How To Scrape Data From GitHub
Tutorials

Marijus Narbutas
GitHub is the most popular platform for collaborative software development and version control.
By scraping it, you can get valuable information about repositories, commonly used languages, and even trending projects for languages.
In this article, you will learn how to scrape GitHub using Python and Beautiful Soup .
First Steps
Since GitHub is mostly a simple, static website that doesn’t use JavaScript to load or display important information, it’s possible to scrape it with basic web scraping tools. There is no need to imitate a browser using an automation tool like Selenium .
All you need to do is:
- Download the HTML code of a page you want to scrape with an HTTP client library.
- Parse the HTML you’ve downloaded with a parser.
Depending on the language you are familiar with, there will be plenty of choices for libraries to use.
Alternatively, GitHub has a very reasonable API that can be used for hobby purposes instead of scraping.
Which Python Libraries Can Be Used
If you’re using Python, the libraries you should use for scraping GitHub are Requests and Beautiful Soup.
The first enables you to download the HTML code of a page you want to scrape, while the second enables you to easily find the data you need inside that page.
Scraping GitHub With Beautiful Soup
In this tutorial, you’ll learn how to use Requests and Beautiful Soup to scrape information about trending Python repositories from GitHub. The tutorial assumes some familiarity with both libraries.
Setup
To follow the tutorial, it’s essential to have Python installed on your computer. If you haven’t already done so, you can refer to the official instructions for downloading and installing Python.
Additionally, you’ll need to install the Requests and Beautiful Soup libraries. You can do that with the following terminal commands:
pip install requests
pip install bs4
Downloading HTML With Requests
To scrape a web page with Beautiful Soup, you first need to download the HTML code of the page. This is usually done with the Requests library.
url = 'https://github.com/trending/python'
response = requests.get(url)
The HTML code of the page will now be accessible under the .text property of the response variable.
Parsing With Beautiful Soup
Once you have the HTML of the web page, you can use Beautiful Soup to parse it and find the necessary data.
First, parse the whole page using the BeautifulSoup() method:
soup = BeautifulSoup(response.text, 'html.parser')
Then you can call functions on the soup object to find the information you need. First, select all the individual sections that contain data about the repositories.
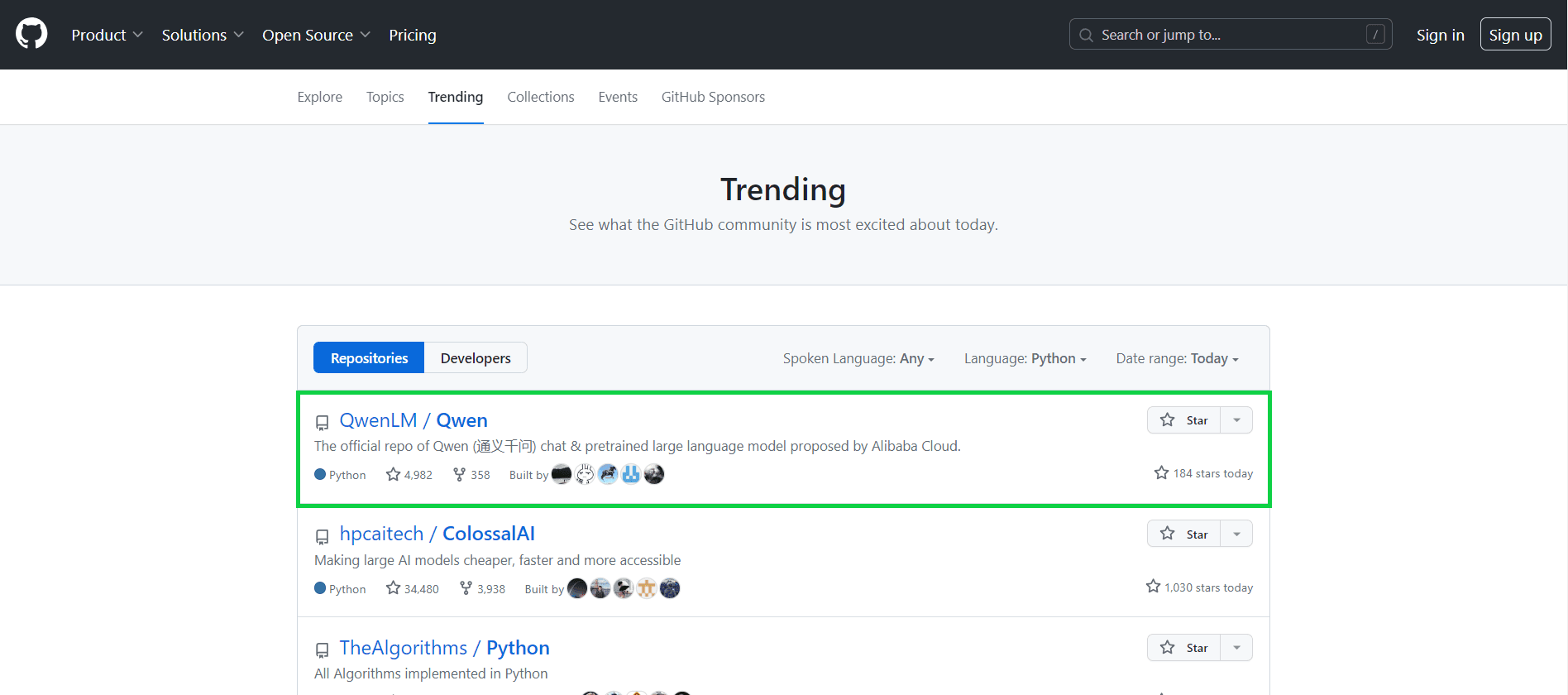
repo_list = soup.find_all('article')
Then, iterate over them to scrape the necessary information. In this case, it will be the name, star count, and link to the repository.

