'/%3e%3cellipse%20opacity='0.34'%20cx='327.5'%20cy='339'%20rx='264.5'%20ry='264'%20fill='url(%23paint1_linear_12724_35442)'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_12724_35442'%20x1='327'%20y1='-2.524e-06'%20x2='327'%20y2='389.286'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%2327D9E5'/%3e%3cstop%20offset='0.927406'%20stop-color='%23004047'%20stop-opacity='0'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_12724_35442'%20x1='328.02'%20y1='74.7771'%20x2='328.02'%20y2='395.312'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%2327D9E5'/%3e%3cstop%20offset='0.927406'%20stop-color='%23004047'%20stop-opacity='0'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)
Aside from performance, access is just as important when it comes to large-scale data extraction. Crawl4AI provides the framework to scrape and prepare data for AI workflows. It's easy to use and scale without reinventing web scraping.
However, proxies are still necessary to prevent running into obstacles such as IP bans, geo-restrictions, or request throttling. Together, they form a seamless setup for those who need innovative and resilient data pipelines.
In this integration tutorial, we'll explain how to integrate your IPRoyal proxies directly into Crawl4AI.
What Is Crawl4AI?
Crawl4AI is an open-source web scraping framework developed with AI in mind. Unlike "classic" scrapers, it transforms web pages into clean content that's ready for analysis by humans and AI. This approach makes it suitable for tasks such as:
- retrieval-augmented generation (RAG)
- training datasets preparation
- powering intelligent agents with real-time web content.
Here's a brief overview of its key features:
1. AI-optimized content gathering
