Python Web Scraping: Step-By-Step Guide (2026)
Python

Justas Vitaitis
If you want to try out web scraping, there’s no better choice of a programming language than Python. Due to being an easy-to-use scripting language with excellent library support, it’s one of the most popular choices for web scraping in 2026.
In this article, you’ll learn how to use Python’s requests and Beautiful Soup libraries to scrape web pages. After reading this article, you’ll be able to determine the most mentioned programming languages on the r/programming subreddit by scraping and analyzing post titles.
What Is Web Scraping?
Web scraping is a technique of gathering data from a website. It’s usually done in an automated way through the use of bots, which are sometimes called scrapers or crawlers.
Most web scraping tools work by fetching the HTML code of a web page and finding the stuff you need. More advanced tools can also include a browser without GUI (headless browser) to simulate a real user.
Web scraping can be quite tricky and involves plenty of trial and error to get right. In addition, your scripts can easily be broken by changes in HTML/CSS. For this reason, web scraping should be used only when there isn’t an open API to get the data from.
But it’s a technique that you’ll be happy to know when the necessity arises. It’s frequently used to gather data for market research, financial analysis, price monitoring, and more.
Why Is Python the Best Language for Web Scraping?
Most programming languages have libraries that you can use for web scraping: all you need to get started is an HTTP client and a way to parse a website’s HTML.
But Python has an ecosystem like none other. You have access to the minimalistic Requests library for handling HTTP requests and Beautiful Soup , a handy library for parsing HTML. There are also more advanced tools like Scrappy and Playwright . All of these tools are battle-tested by many users, and there are plenty of tutorials available online.
In addition, Python is a simple language, which makes it great for writing and prototyping code even if you’re not a programmer by profession.
How to Do Python Web Scraping
This tutorial will show how to use web scraping to scrape the contents of a Reddit subreddit with Python. First, you’ll learn how to get all the title names of the first 500 posts of r/programming . Then, you’ll use the dataset to determine the most frequently mentioned programming language.
This tutorial will scrape the “old” UI of Reddit (accessible via old.reddit.com) since it’s easier to work with for beginners.
Setup
For this tutorial, you need to have Python installed on your computer. If you don’t have Python installed, you can download it from the official website .
You also need to install the requests and BeautifulSoup libraries with the following commands:
pip install requests
pip install bs4
Lastly, create a Python file called scraper.py where you’ll put the contents of your script.
Fetching HTML
Basic Python web scraping consists of two tasks: getting the HTML code of a page and finding the information you need.
To fetch the HTML code of the r/programming subreddit’s front page, you can use the Requests library.
import requests
It provides a function called requests.get() that takes a link to the page, connects to it, and returns the HTTP response.
Since Reddit (and many other sites) have rate limitations on popular bot client names (also called user agents), you should provide a unique name for your scraping application. You can do this by providing a header keyword argument to the requests.get() function.
page = requests.get("https://old.reddit.com/r/programming/",
headers={'User-agent': 'Sorry, learning Python!'})
You can access the code of the web page with the .content property.
html = page.content
This is the code you should have for now:
import requests
page = requests.get("https://old.reddit.com/r/programming/",
headers={'User-agent': 'Sorry, learning Python!'})
html = page.content
After you have fetched the page’s HTML code, you just need to find the titles inside it. To make it easier, you can use a parsing library like Beautiful Soup .
Parsing HTML
First, add an import statement for Beautiful Soup at the top of the file.
from bs4 import BeautifulSoup
Then, parse the html variable with Beautiful Soup’s "html.parser".
soup = BeautifulSoup(html, "html.parser")
This will return an object on which you can call methods such as find() and find_all() to search for specific HTML tags.
But which tags should you be searching for? You can find that out by using the inspect option available in browsers like Google Chrome.
It’s simple to use: open r/programming in incognito mode, find the element you want to scrape, then right click and choose Inspect.
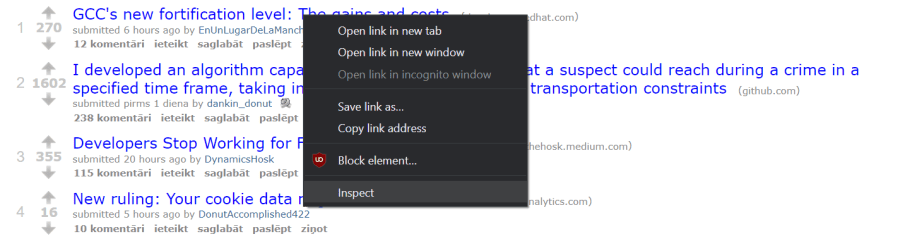
This will open the HTML document at the element you have selected.