repos = []
for repo in repo_list:
name = repo.find('h2').text.split('/')[1].strip()
star = repo.find('svg', attrs={'aria-label': 'star'})
star_count = star.parent.text.strip()
link_stem = repo.select_one('h2>a')['href']
link = 'https://github.com' + link_stem
repo = {'name': name, 'star_count': star_count, 'link': link}
repos.append(repo)
Here’s how the code example finds the elements:
name: finding the h2 element of the card, extracting its text, splitting it on/, and stripping all the empty space at start and end.star_count: finding a star icon, then extracting the text of the element that contains it.link: selecting thehrefproperty of the anchor link inside the h2 element.
Finally, you can print all the data to the console.
print(repos)
It should return a result similar to this:
[{'name': 'ChatDev', 'star_count': '8,644', 'link': 'https://github.com/OpenBMB/ChatDev'}, {'name': 'Real-Time-Voice-Cloning', 'star_count': '47,013', 'link': 'https://github.com/CorentinJ/Real-Time-Voice-Cloning'}, {'name': 'Python', 'star_count': '169,620', 'link': 'https://github.com/TheAlgorithms/Python'} ... ]
For convenience, here’s the full example code for a trending repository scraper:
import requests
from bs4 import BeautifulSoup
url = 'https://github.com/trending/python'
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
repo_list = soup.find_all('article')
repos = []
for repo in repo_list:
name = repo.find('h2').text.split('/')[1].strip()
star = repo.find('svg', attrs={'aria-label': 'star'})
star_count = star.parent.text.strip()
link_stem = repo.select_one('h2>a')['href']
link = 'https://github.com' + link_stem
repo = {'name': name, 'star_count': star_count, 'link': link}
repos.append(repo)
print(repos)
Advanced Project: Crawling GitHub Repo Descriptions
Since GitHub provides links to individual repositories, you can collect much more information than the name and star count of the project. For example, you can crawl the repositories readmes to get more information about the projects.
In the following couple of sections, you’ll learn how to do it.
Crawling Data
First, you need to go through the repo list, iteratively visit each repo, and scrape the text of their readme.
To do this, you’ll need the time library. During the script, you’ll be visiting plenty of pages, and it’s important to pause between visits to not get flagged by GitHub.
Import it at the top of the file:
import time
Then put the following function at the end of the file:
for repo in repos:
url = repo['link']
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
readme = soup.select_one('div[id="readme"]').text
print(readme)
time.sleep(2)
For each repository scraped, it visits the URL of that repository and scrapes the full text of the readme document that appears at the bottom of the page.

