How To Scrape Data From Expedia
Tutorials

Simona Lamsodyte
Key Takeaways
-
Since Expedia uses dynamic JavaScript rendering, traditional HTML parsers like BeautifulSoup are insufficient; tools like Playwright or Puppeteer are required to interact with and load the data.
-
Successful scripts must account for asynchronous loading by implementing logic to click “Show More” buttons and using specific locators for elements like prices and ratings that may not always be present.
-
Large-scale scraping triggers sophisticated detection systems like Akamai, making the use of residential proxies and IP rotation necessary to mimic human behavior and maintain access.
Expedia is a leading travel platform that aggregates global data on hotel listings, flights, and vacation rentals.
By scraping Expedia, you can access valuable data for market research, competitor analysis, or simply to find the best hotel deal for yourself.
In this article, you’ll read about the best methods that you can use to scrape Expedia, including a complete example on how to scrape Expedia for hotel prices using Python.
What Data Can You Scrape From Expedia?
The Expedia Group platforms hold vast amounts of information beyond hotels alone. You can extract data such as:
- Hotels. Names, star ratings, review counts, and property amenities.
- Flights. Flight data, including times, carriers, and prices.
- Travel packages. Bundled deals for vacations.
- Car rentals. Pricing and availability for car rentals.
- Search page details. Real-time data from search listings, including pricing, geographic coordinates, and proximity to landmarks.
Specific Challenges Involved in Scraping Data From Expedia
Like most modern websites, Expedia is a dynamic website that uses plenty of JavaScript for rendering content and handling user interactions. For this reason, it’s hard to scrape using conventional, HTML-based web scrapers like Beautiful Soup and Cheerio since they cannot execute JavaScript.
Tools and Libraries for Efficient Data Scraping From Expedia
To effectively scrape Expedia at scale, you should use browser automation tools like Playwright or Puppeteer, often paired with stealth plugins to bypass bot detection. These web scraping tools provide the flexibility needed to interact with Expedia’s dynamic elements and extract the information you require.
One of the best tools for web scraping dynamic websites like Expedia is Playwright. It has official bindings for multiple languages such as JavaScript, Python, Java, and C#, enabling a wide variety of developers to use it no matter the language they are experienced with.
Web Scraping Expedia Using Python and Playwright
In the following section, you’ll learn how to use Playwright via Python to scrape hotel information for a city.
Setup
To follow the tutorial, you’ll need to have Python installed on your computer. If you don’t already have it, you can use the official instructions to download and install it.
You’ll also need to install Playwright. Use the following commands to install the library and its supported browsers.
pip install playwright
playwright install
Scraping Hotels
To extract hotel data for a given location and dates, you first need to open the website in Playwright.
The following script opens the Expedia website for a future trip to Milan. We use dynamic dates to ensure the search returns active listings.
import time
from datetime import datetime, timedelta
from playwright.sync_api import sync_playwright
today = datetime.now()
start_date = (today + timedelta(days=30)).strftime('%Y-%m-%d')
end_date = (today + timedelta(days=35)).strftime('%Y-%m-%d')
with sync_playwright() as pw:
browser = pw.firefox.launch(headless=False)
page = browser.new_page()
url =
f'https://www.expedia.com/Hotel-Search?adults=2&d1={start_date}&d2={end_date}&destination=Milan'
page.goto(url)
time.sleep(5) # Wait for dynamic content to load
cards = page.locator('[data-stid="lodging-card-responsive"]').all()
hotels = []
for card in cards:
content = card.locator('div.uitk-card-content-section')
title = content.locator('h3').get_by_role("heading").first.text_content()
rating = content.locator('span.uitk-badge-base-text').first.text_content() if
content.locator('span.uitk-badge-base-text').is_visible() else "No Rating"
price = content.locator('div.uitk-type-500').first.text_content() if content.locator('div.uitk-type-500').is_visible() else "No Price"
hotels.append({'title': title, 'rating': rating, 'price': price})
print(hotels)
browser.close()
It’s possible to create a script that enters the location and dates you wish in the web interface and clicks the search button to acquire the URL. While this tutorial won’t cover how to do that, it’s a fun exercise to do after you finish the tutorial.
After you have arrived at the page, you need to scrape the information from the cards that appear in the search results.
