'/%3e%3cellipse%20opacity='0.34'%20cx='327.5'%20cy='339'%20rx='264.5'%20ry='264'%20fill='url(%23paint1_linear_12724_35442)'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_12724_35442'%20x1='327'%20y1='-2.524e-06'%20x2='327'%20y2='389.286'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%2327D9E5'/%3e%3cstop%20offset='0.927406'%20stop-color='%23004047'%20stop-opacity='0'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_12724_35442'%20x1='328.02'%20y1='74.7771'%20x2='328.02'%20y2='395.312'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%2327D9E5'/%3e%3cstop%20offset='0.927406'%20stop-color='%23004047'%20stop-opacity='0'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)
How to Build a Facebook Scraper (and an Amazon Scraper)
Tutorials

Vilius Dumcius
Facebook has two billion active users. If it was a country, it would be the biggest in the world. And with this level of engagement, there is a lot of data waiting to be mined.
So let’s build a Facebook scraper.
If you don’t know how to code or you’re a beginner, stick around because this article teaches the coding way and the easy-peasy way.
Today you will learn what a Facebook scraper is and how to find the best one. Then you will build your own scraper from scratch and gather some data. In addition, we are going to scrape data from Amazon as well.
All of this without getting blocked.
This post is the third step in our programmatic SEO series. In it, we are building a programmatic SEO site from scratch. Here are the four main topics we are covering in this series:
- A programmatic SEO blueprint
What is programmatic SEO, why you should do it, how to plan your site, and how to research keywords. - How to perform automated web scraping in any language