Crawl4AI outputs data in Markdown format, preserving the structure (lists, headings, code blocks) while removing clutter. This ensures that the gathered data is ready for LLMs or indexing systems without heavy parsing.
2. Asynchronous crawling
This framework is built on an asynchronous architecture focused on performance. Crawl4AI can handle multiple tasks at once, so it’s suitable for large-scale projects where speed is crucial.
3. Flexible extraction strategies
From traditional CSS and XPath selectors to regex patterns and beyond, Crawl4AI offers multiple approaches to gathering structured data. It’s a great option for a wide range of use cases, from grabbing specific data points to summarizing dynamic content.
How to Set Up Crawl4AI With IPRoyal Proxies
Step 1: Install Crawl4AI
To get started, make sure you have Python installed. Namely, version 3.9 or newer. Once you do, install Crawl4AI and the necessary components:
pip install -U crawl4ai
Next, run the post-installation setup. It will take some time, as it’s necessary to install Playwright and the headless browsers you will use:
crawl4ai-setup
Step 2: Perform a Test Crawl
Before we configure proxies, it’s a good idea to perform a basic test crawl and ensure everything is working.
python
import asyncio
from crawl4ai import AsyncWebCrawler
async def main():
async with AsyncWebCrawler() as crawler:
result = await crawler.arun(url="https://iproyal.com")
print(result.markdown)
asyncio.run(main())
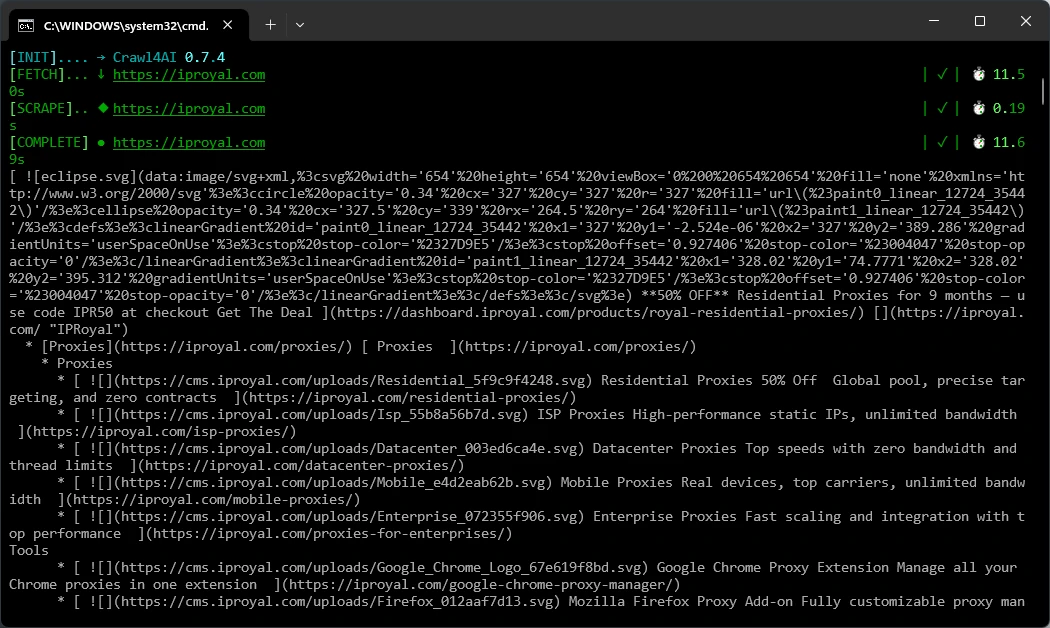
This code will fetch the IPRoyal homepage and print out a Markdown version of it.
Step 3: Add Your Proxy Settings
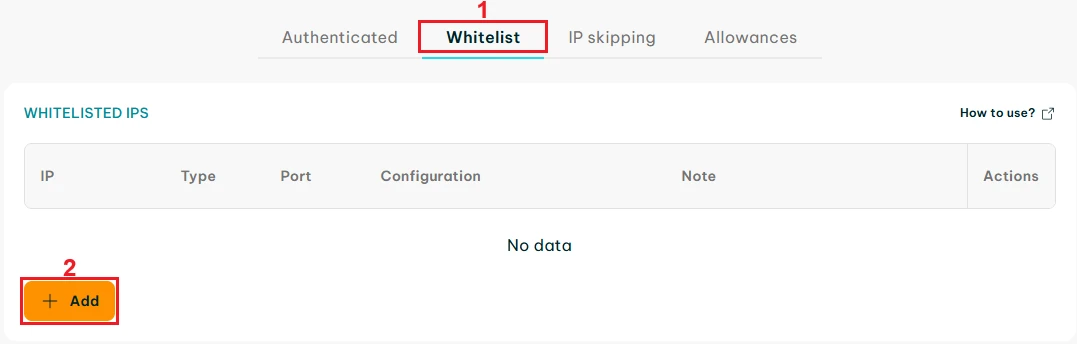
Visit the IPRoyal dashboard to configure your proxies. To avoid errors related to Crawl4AI’s proxy credential interpretation, we’ll start by whitelisting our IP address. Switch from ‘Authenticated’ to ‘Whitelist’ (1) and click the ‘Add’ (2) button.