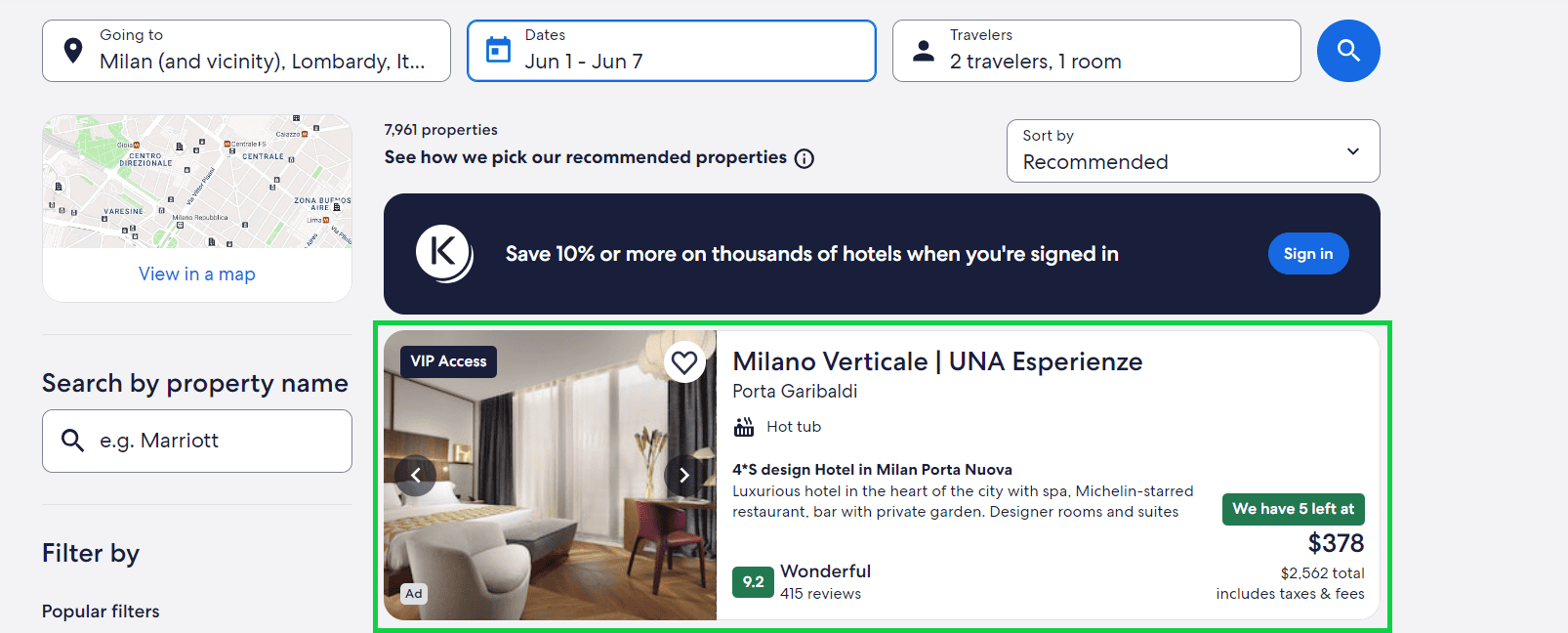
First, select all the cards.
cards = page.locator('[data-stid="lodging-card-responsive"]').all()
Then, iterate over the cards to accumulate information about the hotels. In this example, you’ll scrape the title, rating, and price for the night of the hotels.
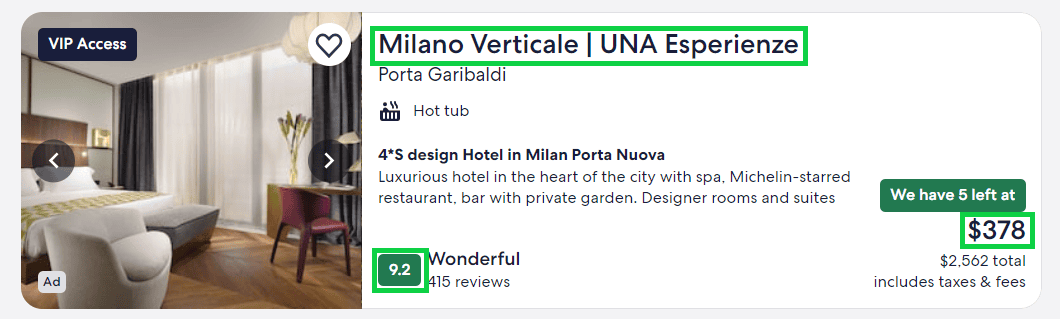
hotels = []
for card in cards:
content = card.locator('div.uitk-card-content-section')
title = content.locator('h3').text_content()
if content.locator('span.uitk-badge-base-text').is_visible():
rating = content.locator('span.uitk-badge-base-text').text_content()
else:
rating = False
if content.locator('div.uitk-type-500').is_visible():
price = content.locator('div.uitk-type-500').text_content()
else:
price = False
hotel = {
'title': title,
'rating': rating,
'price': price}
hotels.append(hotel)
Since there are some hotels that don’t yet have a rating or a price (this happens if they are fully booked or closed for the dates), you need to handle the missing values without crashing the script. For this reason, the code above checks if these elements are visible before selecting them. If they are not, it puts False as the value of the element.