How to pick the right programming language and libraries depending on your target sites, how to set up the backend for automated web scraping , and the best tools for web scraping. - How to build a Facebook scraper
Here we dive into how to collect data from our target site, collect data from other sites (such as Amazon), process data, and how to deal with errors. - Easy programmatic SEO in WordPress
In the last part of the series, you will learn how to use your scraped data to build a WordPress site.
Let’s get started!
What Is a Facebook Scraper?
A Facebook scraper is a tool that collects data from public pages, such as user profiles, businesses, marketplace listings, comments, and more.
In this example, our Facebook scraper is the data source for our programmatic SEO site. We are building a site to show users marketplace items in a specific city. But instead of showing a list of random items, we will pre-filter popular e-commerce items (such as MacBooks, iPhones, etc.) and scrape all listings for these. This allows users to quickly see attractive deals for popular items.
Here is a mockup of the landing page for the marketplace of a city:
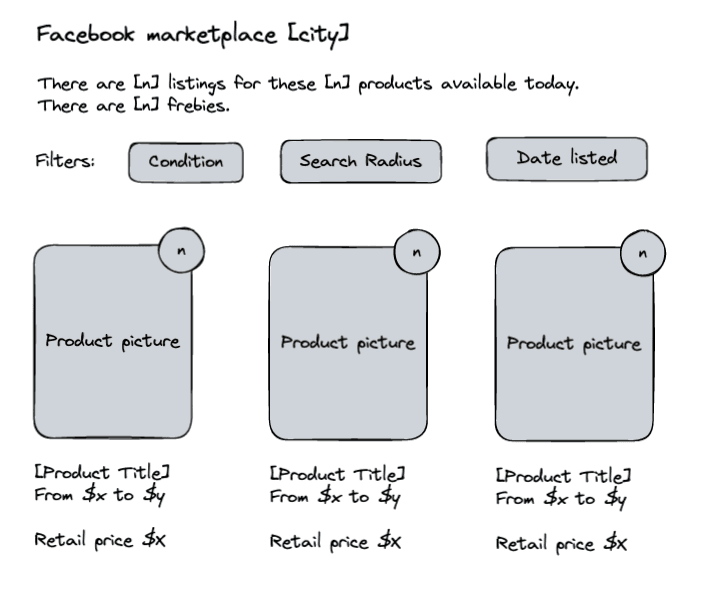
And this is what users see when they click on any of the products:
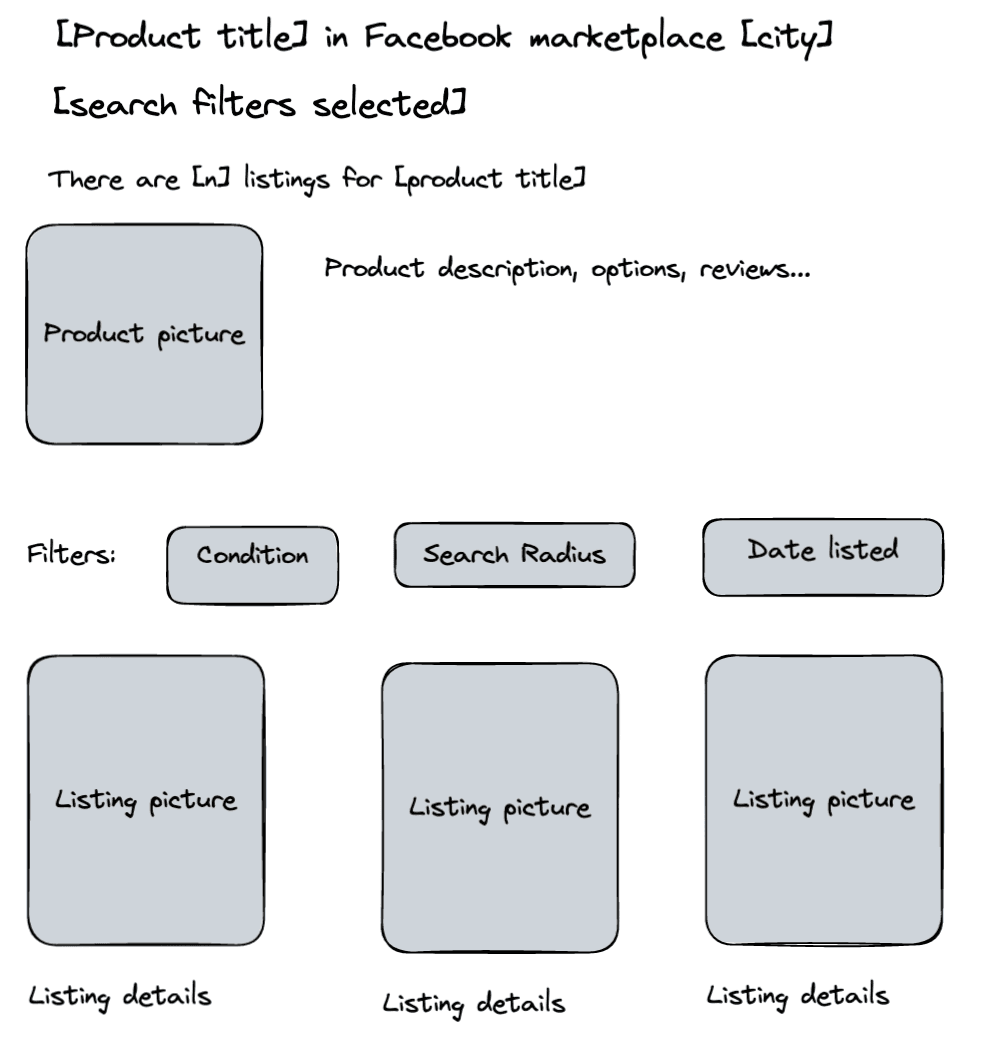
Therefore, we need to store data to show in these listings somehow. And we will use a combination of Amazon and Facebook to do it.
What Is the Best Facebook Scraper?
The best Facebook scraper is Playwright . This is a library that allows you to control real browsers with code. Therefore, you can easily scrape data from dynamic sites (such as Facebook) and go undetected.
Playwright has three other significant upsides when compared to other tools. First, it’s free. Scraping APIs are handy, but they can be quite expensive.