Then, it waits for two seconds and then continues scraping. This is necessary so that GitHub wouldn’t flag your IP address for visiting many pages in quick succession.
To fix the wait, you can use a proxy.
Improving Scraping Speed With a Proxy
If you want to improve the speed of the script, you can use a rotating proxy. A proxy stands as a middleman between you and GitHub, forwarding your requests to GitHub with a changed IP address. If you have a rotating proxy pool, you can call every request with a different IP. This will hide the fact that you’re scraping GitHub and enable you to scrape without pauses.
For an effective GitHub scraping setup, consider going for residential proxies. These proxies use real IP addresses from various locations worldwide, which makes them less likely to trigger any detection alarms compared to datacenter proxies.
In this section, you’ll learn how to add a proxy to your script. The example will use the IPRoyal residential proxy service. But no sweat if you have another proxy provider in mind – the process should be quite similar.
First, you’ll need to find the link to your proxy. If you’re using IPRoyal, you can get it from the dashboard.
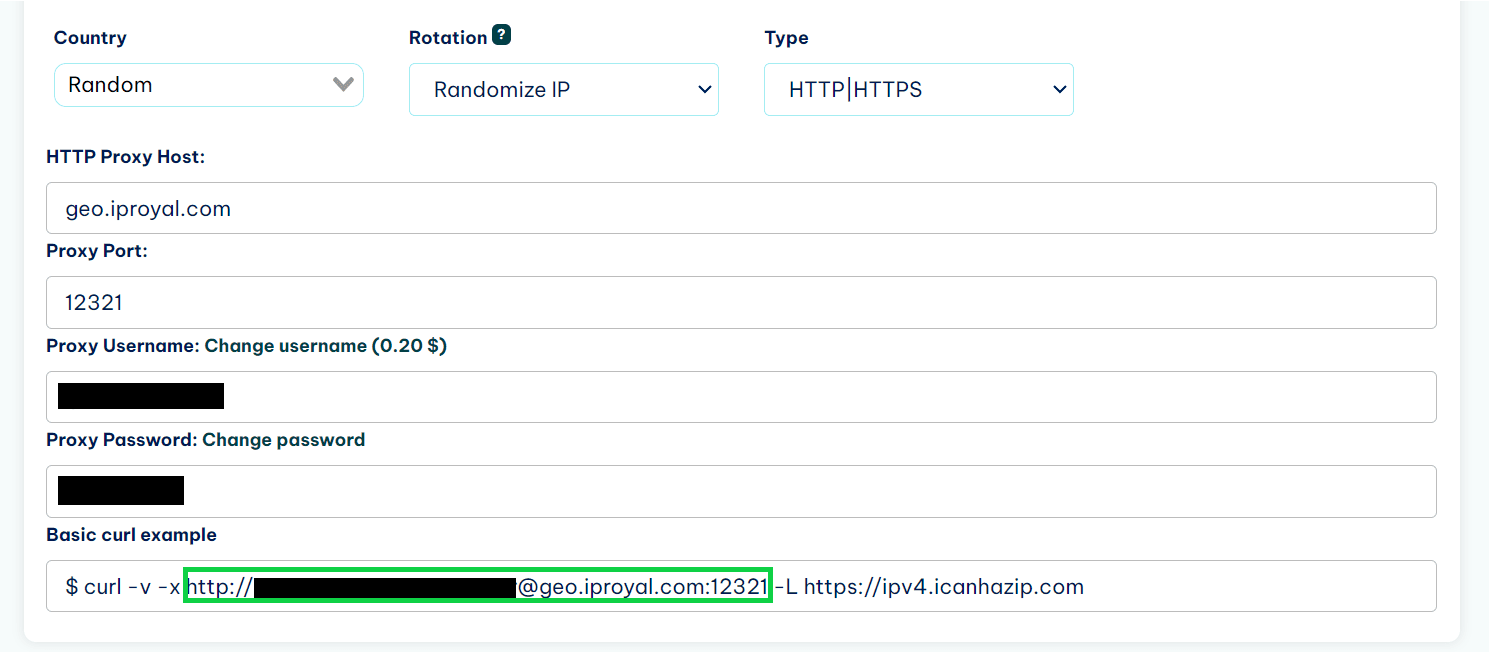
Then, create a proxies variable that holds that link.