Finally, you can print out the hotel list:
print(hotels)
Here’s the full code for this section:
page.wait_for_load_state("networkidle")
cards = page.locator('[data-stid="lodging-card-responsive"]').all()
hotels = []
for card in cards:
title = card.locator('h3').first.text_content()
rating_element = card.locator('span.uitk-badge-base-text').first
rating = rating_element.text_content() if rating_element.is_visible() else None
price_element = card.locator('[data-test-id="price-column-only"]').first
price = price_element.text_content() if price_element.is_visible() else None
hotels.append({'title': title, 'rating': rating, 'price': price})
Once run, it should return a list of hotels:
[{'title': 'Milano Verticale | UNA Esperienze', 'rating': '9.2', 'price': '$379'}, {'title': 'Hyatt Centric Milan Centrale', 'rating': '8.8', 'price': '$326'}, {'title': 'UNAHOTELS Galles Milano', 'rating': '8.6', 'price': '$258'}, {'title': 'Residence de la Gare', 'rating': '8.8', 'price': '$137'}...
But this list doesn’t have all of the hotels listed. To access all of them, you need to expand the list by clicking the “Show More” button at the bottom of the list.
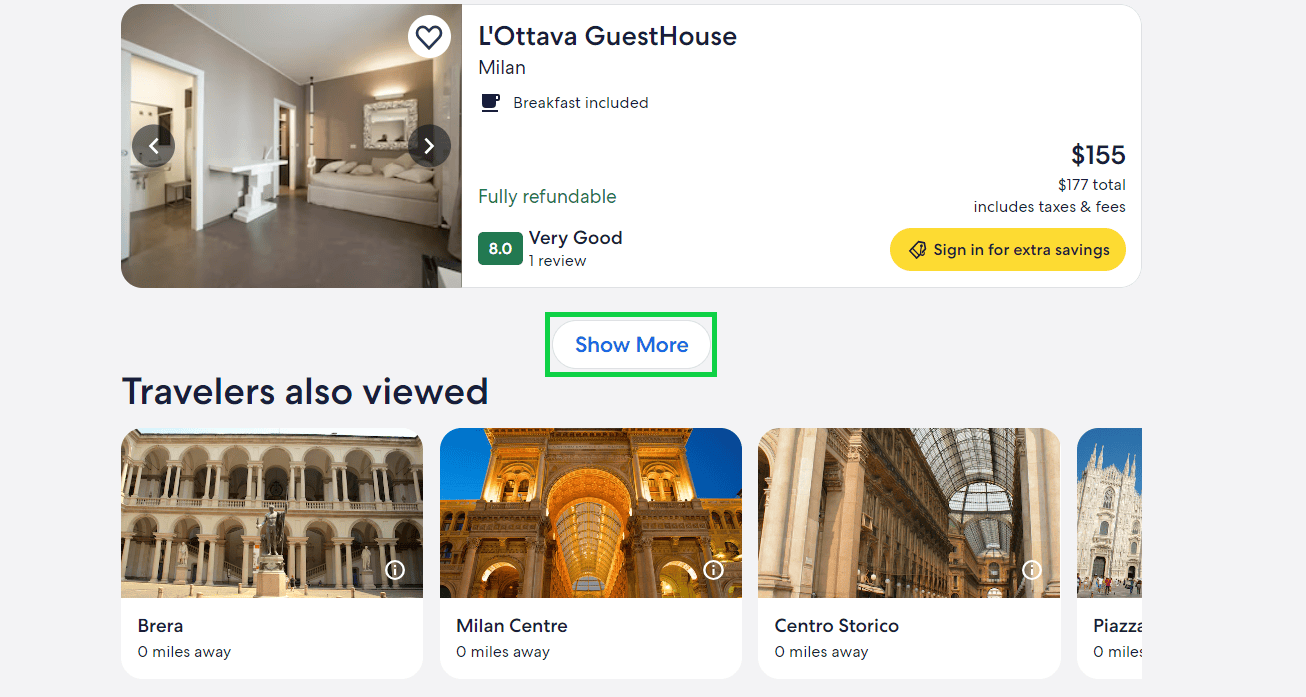
This is where web scraping with a web automation library comes in handy: you can click, write, and do any other action a regular user could do!