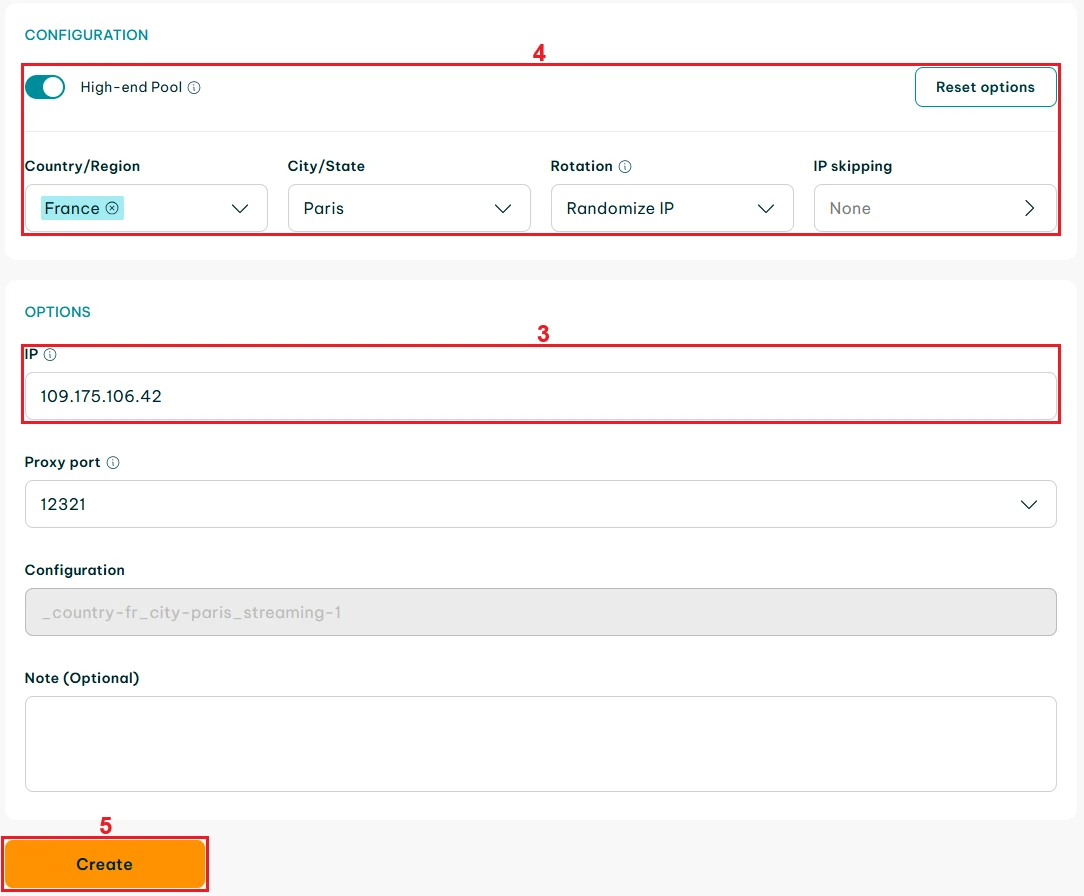
Visit our IP Lookup page to check your IP address and enter it in the ‘IP’ (3) field. Configure your proxies - we’ll use randomized high-end Residential Proxies from Paris, France (4). Click the ‘Create’ (5) button when done.
By whitelisting your IP address, you don’t need to provide a username and password. To add proxies to our project:
python
import asyncio
from crawl4ai import AsyncWebCrawler, BrowserConfig
# Use your whitelisted proxy without username/password
proxy = "http://geo.iproyal.com:12321"
config = BrowserConfig(
browser_type="chromium",
headless=True,
proxy=proxy # No authentication needed
)
async def main():
async with AsyncWebCrawler(config=config) as crawler:
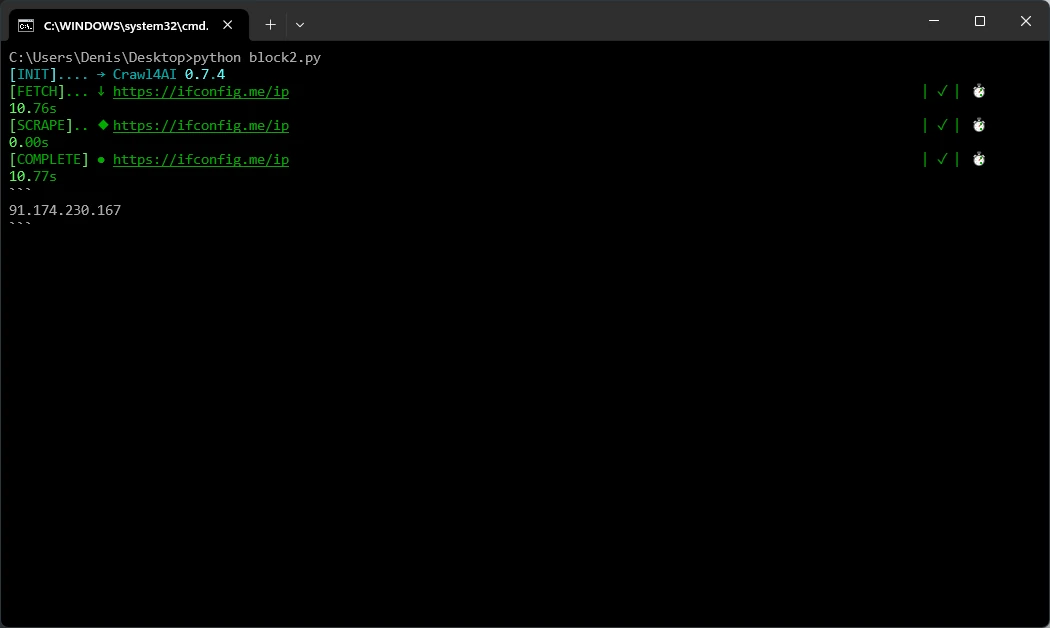
result = await crawler.arun(url="https://ifconfig.me/ip")
print(result.markdown) # Should show the proxy's IP
asyncio.run(main())
This example uses a website request to confirm that your proxy is working. If the returned IP address matches your proxy (instead of your local machine), you’re ready to start scraping.
Step 4: Using Multiple Proxies (Optional)
The configuration above is sufficient for any task, regardless of scale. Still, you may want to use your own proxy list and rotate through it. Here’s how to do it:
python
import asyncio
import random
from crawl4ai import AsyncWebCrawler, BrowserConfig
# List of whitelisted proxies (no authentication needed)
proxies = [
"http://89.185.23.71:12323",
"http://109.110.174.245:12323",
"http://2.58.235.82:12323",
"http://89.116.242.123:12323",
"http://5.181.184.56:12323",
]
async def fetch_with_proxy(proxy_url, url, retries=3):
"""Fetch a URL using a given proxy, retrying if it fails."""
for attempt in range(1, retries + 1):
try:
config = BrowserConfig(proxy=proxy_url)
async with AsyncWebCrawler(config=config) as crawler:
