Amazon Product Data Scraping With Proxies: A Beginner's Guide
Tutorials

John Watson Rooney
Here at IPRoyal, we’re always excited to work with industry experts and established professionals. This week, we welcome our friend John Watson Rooney , a reputable Python expert and YouTuber. In this in-depth guide, he’ll share his knowledge about scraping Amazon product data at scale and protecting your setup with proxies.
Let’s see what John has to teach us!
The Most Common Web Scraping Issue
One of, if not the, hardest part of web scraping is scaling. Taking the simple yet effective code you have written and making it work over thousands and thousands of requests.
The topic of scaling itself is vast, and usually, the first sticking point is, “How do I avoid being IP banned?”
Fortunately, there is a simple solution. I always point people towards this, and it’s also one of the easiest things to implement and one of the most effective: proxies.
Why Are Proxies Essential for Effective Amazon Product Data Scraping
A proxy sits between you and the website, taking your requests and forwarding them, collecting the response, and sending it back. This functionality allows us to push the number of requests we can send in a short time to a website. It’s a cost-effective solution to the scaling problem.
Where to Start?
Let’s take a look at an example.
Why would you want to perform Amazon product data scraping? To see your competitors’ prices and what they are selling. For that, we look towards Amazon and see we can easily grab bits of data with a few lines of code.
First, let’s import the packages we need. I am going to use Python . However, proxies are language agnostic. Pip install anything you need.
# we are going to use requests and bs4
import requests
from bs4 import BeautifulSoup
I will create a basic outline using functions as to what I want my code to do.
But first, we are going to create a session using requests. Using a session is the first important step that beginners miss. Having a session allows us to reuse the underlying TCP connection instead of having to create a new one each time. It speeds things up and allows us to add extra information, such as specific headers, to the session itself rather than to each individual request.
Where Do Proxies Come In?
We are going to add our proxies to the session too. This will allow us to put in the proxy information once and have it work for every request we subsequently make. It’s the easiest way to add in your proxies . IPRoyal will provide you with a URL that contains your username, password, and port. This is your proxy.
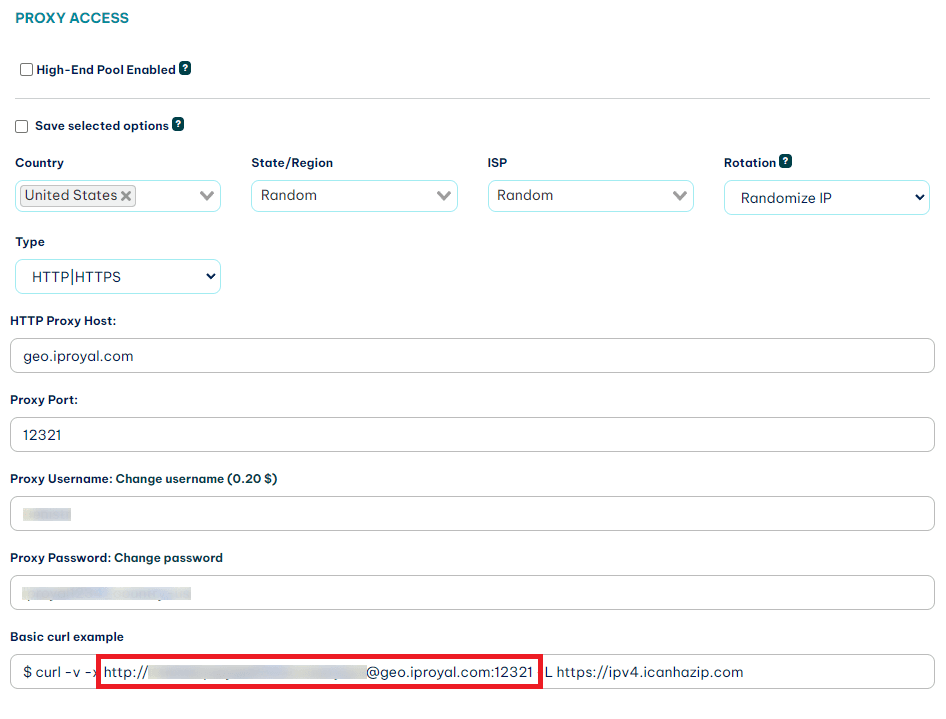
These proxies auto-rotate, too, so we only need to put this in once.
# Skeleton code, with the session in the main function.
import requests
from bs4 import BeautifulSoup
def csv_to_list():
pass
def make_request(client, asin):
pass
def parse_data(html):
pass
def main():
# Create our session and add the headers and proxy information
client = requests.Session()
client.headers.update(
{
"User-Agent": "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:109.0) Gecko/20100101 Firefox/109.0",
"Cookie": "i18n-prefs=USD;"
}
)
client.proxies.update(
{
"http": "http://username:[email protected]:12321",
}
)
print(client.headers, client.proxies)
if __name__ == "__main__":
main()
Note the headers for User-Agent and the Cookie. These are required. Otherwise, you may get your request rejected by Amazon. I have left a print statement in so you can see the headers and proxies being sent with each request.