Expanding Search Results With Playwright
To get the full search results, you need to repeatedly expand the list until the “Show More” button disappears before scraping the results.
Add the following code in the middle of the script, before you start scraping the cards. It locates the button, clicks it, waits for the results to load, and then repeats this process if the button is still there.
#scroll to the bottom of page
show_more = page.locator("button", has_text="Show More")
while show_more.is_visible() is True:
show_more.click()
time.sleep(5)
This pattern can be useful to handle any kind of repetitive loading of elements like in dynamic websites.
Here’s the full code for the script:
import time
from datetime import datetime, timedelta
from playwright.sync_api import sync_playwright
today = datetime.now()
start_date = (today + timedelta(days=30)).strftime('%Y-%m-%d')
end_date = (today + timedelta(days=35)).strftime('%Y-%m-%d')
def scrape_expedia_full():
with sync_playwright() as pw:
browser = pw.firefox.launch(headless=False)
context = browser.new_context(
viewport={'width': 1920, 'height': 1080},
user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:109.0) Gecko/20100101 Firefox/115.0"
)
page = context.new_page()
url = f'https://www.expedia.com/Hotel-Search?adults=2&d1={start_date}&d2={end_date}&destination=Milan'
page.goto(url)
print("Expanding search results...")
while True:
show_more_btn = page.get_by_role("button", name="Show More")
if show_more_btn.is_visible():
show_more_btn.scroll_into_view_if_needed()
show_more_btn.click()
page.wait_for_load_state("networkidle")
time.sleep(2) # Short safety pause for DOM rendering
else:
print("All results loaded.")
break
cards = page.locator('[data-stid="lodging-card-responsive"]').all()
hotels = []
for card in cards:
title = card.locator('h3').first.text_content()
rating_el = card.locator('span.uitk-badge-base-text').first
rating = rating_el.text_content() if rating_el.is_visible() else None
price_el = card.locator('[data-test-id="price-column-only"]').first
price = price_el.text_content() if price_el.is_visible() else None
hotels.append({'title': title, 'rating': rating, 'price': price})
print(f"Final Count: {len(hotels)} hotels scraped.")
print(hotels[:5]) # Print first 5 for verification
browser.close()
if __name__ == "__main__":
scrape_expedia_full()
How to Scrape Hotel Detail Pages
To get hotel details, you must follow the links from the search results, which allows for a deeper competitive analysis. Here’s a step-by-step:
- Open links. Extract the URL from each hotel card and open them in new tabs to speed up the extraction process.
- Extract specifics. Once on the page, you can find:
- Full address. Usually located near the top.
- Check-in/out. Found in the “Policies” section.
- Room types. Different options like King or Queen rooms.
- Final price breakdown. Extracting the total price, including taxes, usually requires navigating to the specific room selection area on the page.
- Amenities. Items like free Wi-Fi or a pool.
- Review’s summary. Detailed scores for cleanliness and staff.
How to Scrape Expedia Without Coding (Octoparse)
To start off, open your regular browser and perform the search on Expedia. Make sure you enter the location, check-in and check-out dates, and all the other relevant information. Once you hit “Search” and get your results, copy the link to the page over to Octoparse’s built-in browser.
We’ll extract data from all available result pages on Expedia, so make sure to click the “Show More” button and enable “loop click the selected link” in the Action Tips menu. This way, Octoparse will go through all results while scraping.
Open the Details Page for Each Hotel
Click the name of each hotel on the listing page until all the titles are selected and highlighted in green. After that, select “Loop click each element” in the Action Tips menu. This way, Octoparse will click through all available listings from your search.
Select the Data You Wish to Extract
The last thing to do is click on the data fields you want to scrape (hotel name, price, address, rating, and the image). Once you’re done, all that’s left is to run the task and let Octoparse work its magic.
Using Proxies to Overcome Restrictions and Anti-Scraping Measures
Scraping a small amount of data might keep your request volume low, but modern security systems like Akamai can still detect and block automated browsers based on their digital fingerprint, regardless of the traffic volume.
While Expedia handles massive traffic, they employ sophisticated behavioral analysis to distinguish real travelers from automated scripts in real-time. But if you want to gather a large-scale dataset that includes multiple cities, dates, and perhaps even the historical changes in the prices of hotels, your actions might get detected, and your IP address might get denied service from Expedia.
For this reason, proxies are used for large-scale web scraping activities. Proxies act as middlemen between the client and the server, forwarding the request to the server but changing the IP address from which the request comes.
With a service like IPRoyal residential proxies , you can leverage IP rotation on every request, picking at random from a pool of ethically-sourced IPs all around the world. This will help avoid detection: your requests will look like they originate from many different users instead of just one.
