and regulatory changes, social media sentiment , and more. This is an all-encompassing approach to forging a marketing strategy that leaves no stone unturned and uses every bit of data to outperform the competition.
Lead Generation
The end goal of your marketing strategy is to attract potential buyers (leads). To achieve that, you must identify their needs. As a part of a broader market research strategy, lead generation focuses on identifying consumer needs and fulfilling them. Whether it’s an attractive ad, a smartly written social media post, or a useful blog article, scraped data provides insights into consumer cravings and hints at how to answer them.
Employee and Job Scraping
This type of scrapers is getting increasingly popular among Human Resource (HR) employees. Instead of spending countless hours going over application forms or LinkedIn profiles, HRs can use web scraping tools to look for specific skills and fetch only those CVs that are applicable to open positions.
Simultaneously, people seeking employment opportunities can scrape websites that post job opportunities. They can extract data like location, requirements, salary range, position description, and other relevant information. This data is gathered in XML format that Excel recognizes, which is a great tool to map out employment opportunities.
Benefits of Using No-code Web Scrapers
Even before the no-code web scrapers, web scraping was widely used, and scraping professionals were sought after. Big Tech brands like Google and Amazon scrape, although businesses rarely disclose such information. One way or another, data extraction benefits are undisputable, so let’s go over major ones for a more profound overview.
User-Friendly Interfaces
Extracting data without a no-code web scraper requires front-end coding language , which is used to code the visible side of websites. It includes HTML elements that form the very essence of the website - its content; CSS selectors that give the content form, color, and design; and JavaScript functions to make it dynamic and interactive.
You can inspect this code on Windows devices by clicking Ctrl+Shift+J to access developers’ tools and clicking on elements, as seen in the image below.
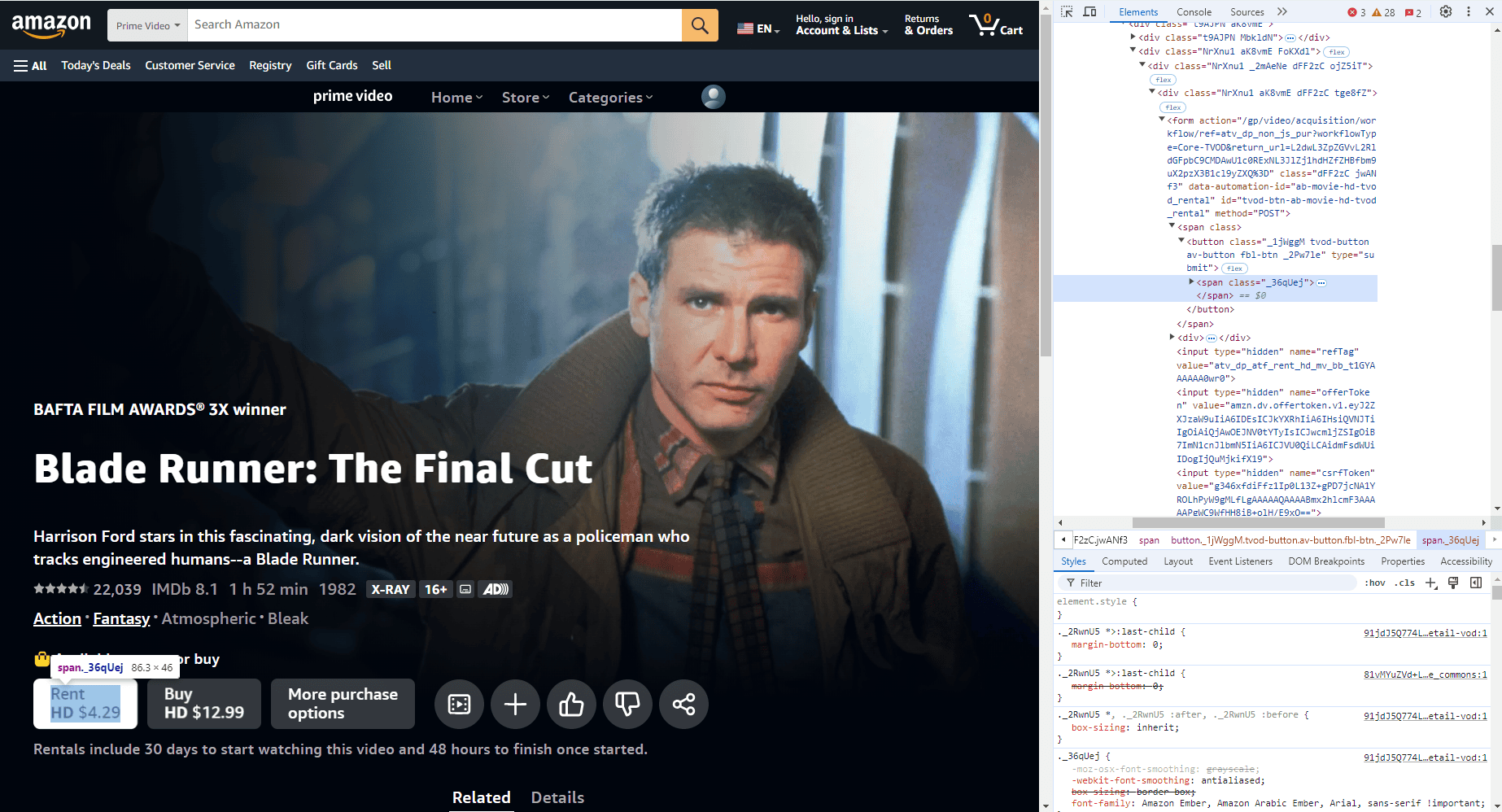
We’ve used an example from Amazon and selected the product’s rent price. In the code piece to the right, we can see that it is assigned a class and it is also a button. To scrape thousands of such examples, you’d need to write code that can identify these elements from the rest, whether by their class, action type, CSS selector, or other details. You can learn more about web scraping with JavaScript in our other dedicated blog post.
However, with a no-code web scraper, you don’t have to go through these complexities. You can simply click on an element, and the web scraper will do the rest for you. That is, it will learn how to identify a selected element , separate it from the rest, and repeat the action on whatever website you choose to scrape.
So, a user-friendly, intuitive interface is its main selling point. A point-and-click interface is similar to numerous other popular apps, so it takes little time to get used to. A marketing specialist without any coding know-how can quickly learn the mechanics of a no-code scraper and start using it for data extraction.
Cost Efficiency