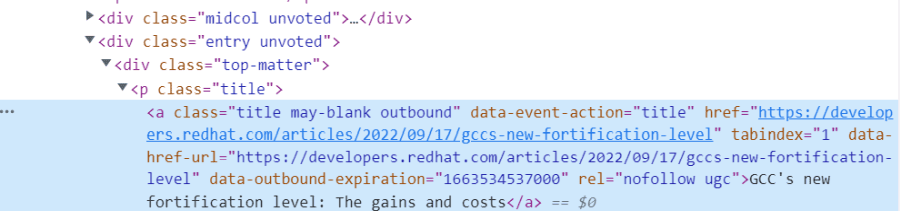
Now, you need to find a combination of HTML element tags and classes that uniquely identifies the elements you need.
In the case of the old Reddit’s UI, there’s a handy, unique class tag for the p tag surrounding titles: title.
You can use the find_all function with "p" and an additional "title" argument, which signifies that you’re searching for paragraph tags with the "title" class.
p_tags = soup.find_all("p", "title")
But this only gets you the paragraph tags, which contain a lot of unnecessary information. To get just the title text, you need to select the first anchor (<a>) tag and then extract the text out of it. You can do this via a list comprehension and the find and get_text functions:
titles = [p.find("a").get_text() for p in p_tags]
In the end, you can print out the result in the console.
print(titles)
This is the full code for now:
import requests
from bs4 import BeautifulSoup
page = requests.get("https://old.reddit.com/r/programming/",
headers={'User-agent': 'Sorry, learning Python!'})
html = page.content
soup = BeautifulSoup(html, "html.parser")
p_tags = soup.find_all("p", "title")
titles = [p.find("a").get_text() for p in p_tags]
print(titles)
It will print out the titles of the first page of the subreddit.
But if you want to gather a valuable dataset on what programmers are talking about right now, this will not be enough. In the next section, you’ll learn how to enable the scraper to scrape more than one page.
Scraping Multiple Pages
In this part, you’ll expand your script to scrape the first ten pages of the subreddit.
To scrape multiple pages, you need to find the link to the next page. Then you can load it, scrape it, find the link to the next page, and continue doing this until you have all the post titles you need.
In the old Reddit interface, the “next page” button has a span element with a next-button class. (You can find this out by inspecting the element.) So you can select this button by providing "span" and "next-button" arguments to soup.find().
After selecting the button, you can get the link by navigating to the anchor tag inside via .find("a") and accessing the contents of href.
next_page = soup.find("span", "next-button").find("a")['href']
To scrape more than one page, you’ll need to rewrite your code a little.
First, you need to import the time library. It provides a sleep function that will pause the scraper between page requests. This is necessary not to overload the server of the website you’re scraping and make the requests look more natural.
import time
After that, you’ll need to initialize two variables at the beginning of the file: post_titles and next_page. The first will hold all the titles the bot has scraped, and the second will hold the page it will scrape next.
post_titles = []
next_page = "https://old.reddit.com/r/programming/"
Then, you need to create a for loop that will run 20 times (to scrape 20 pages).
It will fetch the page to scrape from the next_page variable and scrape it exactly as the previous script did. After that, the loop will append the list of titles to post_titles, which we initialized at the beginning to the script. It will also find the link to the next page, store it in the next_page variable, and pause for 3 seconds.
for current_page in range(0, 20):
page = requests.get(next_page,
headers={'User-agent': 'Sorry, learning Python!'})
html = page.content
soup = BeautifulSoup(html, "html.parser")
p_tags = soup.find_all("p", "title")
titles = [p.find("a").get_text() for p in p_tags
post_titles += titles
next_page = soup.find("span", "next-button").find("a")['href']
time.sleep(3)
In the end, we can dump all the titles in the console to show that the script works successfully.
print(post_titles)
This is the full script:
import requests
from bs4 import BeautifulSoup
import time
post_titles = []
next_page = "https://old.reddit.com/r/programming/"
for current_page in range(0, 20):
page = requests.get("https://old.reddit.com/r/programming/",
headers={'User-agent': 'Sorry, learning Python!'})
html = page.content
soup = BeautifulSoup(html, "html.parser")
p_tags = soup.find_all("p", "title")
titles = [p.find("a").get_text() for p in p_tags]
post_titles += titles
next_page = soup.find("span", "next-button").find("a")['href']
time.sleep(3)
print(post_titles)
Finding the Most Talked About Programming Language
So how can you productively use this dataset?
One option is to query it for mentions of programming languages. In this way, you can determine the most talked-about programming language at the moment.