Here’s how you can add a proxy to your Playwright script.
First, you will need to find the host, port, username, and password information for your proxy server of choice. If you’re using IPRoyal proxies, you can find this information in your dashboard.

Update the browser launch function (e.g., pw.firefox.launch) with the proxy configuration.
import time
from playwright.sync_api import sync_playwright
# Replace these with your actual IPRoyal credentials
PROXY_HOST = "geo.iproyal.com"
PROXY_PORT = "12345"
PROXY_USER = "your_username"
PROXY_PASS = "your_password"
with sync_playwright() as pw:
browser = pw.firefox.launch(
headless=False,
proxy={
"server": f"http://{PROXY_HOST}:{PROXY_PORT}",
"username": PROXY_USER,
"password": PROXY_PASS,
}
)
context = browser.new_context(locale="en-US", timezone_id="America/New_York")
page = context.new_page()
page.goto("https://ipv4.icanhazip.com")
print(f"Current IP: {page.locator('body').text_content().strip()}")
browser.close()
Now all the requests from the Playwright session will be funneled through your chosen proxy server.
Potential Applications and Use Cases for Scraping Expedia Data
Scraping Expedia can provide valuable information for a variety of applications and use cases. Here are some potential applications and use cases for web scraping data from Expedia:
- Price monitoring. Travelers often use price comparison websites to find the best deals. Scraping Expedia data can be used to create a price comparison tool that helps users find the lowest prices for flights, hotels, and vacation packages.
- Market research. Expedia data can be used to analyze travel trends, pricing strategies, and customer preferences. This information is valuable for businesses looking to enter or optimize their presence in the travel industry.
- Competitor analysis. Market analysis via Expedia helps hotels monitor price parity and ensures their direct-booking rates remain competitive against OTA (Online Travel Agency) bundled discounts.
- Customer review analysis. Large-scale extraction of reviews allows for AI-driven sentiment analysis, categorizing specific pain points like check-in efficiency or room cleanliness across entire regions.
- Predictive analytics. Data scraped from Expedia can be used to build predictive models for travel demand, pricing trends, and seasonal variations. This can help businesses optimize their operations and marketing strategies.
Conclusion
By using common web scraping tools such as Python and Playwright, you can easily scrape hotel information from Expedia. In a similar manner, you can also scrape Expedia for the individual hotel pages to get more valuable data on what’s available on the market.
Once you increase the depth of your scraping activities, it’s important to start using proxies to protect your IP address from detection and IP bans. To solve this, a common solution is to get a reliable proxy provider like IPRoyal that provides a pool of proxies that can be rotated between requests.
FAQ
Is scraping data from Expedia legal for personal or commercial use?
Scraping publicly accessible travel data is generally considered lawful for personal and market research, provided you respect the site's robots.txt and don’t collect personal user information. But if you make an account and use it while scraping, you fall under Expedia’s Terms of Service , which prohibit to “access, monitor or copy any content on our Service using any robot, spider, scraper or other automated means or any manual process”. Therefore, it’s suggested to access only the public part of the website with your scripts.
Are there any limitations on the number of requests or concurrent connections when scraping data from Expedia?
There is no public information on any limitations, but most requests tend to act once they receive a large number of requests (especially concurrent) from the same user. For this reason, it’s important to use proxies if you plan to make many requests. This will hide the fact that large-scale scraping is happening and help protect your IP address from being blacklisted. Read our Expedia scraping example above to see how you can add proxies to your script.
Can I scrape hotel prices and availability from Expedia using proxies?
Yes, it’s possible and even suggested to use proxies for scraping Expedia, no matter how much you plan to scrape. It helps protect your IP address from being banned while scraping websites. If you want to learn how to do it, check out the final section of our Expedia web scraping code example.
Why are Expedia prices different from what I see in my browser?
Expedia often varies prices based on your geographic location, device type (mobile-only deals, for example), and real-time inventory fluctuations rather than individual search frequency. Using proxies from different regions can help you see these variations.
Can I scrape Expedia without a headless browser?
It’s very hard because the site relies on JavaScript. Without a browser like Playwright, you might only see a blank page or missing Expedia data.
How do I handle CAPTCHA, 403, or 429 errors?
These are signs of bot detection. To bypass advanced detection, use residential proxies, implement exponential backoff for retries, and ensure your browser fingerprints (like User-Agents and TLS signatures) are perfectly aligned.
How often does Expedia change its HTML or selectors?
Large sites like Expedia change their structure often to improve the site or stop bots. You should check your Python code regularly to make sure it still finds the right data.