result = await crawler.arun(url=url)
print(f"Success with proxy {proxy_url} on attempt {attempt}")
return result.markdown
except Exception as e:
print(f"Attempt {attempt} failed with proxy {proxy_url}: {e}")
print(f"All {retries} attempts failed for proxy {proxy_url}")
return None
async def main():
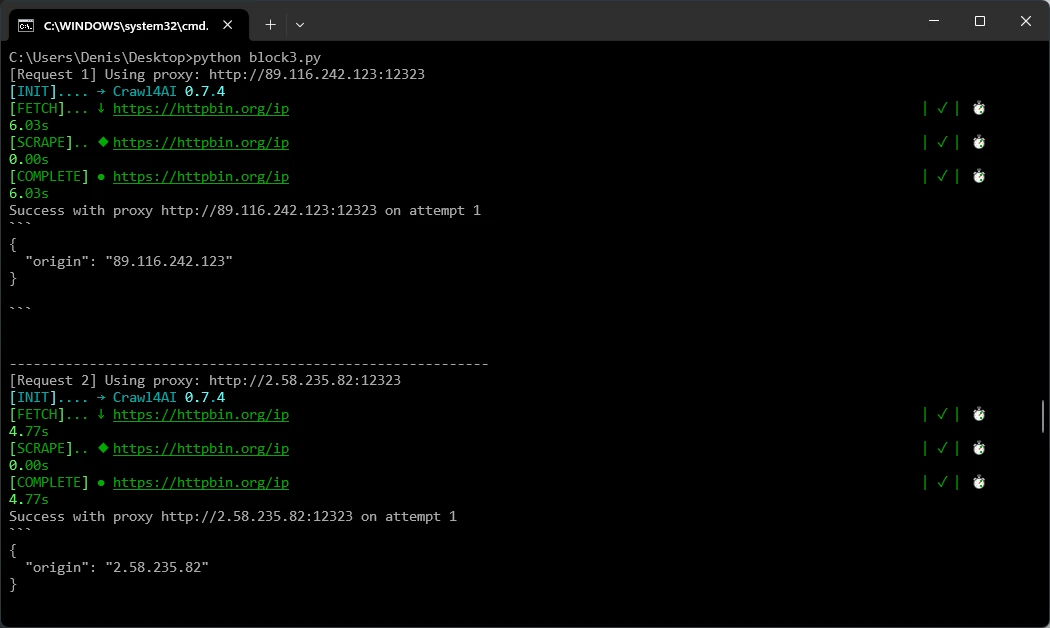
url_to_fetch = "https://httpbin.org/ip"
num_requests = 10 # Total number of requests
available_proxies = proxies.copy()
for i in range(num_requests):
if not available_proxies:
# Reset list once all proxies have been used
available_proxies = proxies.copy()
# Randomly select a proxy and remove it from the list
proxy_url = random.choice(available_proxies)
available_proxies.remove(proxy_url)
print(f"[Request {i+1}] Using proxy: {proxy_url}")
result = await fetch_with_proxy(proxy_url, url_to_fetch)
if result:
print(result)
print("-" * 60)
asyncio.run(main())
We’re using five Datacenter Proxies with random rotation, multiple requests, and automatic retries. Each proxy is used once before the list resets, with up to three attempts per IP if a request fails.
Troubleshooting Tips
- ERR_INVALID_AUTH_CREDENTIALS - Using username/password authentication with the current version of Crawl4AI (0.7.4) will often result in this error. Set up whitelisting to solve this issue. If you must use proxy authentication, encode special characters in the username and password with urlib.parse.quote.
- Chromium fails to launch - It’s possible that your firewall/antivirus software will block Chromium. Run crawl4ai-setup again to make sure all browsers are installed. If the issue persists, disable your firewall/antivirus software or make sure Chromium is allowed in the settings.
Why Use IPRoyal as Your Crawl4AI Proxy Provider?