Another positive aspect is that this is a library developed by Microsoft, and it is available in many programming languages. Therefore, you learn its syntax once, and you can easily port your code to other programming languages if needed.
And finally, it provides easy commands and a tool to record your browser actions so that they are repeated by your scraper. So even if you don’t know how to code, you can just click what you want to click and Playwright generates the code for you.
How Do I Extract Data From Amazon?
You can extract data from Amazon (or any other site) using Playwright. The data extraction process can be divided into the following steps:
- Plan the data points you need to collect;
- Visit the target URLs;
- Write functions to extract data from these URLs (or use Playwright’s codegen function to automatically record your actions in the test browser and generate the JS code for it);
- Schedule loading these URLs with the extraction rules on set intervals.
Does Facebook Allow Scraping?
No, Facebook doesn’t allow scraping. All big websites try to block web scrapers as much as they can, even though web scraping is completely legal . To be precise, it’s legal as long as you collect data from public pages and don’t break other laws (such as using copyrighted material).
Luckily for us, the Facebook marketplace is public, and so are the Amazon listings. So we are clear to scrape these pages.
Now you need to avoid getting blocked.
The first step is to use IPRoyal’s Residential proxy service . With it, you can visit your target pages using different IP addresses each time. Therefore, they won’t even know that these visits come from the same user. From their point of view, these are different visits made by different users from different countries.
Since you are using Playwright, you have real browser headers. Some code libraries don’t come with real headers by default, which might seem suspicious to website owners, and they can block these visits.
Also, make sure you add some random delays in your actions so they mimic human behavior. If you just visit a page and click a link at the bottom, that would seem weird, but if it takes you a couple of seconds to do it, it’s fine.
There are other methods to avoid detection, depending on what your target sites use to detect web scrapers. For example, make sure that you remove unique query arguments from the URL and delete cookies, since they can be used to identify users .
Building Your Facebook Scraper (and Amazon Scraper)
Our Facebook scraper needs to visit the marketplace for a city and send a search query for a product. Then it will extract data from these posts.
In the future, you can make it better by adding search radius control, add checks on the product name/description/model, check the seller’s ratings, and so on. But let’s keep it simple for now.
Even though the Facebook scraper is vital to our programmatic site, the starting point is the Amazon scraper. The Amazon scraper gets our products from a database, then scrapes prices for each of them to be used as a comparison point. After that, we can use the product name to search the marketplaces of each city to see the current listings.
The entire scraping process can be summarized in these steps:
- Load all relevant libraries (Playwright, database connection);
- Connect to the database;
- Load the list of products to scrape from Amazon, along with their URLs;
- Scrape the Amazon page, get the product price, and save it to the database;
- Load the list of cities to scrape;
- Scrape the Facebook Marketplace page of a city, searching for this product;
- Scrape the offers for this city and save them to the database;
- Scrape the next city, repeating 6 and 7 as many times as needed;
- Scrape the next product, repeating 6, 7, and 8 as many times as needed.
That’s it, let’s get started!
If you haven’t already, install Playwright on your computer. You can do it with this command:
npm install playwright
Now, if you look at the Facebook marketplace pages, you’ll notice that they all have a very similar URL structure:
facebook.com/marketplace/[cityname]
For example:
https://www.facebook.com/marketplace/boise/
And, if you search for an item, Facebook just adds ?query=[search terms]. For example:
https://www.facebook.com/marketplace/boise/search/?query=macbook
This gives us a starting point for scraping listings from each city on Facebook marketplaces. You can use this code snippet to load the listing search page with Playwright, and scrape a list of the products for sale on it:
const { chromium } = require('playwright');
(async () => {
const browser = await chromium.launch();
const page = await browser.newPage();
await page.goto('https://facebook.com/marketplace/boise/search?query=macbook');
await page.waitForSelector('[aria-label="Collection of Marketplace items"]');
const locators = page.locator('[aria-label="Collection of Marketplace items"] a');
const elCount = await locators.count();
let entries = [];
let hrefs = [];
for (var index= 0; index < elCount ; index++) {
const element = await locators.nth(index);
const innerText = await element.innerText();
const href = await element.getAttribute('href');
entries.push(innerText);
hrefs.push(href);
}
console.log(entries);
console.log(hrefs);
await browser.close();
})();
Here is what each block does:
- const { chromium } = require('playwright') - This requires the Playwright library and initiates the Chromium browser. You can use other browsers if you want, such as Firefox.