It’s quite simple. First, you need to create a counter dictionary with the programming language names you want to find. For this tutorial, the dictionary includes all programming languages from the Stack Overflow 2022 report used by at least 5% of developers.
language_counter = {
"javascript": 0,
"html": 0,
"css": 0,
"sql": 0,
"python": 0,
"typescript": 0,
"java": 0,
"c#": 0,
"c++": 0,
"php": 0,
"c": 0,
"powershell": 0,
"go": 0,
"rust": 0,
"kotlin": 0,
"dart": 0,
"ruby": 0,
}
After that, you must split the titles into words and convert them to lowercase. You can do this with a loop and a list comprehension.
words = []
for title in post_titles:
words += [word.lower() for word in title.split()]
Then, you can iterate over words and counter entries, incrementing the count of a programming language if it is mentioned.
for word in words:
for key in language_counter:
if word == key:
language_counter[key] += 1
In the end, print the results out in the console.
print(language_counter)
Here’s how the result of this script should look (the specific values will depend on the posts that are on Reddit at the moment of scraping).
$ python3 scraper.py
{'javascript': 20, 'html': 6, 'css': 10, 'sql': 0, 'python': 26, 'typescript': 1, 'java': 10, 'c#': 5, 'c++': 10, 'php': 1, 'c': 10, 'powershell': 0, 'go': 5, 'rust': 7, 'kotlin': 3, 'dart': 0, 'ruby': 1}
Python Web Scraping with Proxies
For serious web scraping activities, it’s recommended to use a proxy server, which is a server that acts as an intermediary between you and the website.
This is because many web page owners don’t really enjoy their page being scraped. Running a simple script a few times is mostly fine. But if you, for example, scrape a large number of pages every day to create a dataset over time, your traffic will most likely get flagged by the server, and you might encounter obstacles like bans, CAPTCHAs, and more.
A proxy server hides your identity and gives you a temporary mask to put on while interacting with the server. In the best case, you can even rotate these masks between requests to give the illusion of many people sending these requests instead of one.
While there are some free proxies available out there, the service of those is usually not suitable for any serious web scraping effort. Instead, you should pick a paid proxy—the reward will be worth the small cost of a few dollars.
Here’s how you can add a IPRoyal] proxy server to our request.
Purchasing Proxies for Python Web Scraping from IPRoyal
First, you need to have an IPRoyal account. If you don’t have one already, you can register for it on the sign up page .
For this tutorial, we’ll use Royal residential proxies . This is a service by IPRoyal that offers proxies from our large network of intermediaries. Instead of buying or renting access to a server, you can buy a set amount of data and use any of their intermediaries that are free. This enables for easy proxy rotation as you can use a different intermediary on each connection.
To use the service, you need to purchase some amount of data. For the tutorial, 1 GB is more than enough. To make an order, go to the Residential proxies section, and then choose the “Create new order” option.
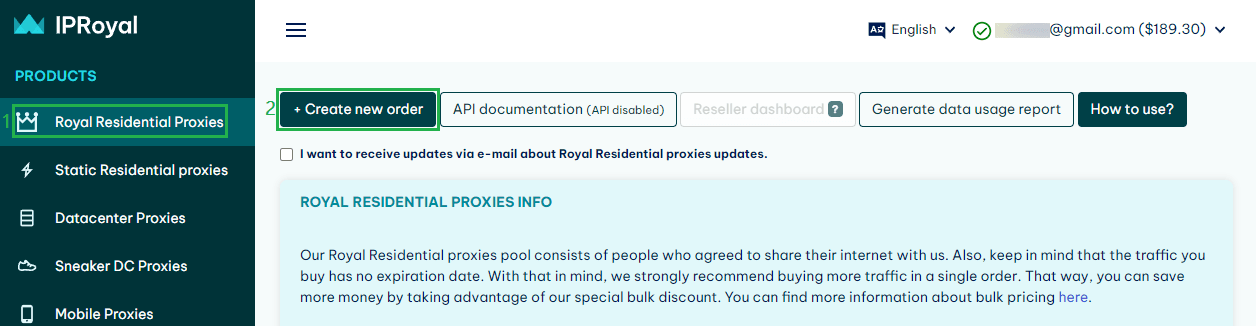
After finishing the purchase, you will be able to use the proxy service.
Now, you should get your credentials for the proxy service. You can access them further down in theResidential proxies section. Copy the first link from the “Basic curl example”.