A no-code scraper reduces costs in more than a few ways compared to traditional web scraping tools. Firstly, experienced programmers are among the highest-paid IT professionals. While it is definitely beneficial to have such specialists for complex, customizable, and scalable web scraping tasks, there’s no need to overpay for simpler ones. No-code web scraping lets you extract data without the need for these expensive professionals.
These tools are also cheaper to maintain and faster to deploy. It takes time to develop a built-in scraper, but you can start using a no-code scraper immediately after getting it. Furthermore, they often have routine (or similarly called) functions that you can reuse for multiple websites and error-handling features, which reduces the maintenance cost.
Lastly, these tools have lower error risks. There’s always a chance to make a mistake while writing code, and even the best programmers can make one. The no-code tools have already been tested for errors before being shipped out to consumers, so you get more accurate data to work with.
Versatility Across Different Platforms
Most scrapers that require no coding knowledge are web-based applications with browser extensions. Naturally, when you write code to develop an in-house scraper, you must write it separately for each operating system, like Windows, macOS, Linux, etc.
You can avoid this time-consuming hassle using no-code web scraping. Most of them already have cross-device compatibility and work on all major browsers. Furthermore, they can analyze websites with different structures. This versatility is essential for the successful coordination of various tasks, which is common during tense marketing campaigns.
Key Features of No-Code Web Scrapers
We’ve already discussed key features such as a user-friendly interface, the point-and-click interface to select elements, and compatibility with the most popular web browsers. However, there are a few more that illustrate these tools in a broader context.
Data export options (CSV, JSON, XML)
The best no-code scrapers extract data and return it in three formats: CSV (comma-separated values), JSON (JavaScript object notation), and XML (extensible markup language).
The CSV is a simplistic text format where commas separate all values. This format is compatible with Excel and numerous other text editors and databases. It is easy to read, so it’s perfectly compatible with no-code tools where the user may need more coding knowledge for more complex syntax.
The JSON uses key-value pairs to return data in a structured format. This format is the best for machine processing and compatible with many coding languages. JSON is often used in APIs and other web applications.
Lastly, the XML has attributes similar to both. It is relatively easy to read and well-optimized for machine processing. It represents data in a hierarchical structure and is highly customizable. It can be used for data storage, artificial intelligence, data exchange over the web, and more.
Automation Capabilities
Excellent automation capabilities are definitely one of the most vital web scraping aspects. After all, without automation, what would separate web scraping from manual data gathering? No-code scrapers offer automation features that allow you to relocate human resources elsewhere while maintaining continuous information inflow.