- const browser = await chromium.launch() - open the browser window.
- const page = await browser.newPage() - open a new tab.
- await page.goto(' https://facebook.com/marketplace/boise/search?query=macbook ') - go to the Boise marketplace URL, searching for MacBooks.
- await page.waitForSelector('[aria-label="Collection of Marketplace items"]') - this is just to make sure that the marketplace posts are loaded - otherwise our code might try to load items before they are on the page.
- const locators = page.locator('[aria-label="Collection of Marketplace items"] a') - creates an array with each marketplace item in one element.
- const elCount = await locators.count() - finds out how many marketplace items there are for sale.
- let entries = []; let hrefs = [] - starting up arrays that will be used later on.
- for (var index= 0; index < elCount ; index++) {} - loop through the links array, save the text on the entries array and the link on the hrefs array for each marketplace post.
- console.log() - a simple output to make sure it works as it should.
And this is the result of that code snippet:
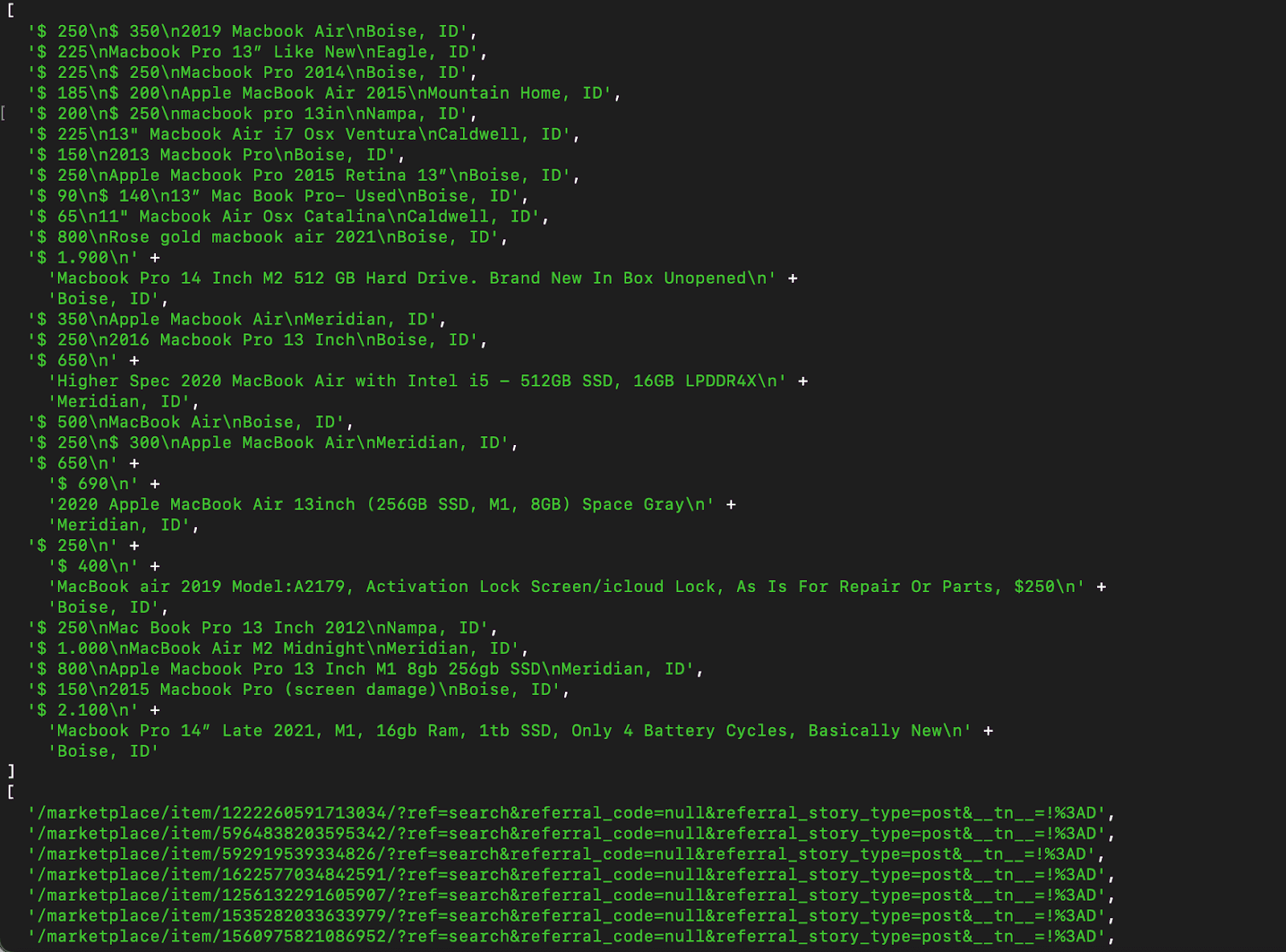
Some of the links didn’t fit the screen, but they all follow the same pattern, /marketplace/item/ID/?QUERYARGS. Notice that the descriptions follow a simple pattern, with \n instead of line breaks, which is incredibly useful for us.
You can save these results to your database using the MySQL connection. This can be useful if you have a WordPress site, so you can save the scraping results in the same database as your WordPress site.
Run this command:
npm install mysql
This installs the MySQL library in your project. Now you can use a code snippet like this one to connect to your database:
const mysql = require("mysql");