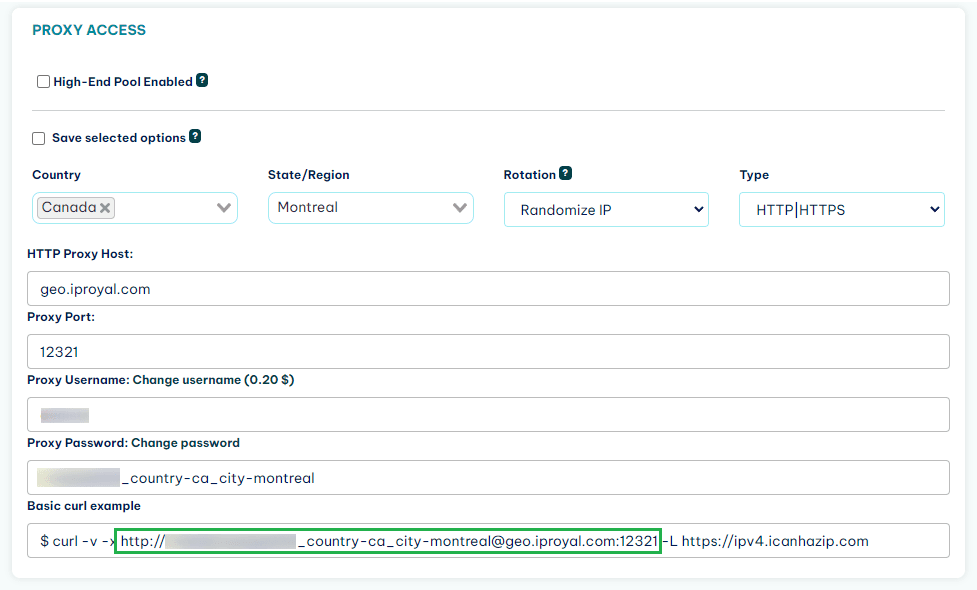
Adding IPRoyal Proxies to Your Python Web Scraping Project
Now, go to your script and create a PROXIES variable that will hold the link to these proxies (your link will differ from the one in the example).
PROXIES = {"http": "http://yourusername:[email protected]:22323",
"https": "http://yourusername:[email protected]:22323"}
After that, you can use this variable in the requests.get() function via a proxies keyword argument.
page = requests.get(next_page,
headers={'User-agent': 'Just learning Python, sorry!'},
proxies=PROXIES)
Now, all the traffic that you send to Reddit will first be routed through the proxy servers. On each request, the proxy server will be rotated, hiding your IP address to Reddit.

Final Thoughts
In this article, you learned about the basics of Python web scraping in 2022. You used two libraries—requests and BeautifulSoup—to get the titles of 500 posts from the programming subreddit. Then we showed you how to use this data to determine the most talked about programming languages at the moment.
Scraping the old interface of Reddit is quite easy, since Reddit doesn’t use any techniques to obfuscate the HTML in that interface. This is not the case with the newer interface, which generates classes automatically. You can try replicating the tutorial with the new interface as an exercise.
These two libraries are not the only web scraping libraries in the Python ecosystem. For more advanced Python web scraping projects, they might be too basic. In this case, you might want to look into Scrapy , a full-fledged scraping framework, and Playwright , an automation tool that simulates a real browser. For AI-assisted workflows, Gemini web scraping is worth looking into as a complement to these tools.
FAQ
What are the use cases of Python web scraping?
Web scraping is used in many industries to avoid manually searching for information on websites. In some cases, the amount of information harvested by web scraping can be so immense that any kind of human effort would be costly.
Some of the more common businesses with web scraping at their core are price comparison websites and market research companies. It’s used both by search engines like Google and SEO companies that want to reverse engineer how Google works. Regular businesses can also use it to gather all kinds of data on customers and competitors.
Can web pages detect web scraping?
A web page administrator can detect web scraping if your IP exhibits odd actions such as requesting a lot of pages at the same time, requesting the same set of pages at regular intervals, or not requesting files that scrapers don’t see such as pictures.
If you don’t want to be detected (and blocked) while scraping, you can do two things. The first is to use a scraping tool with a headless browser like Selenium or Playwright because they mimic the actions of real browsers.
The second is to use a proxy server while scraping. A proxy server can mask your real IP, and by rotating multiple proxies, you can obfuscate the fact that web scraping is happening since each IP will only request a part of the whole set of pages.
How to Not Get Blocked While Scraping?
The simplest way to not get blocked when doing web scraping is to play by the rules of the web administrators. This means not overloading the server with many requests simultaneously, following the instructions set in robots.txt, and not scraping information which you feel people wouldn’t want you to access in a programmatic way.
If that is not applicable to your use case, it’s essential to make your actions as close to a real user as possible. This could involve rotating user agents , IPs, making your scraping routines inefficient on purpose, and many other tricks.
Finally, it’s also important to minimize the downside of being blocked. If your IP address is blocked by a web administrator, you will have to jump through some hoops to be able to visit and/or scrape the site again. For this reason, you should use a proxy when scraping. If the proxy is detected and blocked, you can easily switch to another one and continue your work.