Firstly, you can schedule scraping tasks at chosen intervals to keep your data set updated. You can also target multiple websites to get more data at the same time, but you may need to deploy proxies to achieve that. If you want to learn more about using rotating proxy networks to maximize web scraping efficiency , we have a dedicated blog post on the topic.
Some no-code scrapers let you set event-based triggers to retrieve information only after a specific event happens. This way, you don’t have to keep an eye on your competitors or price changes in retail sites because the scraper takes care of that automatically. You can also combine it with an API to exchange data with other applications, so this technology streamlines multiple processes.
Integration With Other Tools and Services
Designed for simplicity, these scrapers easily integrate with other tools for further data analysis. You can import the data straight into Excel or Tableau to organize and visualize it; store the scraped data in MySQL, MongoDB, and other databases; use it with Node.js or React web development applications to create rich websites; integrate with email marketing tools to drive revenue or drive it to machine learning platforms for algorithm training.
Popular No-Code Web Scraping Tools
Now that we’ve got the benefits and use cases all figured out, let’s take a closer look at the most popular no-code scrapers. Below are three beginner worthwhile options that will kickstart your web scraping right after installing them.
Octoparse
Octoparse is a popular and user-friendly no-code scraper that is versatile and easy to master. It lets you try it out for free and has a helpful walkthrough for beginners that teaches how to insert backlinks and select elements to scrape data. This tool is compatible with so many platforms that it’s futile to list them all out, but take a look at the picture below to get the hang of it.
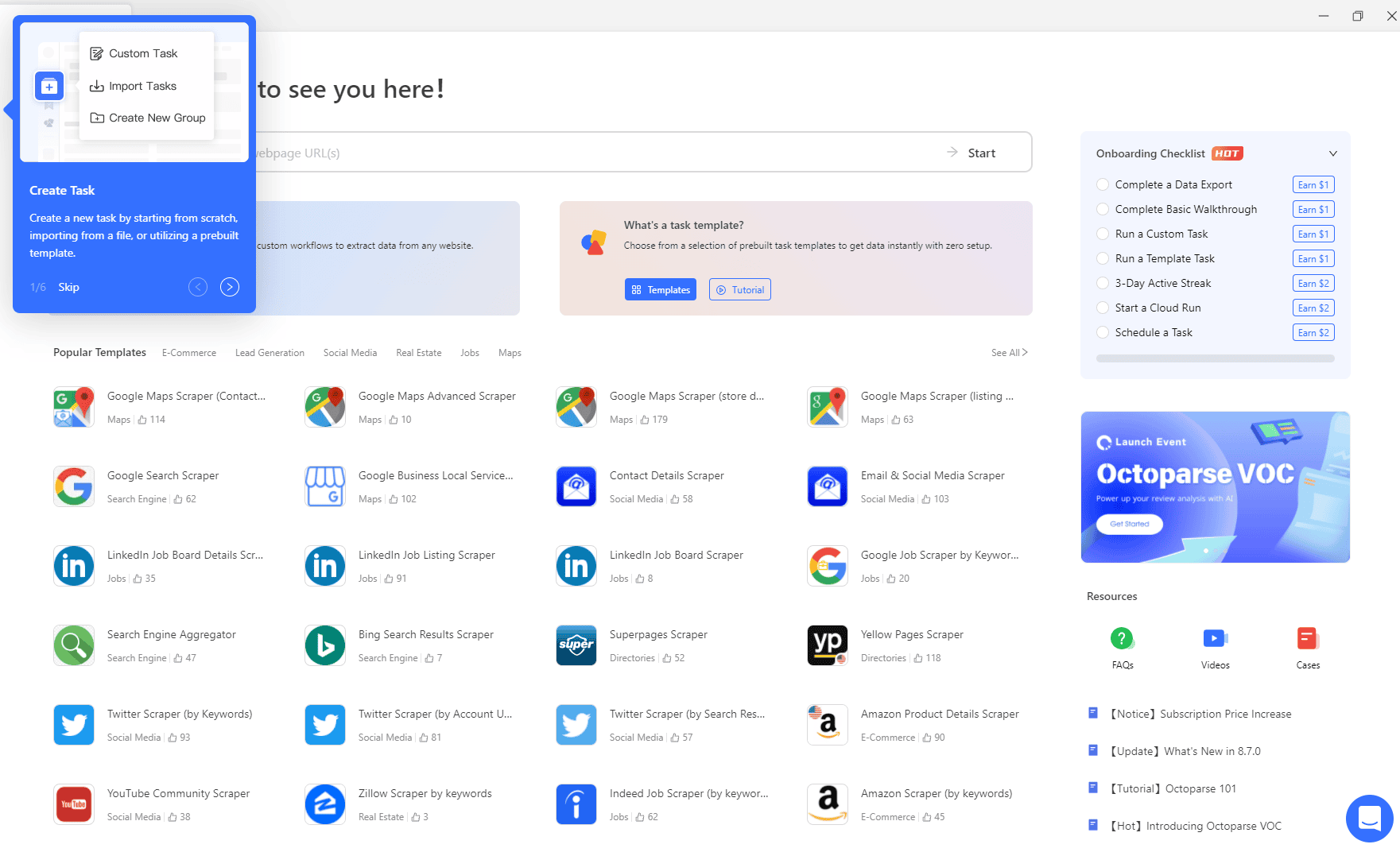
You can install Octoparse on your device or use it as a cloud-based tool. The point-and-click interface is coupled with AI-powered element detection , increasing data-gathering accuracy. Octoparse provides pre-built templates, so you can start scraping before you master the tool to create your own.