What Are ASINs and Where to Get Them
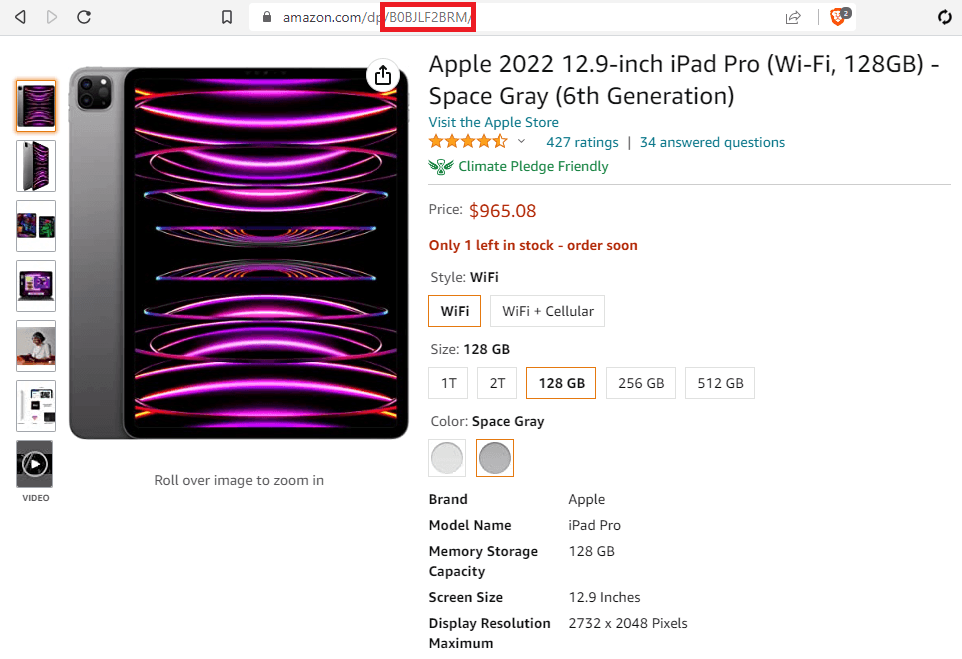
For this example, we are going to assume an external CSV file list of ASINs. This is Amazon’s own product identifier, and we can use it to manipulate the URL to get each piece of data. If you are following along, you can grab the ASIN from any product URL. They look like this “B0BJLF2BRM”.
Here’s the function to load the CSV file into Python, extract each ASIN, and create a Python list. Note the use of a context manager “with open”. This is important as it handles the correct closing of the file for us, avoiding issues.
# open the file “filename” and add each line to a list
def csv_to_list(filename):
lines = []
with open(filename, newline="") as f:
reader = csv.reader(f)
data = list(reader)
for line in data:
lines.append(line[0])
return lines
Our next function is for making the request. As we are using the session (we called it “client”), it will automatically use the headers and proxies we specified, so we need to pass that into the function, along with the ASIN, which is coming from our newly created list.
Then we return the response ready for our next function:
# make the request using the session, and return a tuple
def make_request(client, asin):
resp = client.get("https://www.amazon.com/dp/B07NM3RSRQ")
return (resp, asin)
I like to return a tuple here, so the response data is stored with the ASIN identifier that was used for the URL it came from.
We parse out the data we need using CSS selectors and store it in a Python dictionary. It’s up to you what data structure you use. I generally prefer dicts or tuples when working with databases. You can also use BS4’s selectors if you prefer, but my preference is CSS selectors due to their power and simplicity.
Let's return the item dict back from our function and move on to the final one, our main() function.
# create the soup object, then parse out the individual items using CSS selectors
def parse_data(response):
soup = BeautifulSoup(response[0].text, "lxml")
asin = response[1]
item = {
"store": "Amazon",
"asin": asin,
"name": soup.select_one("span#productTitle").text.strip()[:150],
"price": soup.select_one("span.a-offscreen").text,
}
return item
This is the “entry” point to our program and will run everything for us. I’ve already put the http session in here. Let's add the above functions in the correct order and run the code.
def main():
client = requests.Session()
client.headers.update(
{
"User-Agent": "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:109.0) Gecko/20100101 Firefox/109.0",
"Cookie": "i18n-prefs=GBP;"
}
)
client.proxies.update(
{
"http": "http://username:[email protected]:12321",
}
)
print(client.headers, client.proxies)
# testing it works with print statements and a test ASIN
data = make_request(client, "B09G9FPHY6")
print(data[0].text)
print(parse_data(data))
Don’t Forget to Test First
Using a single test ASIN, we can see we get the product information back. From here, we can create a loop to go through all our ASINs and start getting the data we are looking for.
asins = csv_to_list("asins-test.csv")
for asin in asins:
response = make_request(client, asin)
product_data = parse_data(response)
print(product_data)
Full Code
All that’s left is to share the full code. It’s a good base for you to explore Amazon product data scraping using proxies.
import requests
from bs4 import BeautifulSoup
import csv
def csv_to_list(filename):
lines = []
with open(filename, newline="") as f:
reader = csv.reader(f)
data = list(reader)
for line in data:
lines.append(line[0])
return lines
def make_request(client, asin):
resp = client.get("https://www.amazon.co.uk/dp/" + asin)
return (resp, asin)
def parse_data(response):
soup = BeautifulSoup(response[0].text, "lxml")
asin = response[1]
item = {
"store": "Amazon",
"asin": asin,
"name": soup.select_one("span#productTitle").text.strip()[:150],
"price": soup.select_one("span.a-offscreen").text,
}
return item
def main():
client = requests.Session()
client.headers.update(
{
"User-Agent": "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:109.0) Gecko/20100101 Firefox/109.0",
"Cookie": "i18n-prefs=GBP;"
}
)
client.proxies.update(
{
"http": "http://username:[email protected]:12321",
}
)
# print(client.headers, client.proxies)
asins = csv_to_list("asins-test.csv")
for asin in asins:
response = make_request(client, asin)
product_data = parse_data(response)
print(product_data)
if __name__ == "__main__":
main()
Final Thoughts
Introducing proxies to your web scrapers is a simple and effective way to help scale and avoid blocking. We are making use of our Residential IP proxies, which auto-rotate for us. This makes implementing them into new and existing projects very easy.