const connection = mysql.createConnection({
host: "localhost",
user: "root",
password: "password",
database: "database"
});
connection.connect(err => {
if (err) throw err;
console.log("Connected to the database!");
});
connection.query("SELECT * FROM table", (err, rows) => {
if (err) throw err;
console.log(`Number of rows: ${rows.length}`);
rows.forEach(row => {
// Perform a function for each row
console.log(row);
});
});
connection.end();
You can add this connection as a separate file or inside the main scraper file. Then you can run a command such as INSERT INTO or UPDATE, replacing the debugging functions in the code snippet above.
For example, replace these lines:
entries.push(innerText);
hrefs.push(href);
With this code (make sure to include the library require and connection before this line):
connection.query(‘INSERT INTO table_name (city_ID, product_ID, url, description) VALUES (“boise”,”macbook air m2”, ‘ + href + ‘, ‘ + entry + ‘ )" [...rest of the code goes here]
This saves the scraped data into your database instead of saving them in a temp variable.
Another interesting aspect is that you can use the first database connection example as a starting point for your Amazon scraping. So it gets all items from a table and it runs a function (which is the scraping function) for each table.
How to Scrape Product Prices From Amazon
Now it’s time to scrape product prices from Amazon. This time, instead of writing code, let’s do something different.
Run this code in your terminal:
npx playwright open https://www.amazon.com/2022-Apple-MacBook-Laptop-chip/dp/B0B3BVWJ6Y
This command opens two windows. The first one contains the browser window with the URL specified. The second command is a tool to record your browser actions and turn them into code. Click “Record” and select target: Library.