Overall, it’s a powerful web scraper for starters, which gets even better once you get more experience and familiarize yourself with its many features. There’s a free plan limited to 10 tasks and 10k data rows per export, and the Standard plan costs $99/month.
ParseHub
Some online data is widely accessible and available for scraping. Meanwhile, other websites have anti-scraping protection mechanisms to prevent competitors from gaining insight into their business strategy. In this case, you need a web scraper that can bypass these restrictions.
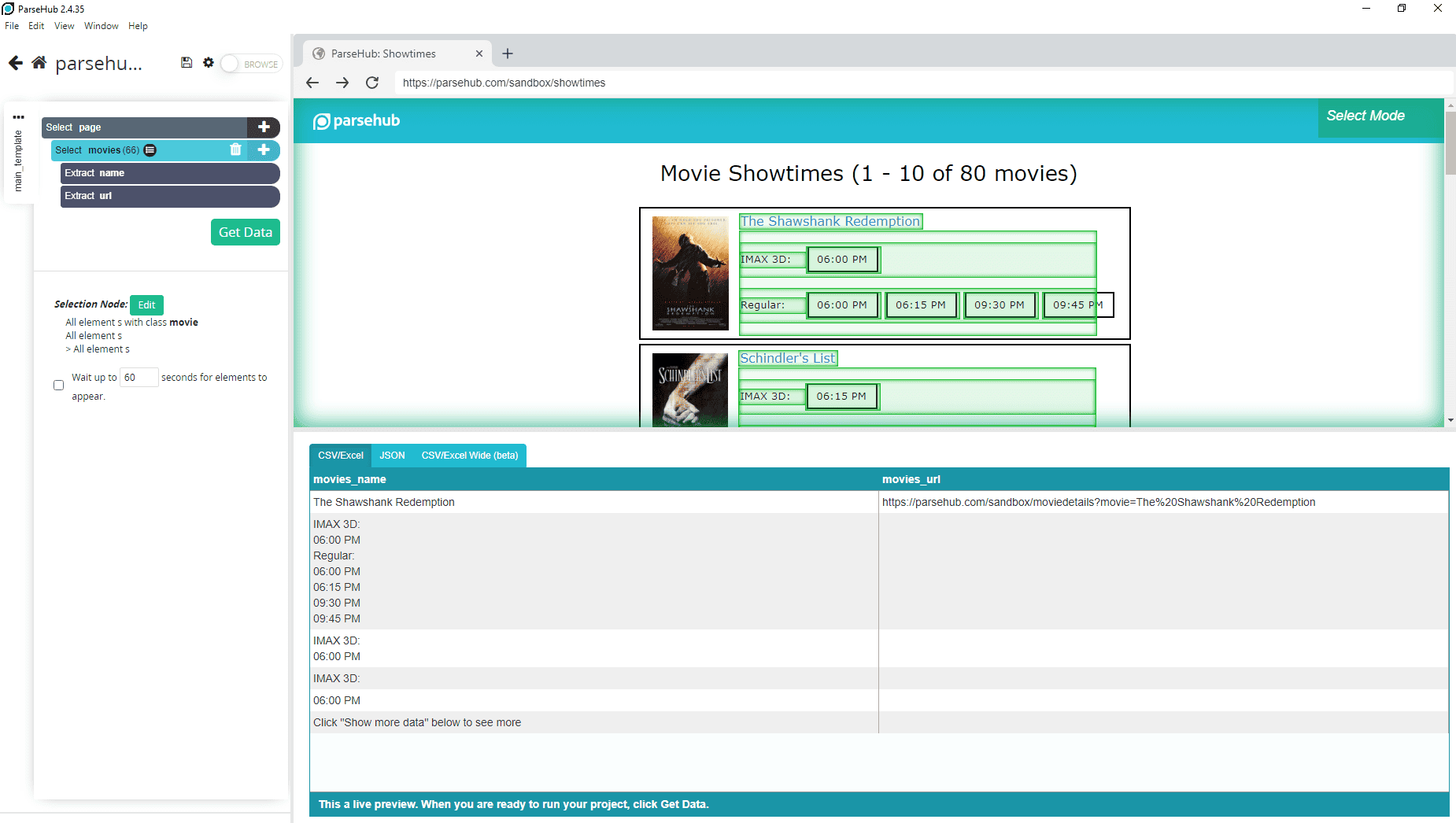
ParseHub is a great web scraping tool with a neat visual interface, cloud storage, browser extensions, and other features mandatory for a no-code solution. However, it outperforms others in one crucial aspect. It allows simulating user interaction, like clicking buttons and filling forms , which makes it highly efficient for scraping dynamic websites. Selecting elements is effortless, as seen in the image below, where we are grabbing movie names and runtime.
