Pandas read_html: Extracting Data From HTML Tables With Python
Tutorials

Eugenijus Denisov
Pandas is a popular Python data analysis library for a good reason – it has plenty of useful commands and methods. One of them is “read_html”, which lets you transform any URL with an HTML table into a data frame object.
Usually, to get data from a web page, you’d need libraries like Requests to scrape the information. You can bypass all of that with Pandas by using it to read HTML tables directly from a website.
Getting Started With Pandas read_html
As with all external libraries, you’ll need to install Pandas first. Read_html also requires a parser . While Pandas uses lxml as a default, we’ll also need BeautifulSoup and HTML5lib for more complicated HTMLs.
To install both, use “pip” and the Terminal in your IDE to run the command:
pip install pandas lxml html5lib bs4
Once installed, import the libraries and find a suitable URL. We’ll be using Wikipedia throughout the article as the website has a lot of nicely formatted HTML tables.
import pandas as pd
# URL of the Wikipedia page
url = 'https://en.wikipedia.org/wiki/List_of_countries_by_GDP_(nominal)'
# Parse the HTML at the URL and create DataFrames
tables = pd.read_html(url)
# Check the number of tables found
print(f"Total tables found: {len(tables)}")
# Assuming we want the first table, which usually contains the main data
gdp_table = tables[0]
# Display the first few rows of the DataFrame
print(gdp_table.head())
When executing the code, it will note that it found 7 tables. Wikipedia has a lot of them by default, such as the information box, external links, and some other descriptive features that are often coded as tables.
Basic Usage of Pandas read_html()
One of the most important features will be finding the correct HTML table for your data analysis needs. As mentioned above, a single web page can have several tables.
It’s often easiest to use the parameter “match=” in read_html() to find your table. We’ll be finding the “GDP (USD millions) by country” table.
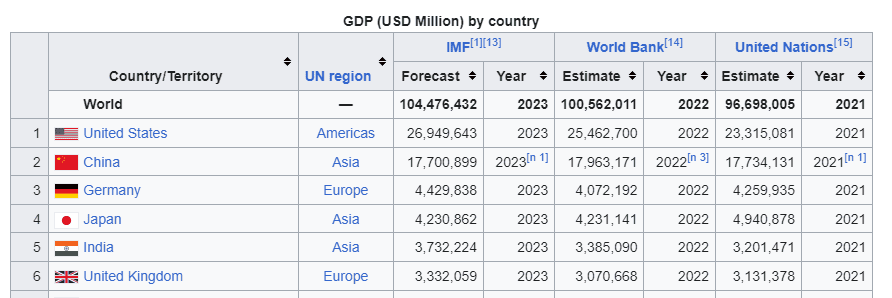
The “match=” accepts strings, so it’s often easiest to find the header of the table and add it to the parameter argument. It also accepts regular expressions if you prefer to use them.
import pandas as pd
# URL of the Wikipedia page
url = 'https://en.wikipedia.org/wiki/List_of_countries_by_GDP_(nominal)'
# Parse the HTML at the URL and create DataFrames
tables = pd.read_html(url, match="GDP \(USD Million\) by country")
While you can pass a string, it’s converted into a regular expression along the way due to compatibility between lxml and BeautifulSoup4. Our table has parentheses, which are special characters in RegEx, so we need to add backslashes.
We can now execute our new code:
import pandas as pd
# URL of the Wikipedia page
url = 'https://en.wikipedia.org/wiki/List_of_countries_by_GDP_(nominal)'
# Parse the HTML at the URL and create DataFrames
tables = pd.read_html(url, match="GDP \(USD Million\) by country")
# Check the number of tables found
print(f"Total tables found: {len(tables)}")
# Assuming we want the first table, which usually contains the main data
gdp_table = tables[0]
# Display the first few rows of the DataFrame
print(gdp_table.head())
Your output should now state that only one table was found.
Performing Data Cleanup With Pandas read_html()
Most of the time, HTML tables won’t be perfect for data analysis right off the bat. You’ll need to perform some cleanup first.
It’s also often a good idea to convert the table into a dataframe as it makes most of the next steps easier. Let’s add these lines at the end:
df_GDP = gdp_table
df_GDP.info()
Executing the code will show that our table has Wikipedia reference numbers within the columns. Additionally, some of the table data columns are tuples instead of strings.