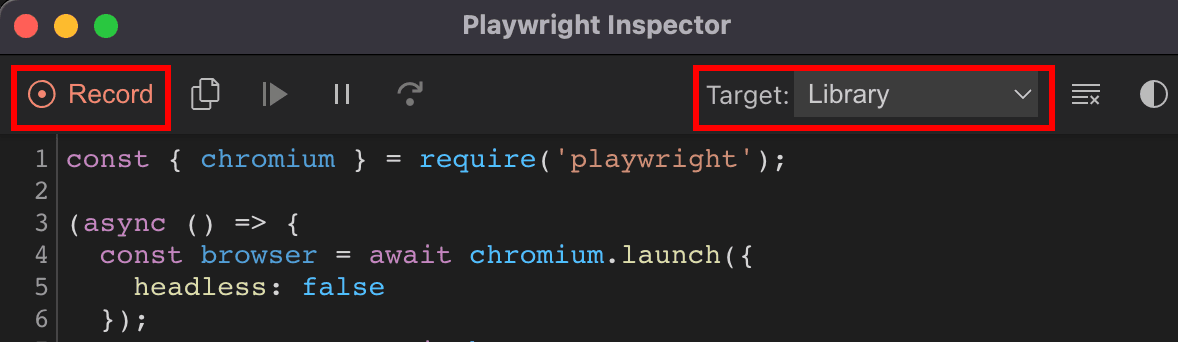
Now everything you do on your browser will be recorded as a code command.
Feel free to play around and explore the options there, then stop recording. In our case, since we won’t navigate away from that page, you can use the “pick locator” button to generate the locator for an element when you click on it:
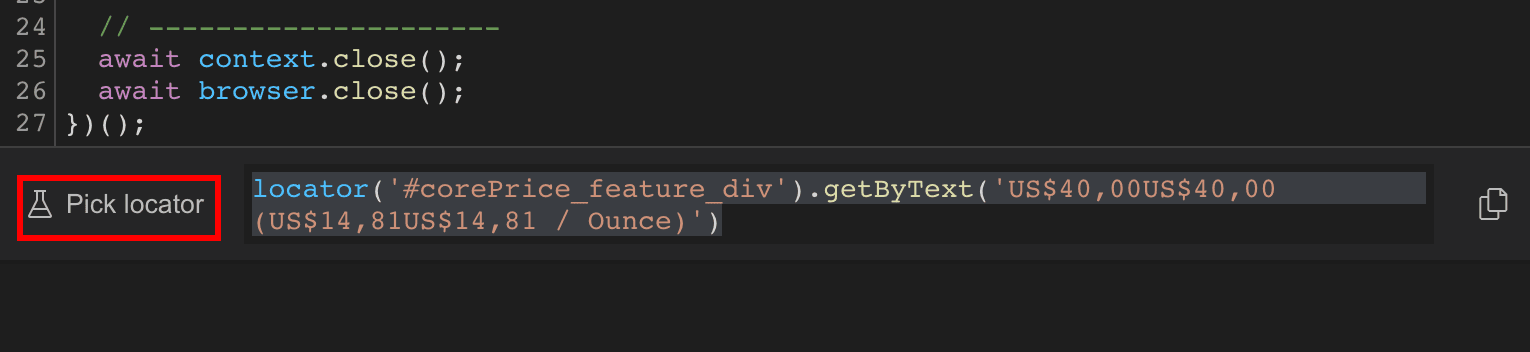
Notice that this isn’t a fail-proof method. For example, if you try to get the main price of a product, you might get a selector like this:
getByText('US$40,00').nth(1)
You’ll notice that there is no CSS selector on this element at all. It picks the price based on the text that is there.
This just doesn’t work for our scraper. We want to know when the price changes. If we use this selector, by definition, we won’t get any price changes since the getByText function won’t find any matches with the previous price.
Let’s use something different, like this:
locator('#corePrice_feature_div')
You can move the mouse around to select broader elements until you find something like that.
Now you just need to use these selectors on your Amazon scraper. Since the Amazon scraper is fixed, you don’t need to load the scraping rules dynamically - you can hard-code them.