All web scraping efforts end, usually sooner rather than later, when performed from a single IP address. Most modern websites use strict protection mechanisms to prevent automated scraping. As a result, your IP address quickly gets flagged, blocked, or banned, often even before you gather any data.
- Avoiding IP-based restrictions. By routing Crawl4AI through a robust IP pool such as IPRoyal’s Residential Proxies, you can distribute your requests across multiple IPs. This approach reduces the risk of detection, ensuring uninterrupted scraping.
- Overcoming geo-restrictions. A lot of digital content is locked to specific locations. Using proxies, you can assign IPs from targeted regions (down to the city or even ISP), which allows Crawl4AI to access region-specific data as needed. This flexibility makes acquiring geographically limited content straightforward and efficient.
- Scaling seamlessly. Proxies also enable you to handle multiple sessions at once, minimizing the risk of unexpected network interruptions or access restrictions. In short, they provide the backbone for stable, scalable web scraping operations. This way, you can scale Crawl4AI effectively, without a negative impact on the quality of your data.
Here’s what makes IPRoyal’s network an excellent option for any scraper:
- Over 32 million authentic residential IP addresses worldwide
- Granular geo-targeting (country, state, city, and ISP level)
- Pay-as-you-go and subscription-based pricing options
- Non-expiring residential traffic with bulk discounts of up to 75%
- 99.99% uptime, API integration & 24/7 expert support
Final Thoughts
With Crawl4AI’s intelligent crawling approach and IPRoyal’s proxy infrastructure, you can build a data extraction pipeline that’s resistant to all common scraping challenges. Whether you’re working on datasets for AI training, market research, or automation, this combination ensures you can shift your focus from acquiring data to utilizing it.