You can try ParseHub for free, limited to 200 pages, and the standard plan expands it to 10,000 pages per run with better scraping speed, costing $189/month.
Import.io
Import.io is suitable for more advanced users looking for a scraper to work with large datasets. The tool offers automatic data conversion and excellent data enrichment features so that you fill the gaps in your existing datasets with new information. There’s also a data validation option to check for errors and increase web scraping accuracy.
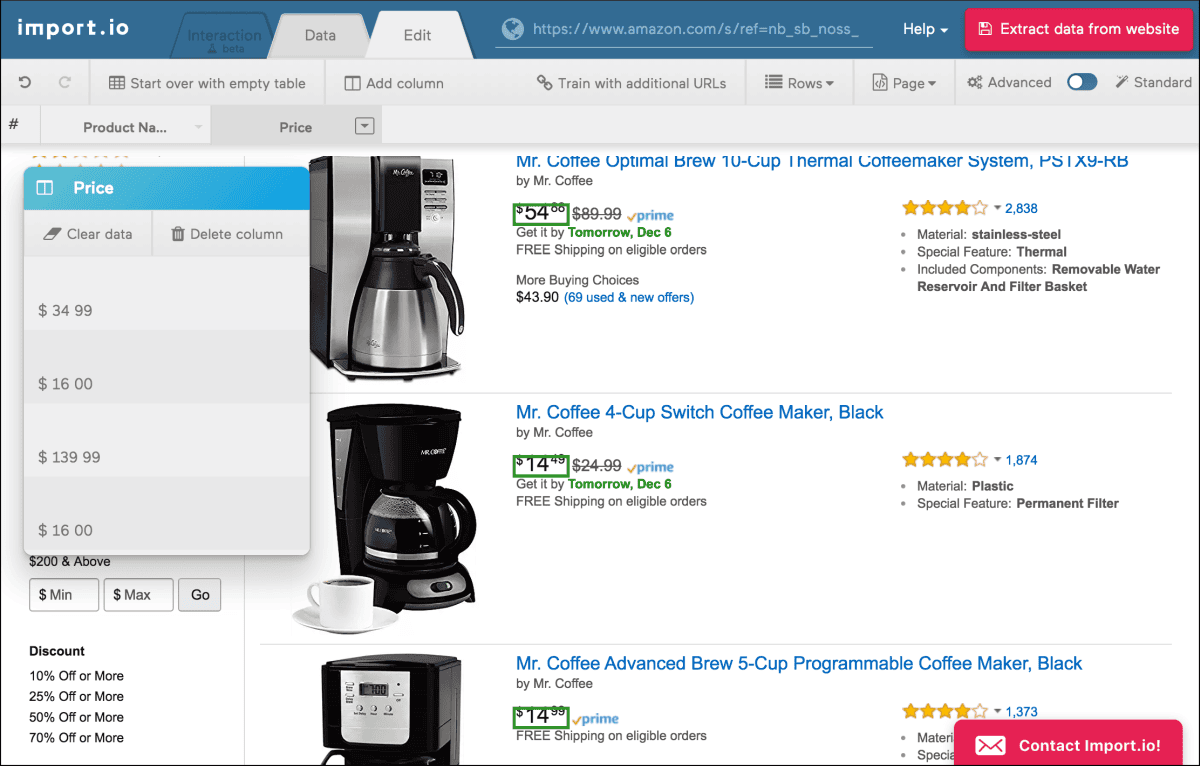
However, this tool has fewer support resources. We recommend it for more experienced users who are already familiar with web scraping and can make the most out of its advanced features. It also asks for a professional price, starting at $399/month.