It’s worth mentioning that it’s very likely that you will get blocked if you just use these code snippets as they are. You need to use a service like IPRoyal’s residential proxies service. It allows you to scrape these pages from different IP addresses each time you do it, making it very hard for site owners to detect you.
After you sign up, you get access to the client area:
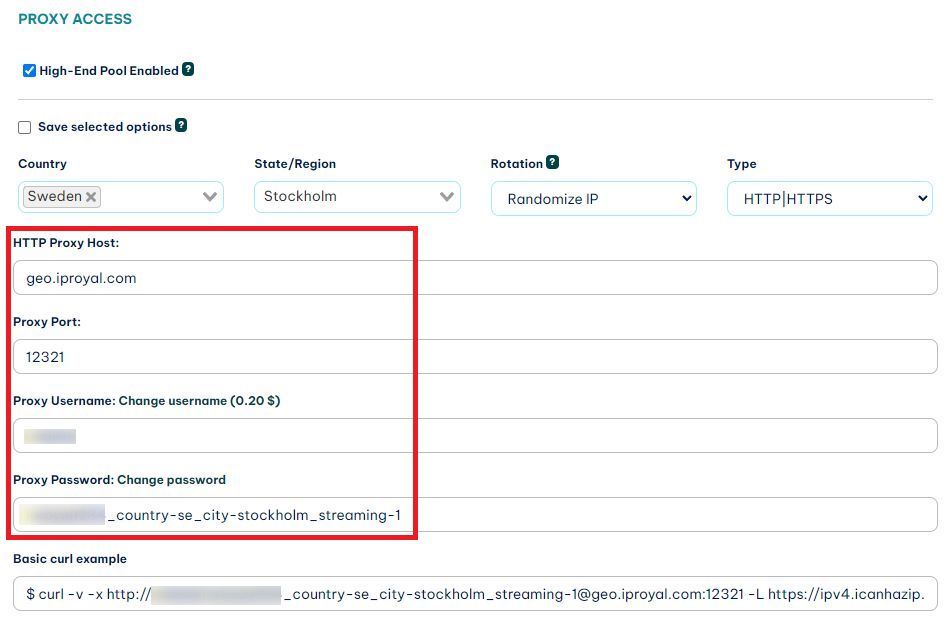
You can use these credentials in your Playwright connection like this:
const browser = await chromium.launch({
proxy: {
server: 'http://geo.iproyal.com:12321',
user: ‘username’,
password: ‘password’
}
});
Now the sky's the limit. You can improve these snippets and save any data points you want to. Also, you can combine these code snippets with the automation tips from the previous article and use a cron job to run it from time to time.
Conclusion
You can use the tips from this article to scrape Facebook marketplace items, Amazon products, or anything else you want from these sites or other sites. You’ve learned how you can do it using code snippets or even using Playwright to generate the code for you.
In addition, you saw how planning the scraping logic and process can be useful. And you’ve learned how you can scrape sites without getting blocked.
Surely, you can improve these scrapers by dealing with infinite scrolls, validating listings to make sure they match a product, scrape the individual listing data. But this is a starting point that should work well for your programmatic website.
We hope you’ve enjoyed it, and see you again next time!
FAQ
Can Facebook ban my IP?
Facebook can ban IP addresses, and it analyzes account behaviors to ensure they aren’t bots. For this reason, don’t log in while running your scraper, and if you do, make sure to mimic human behavior with random time delays on actions.
The good news is that if you use a residential proxy, they will block a random IP address, which is not related to your real IP address.
Can we scrape data from Facebook?
You can scrape data from Facebook using Playwright. With it, you can open a browser instance and mimic human behavior. Therefore, you can visit pages, profiles, and marketplaces to get the page contents.
How to scrape Facebook group posts?
You can scrape Facebook group posts with a headless browser, such as Playwright or similar. In this case, make sure to include random delays in your actions and to emulate human behavior the best you can. Use random mouse movements and page clicks with a reasonable timeframe that can be achieved by a real human.