Let’s clean up both:
import pandas as pd
import re
# URL of the Wikipedia page
url = 'https://en.wikipedia.org/wiki/List_of_countries_by_GDP_(nominal)'
# Parse the HTML at the URL and create DataFrames
tables = pd.read_html(url, match="GDP \(USD Million\) by country")
# Check the number of tables found
print(f"Total tables found: {len(tables)}")
# Assuming we want the first table, which usually contains the main data
gdp_table = tables[0]
# Function to clean column names by removing square brackets and any digits within them
def clean_column_names(column_name):
# Convert tuple to string if it's a MultiIndex
if isinstance(column_name, tuple):
column_name = ' '.join(column_name)
# Regex to remove square brackets and references within them
return re.sub(r'\[\d+\]', '', column_name)
# Apply the cleaning function to each column name in the DataFrame
gdp_table.columns = [clean_column_names(col) for col in gdp_table.columns]
# Store the cleaned DataFrame
df_GDP = gdp_table
# Display the first few rows of the cleaned DataFrame
print(df_GDP.head())
# Show the DataFrame info to check the new column names and data types
df_GDP.info()
We added a new function for cleaning up the column names, which will do both of our tasks. Once our code has read HTML tables, we’ll open with a function that checks if a column name is a tuple.
If it’s a tuple, the table name is joined into a string.
It’ll then return a new table with all of the column names in strings. Additionally, in the return, we use a regex function to remove the square brackets and reference numbers within them.
We then call the function that takes our table and runs a for loop for each column name in the table. Running the code should return a clean data frame.
You may notice, however, that all of the values in our data frame are referred to as “object”. These are usually reserved for something that’s a mix of numbers and letters or strings. Performing data analysis on such values is likely to be difficult.
We can use “pd.to_numeric” to convert all of these object values into numeric values. There are, however, three data types in our data frame:
- Years (integers)
- Regions (strings)
- Forecasts and estimates (floats)
Regions can be left as they are, since “objects” are a catch-all data type that’s treated as a string by default.
Here’s how we can convert the rest of the data:
# Convert columns that should be numeric
numeric_columns = ['IMF Forecast', 'World Bank Estimate', 'United Nations Estimate']
for column in numeric_columns:
df_GDP[column] = pd.to_numeric(df_GDP[column], errors='coerce')
# Optionally, convert 'Year' columns to integers, if they are fully numeric
year_columns = ['IMF Year', 'World Bank Year', 'United Nations Year']
for column in year_columns:
df_GDP[column] = pd.to_numeric(df_GDP[column], errors='coerce').astype('Int64') # Use 'Int64' to allow NaN values
# Display the info to check new data types and the first few rows to inspect the data
df_GDP.info()
First, we have to look at our converted column names as performed in the previous section. We’ll then define two lists, one for integer (year) columns and the other for float (numeric) columns.
We’ll then run two “for” loops that’ll take the column names and convert them to numeric values. In case we run into something unusual, “errors=coerce” parameter will convert these values to NaN (Not a Number).
Additionally, we have to force a specific integer type with “.astype(‘Int64’)”. NaN is technically a floating point number (even if the name says otherwise), and regular integers used by Pandas do not support NaN.
Running the code should now provide us with a dataframe object with several data types, each assigned properly.
Full Code Snippet
import pandas as pd
import re
# URL of the Wikipedia page
url = 'https://en.wikipedia.org/wiki/List_of_countries_by_GDP_(nominal)'
# Parse the HTML at the URL and create DataFrames
tables = pd.read_html(url, match="GDP \(USD Million\) by country")
# Check the number of tables found
print(f"Total tables found: {len(tables)}")
# Assuming we want the first table, which usually contains the main data
gdp_table = tables[0]
# Function to clean column names by removing square brackets and any digits within them
def clean_column_names(column_name):
# Convert tuple to string if it's a MultiIndex
if isinstance(column_name, tuple):
column_name = ' '.join(column_name)
# Regex to remove square brackets and digits within them
return re.sub(r'\[\d+\]', '', column_name)
# Apply the cleaning function to each column name in the DataFrame
gdp_table.columns = [clean_column_names(col) for col in gdp_table.columns]
# Store the cleaned DataFrame
df_GDP = gdp_table
# Convert columns that should be numeric
numeric_columns = ['IMF Forecast', 'World Bank Estimate', 'United Nations Estimate']
for column in numeric_columns:
df_GDP[column] = pd.to_numeric(df_GDP[column], errors='coerce')
# Optionally, convert 'Year' columns to integers, if they are fully numeric
year_columns = ['IMF Year', 'World Bank Year', 'United Nations Year']
for column in year_columns:
df_GDP[column] = pd.to_numeric(df_GDP[column], errors='coerce').astype('Int64') # Use 'Int64' to allow NaN values
# Display the first few rows of the cleaned DataFrame
print(df_GDP.head())
# Show the DataFrame info to check the new column names and data types
df_GDP.info()