How to Use a No-code Web Scraper?
We have listed 3 popular web scraping tools, but there are many more to choose from. In the end, it boils down to your needs, as comparing prices or gathering intelligence for AI training are significantly different tasks. Here are a few tips on how to pick a suitable no-code scraper for your needs.
Choosing the Right Tool
Firstly, identify your goals. Inspect the website to determine whether you need a scraper that simulates user behavior or has better scalability options to grab more data. Determine whether you need AI-powered element detection or a more customizable scraper and go through online reviews and their official websites for a final decision.
Selecting the Data to Scrape
Once you have chosen a tool and set up your account, start your project by selecting the data to scrape. Most no-code solutions offer an interface to input backlinks and display the website to select elements. You can specify the criteria by which to identify and grab elements, like a CSS selector or an attribute, and create custom rules if you already have some experience with web scraping.
Running the Scraper and Retrieving Data
Now it’s time to start scraping! Verify that you have input all backlinks that have the required data , and keep an eye out for any error messages. Afterward, select the format (CSV, JSON, XML) that you should get results in. Lastly, go through data validation if your tool offers this feature to make sure everything is accurate and ready for the next step.
Tips for Optimizing the Scraping Process
Here are a few tips to ensure you make the most out of your web scraping tool. Firstly, it’s highly advisable to narrow down data scraping to the required minimum. Gathering excessive amounts of data not only slows down the process, it makes it more expensive, and can even cause legal trouble if it includes personally identifiable information.
We also recommend taking a deeper look into proxies to streamline web scraping. Some websites implement CAPTCHAs or issue IP bans whenever they notice multiple data requests coming from the same IP address. Even though their data is publicly available, you may need help gathering it for your business needs.
Lastly, proxies may be insufficient when dealing with challenging anti-scraping algorithms. You may need to obfuscate your data request headers using an anti-detect browser or even a virtual machine. Drop by our virtual machines vs anti-detect browsers comparison to learn more about each technology.
Practical Applications and Examples
What better way to illustrate the benefits of no-code scrapers than with concrete, practical applications and examples? Let’s overview several fields that greatly benefit from online data gathering.
Scraping E-commerce Product Data
Businesses widely utilize web scraping to gain valuable insights into their industries. From the discussed price comparison to market research to consumer sentiment analysis and inventory tracking , it’s a great tool to automate information gathering. Scraping e-commerce data is often used by huge retail enterprises like eBay and Walmart.
Gathering Social Media Insights
Social media is an astounding conversion channel when done right. With over 5 billion users worldwide , it can skyrocket your sales if you grab people’s attention. But that’s easier said than done. Social networks like Facebook and Reddit are overflowing with content and ads, which makes it hard to stand out. You can scrape publicly available social network data to inspect competitor strategies or analyze consumer sentiment and then adapt your marketing strategy to it. Do it before you pay for advertising time to increase the CTR and likelihood of a purchase.
Monitoring Competitor Websites
Monitoring competitors is important in several ways. Firstly, it helps you set the prices accordingly. Not too high to drive away the buyers, and not too low to maintain good revenue. Simultaneously, scraping competitors’ data reveals their marketing strategies and success stories , which you can learn from. Lastly, it alerts you of new product releases so that you know what you’re up against and can upgrade your service accordingly.
Last Words
By now, the benefits of a no-code scraper should be clear. But it is just as important to avoid common mistakes. Firstly, ensure that your data gathering is ethical and legal. Since Cambridge Analytica misused data scraping in the worst possible way, it is paramount to follow the best web scraping practices.
You should also pay close attention to data accuracy and quality. Using incorrect information will result in a flawed marketing strategy, and if you misinform readers, you will suffer reputation damage. Don’t forget about the security side of things, and keep your scraper updated at all times. It guarantees the vulnerabilities are patched up and also improves data extraction capabilities.