proxies = {
'http': 'http://username:[email protected]:12321',
'https': 'http://username:[email protected]:12321',
}
Finally, add the proxies variable to the requests calls that you want to use the proxy for and remove the time.sleep() method:
for repo in repos:
url = repo['link']
response = requests.get(url, proxies=proxies)
soup = BeautifulSoup(response.text, 'html.parser')
readme = soup.select_one('div[id="readme"]').text
print(readme)
Here’s the full code of the project:
import requests
from bs4 import BeautifulSoup
url = 'https://github.com/trending/python'
proxies = {
'http': 'http://username:[email protected]:12321',
'https': 'http://username:[email protected]:12321',
}
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
repo_list = soup.find_all('article')
repos = []
for repo in repo_list:
name = repo.find('h2').text.split('/')[1].strip()
star = repo.find('svg', attrs={'aria-label': 'star'})
star_count = star.parent.text.strip()
link_stem = repo.select_one('h2>a')['href']
link = 'https://github.com' + link_stem
repo = {'name': name, 'star_count': star_count, 'link': link}
repos.append(repo)
for repo in repos:
url = repo['link']
response = requests.get(url, proxies=proxies)
soup = BeautifulSoup(response.text, 'html.parser')
readme = soup.select_one('div[id="readme"]').text
print(readme)
print(repos)
Specific Considerations
When scraping data from GitHub, there are several considerations and best practices to keep in mind to ensure that you are respectful of GitHub's terms of service and to avoid any potential issues. GitHub provides a lot of valuable data, but it’s important to do scraping responsibly and ethically, if that applies to your use case.
Here’s a few tips that can help you get the best out of scraping GitHub:
Respect rate limiting. GitHub has rate limits in place to prevent excessive or abusive scraping. It’s a nice idea to stay within these limits if it’s not necessary for your application. Nobody wants their website to be hit by thousands of requests at the same time. But if you plan to scrape large amounts of data fast, make sure to use proxies.
Cache data . Whenever possible, cache the data you retrieve to minimize the need for repetitive scraping. This can help reduce the load on GitHub's servers and improve the efficiency of your application.
Check whether using the GitHub API is not better for your use case. GitHub has an API that enables you to fetch data from the service. If you’re building an application that interfaces with GitHub, it might be easier to just use the API, which provides structured data with none of the hassle.
Potential Applications
Scraping data from GitHub can provide valuable information for a variety of applications across different domains. Here are some potential applications of scraping data from GitHub:
1. Development trend analysis. Analyzing repositories can reveal trends in use and adoption of programming languages, frameworks, or tools.
2. Academic research. Researchers can analyze codebases to study software development practices or conduct studies on open-source projects.
3. Competitor analysis. Companies can monitor their competitors' GitHub repositories to gain insights into their technology stack, product development, and open-source contributions.
4. User feedback analysis. Analyzing issues and pull requests can provide valuable user feedback and bug reports.
5. Feature request collection. Monitoring repositories can help identify feature requests and trends in user demands.
Conclusion
By scraping GitHub, you can acquire valuable data about trends in development. This information can be used for content creation, research, or marketing purposes. It’s especially important for professionals working in the areas of open-source tooling and developer relations.
FAQ
Is web scraping data from GitHub allowed according to their terms of service?
GitHub doesn’t expressively prohibit the use of web scraping and/or accounts operated by bots in their Terms of Service . But, still, to be on the safe side, it’s a good idea to be logged out and to use a proxy while scraping the site.
Can I scrape code repositories and commit history from GitHub?
Yes, the code and commit history of public repositories is publicly accessible. This means that any device from the Internet is able to connect and scrape this information.
Are there any rate limits or restrictions on scraping data from GitHub?
Like most websites, GitHub enforces rate limits on consecutive requests from one IP. If you fire too many requests in a rapid succession from one IP address, GitHub will deny the requests or even ban you. For this reason, proxies are commonly used when crawling websites. They enable you to hide your IP address and web scraping activities. To see how you can add them to your Python code, check out our advanced project section above.

