How To Scrape Data From Glassdoor
Tutorials

Arevika Ambarcumian
Key Takeaways
-
You can successfully extract job listing data and company data from Glassdoor using Python and Playwright without needing a logged-in account.
-
It's highly recommended to utilize rotating residential proxies as Glassdoor actively blocks automated traffic.
-
Your scraper must handle pagination to navigate multiple search pages, and you'll need to save the extracted data into a CSV or JSON file.
The Glassdoor website is a review site that contains valuable company data, such as employee ratings for companies, employee feedback, salary data, job listings, and interview experiences.
To access these job details, you can use a Glassdoor scraper. You’ll learn how to easily gather Glassdoor job listings data by extracting it to a CSV file when you build a scraper with tools like Python and Playwright to capture key job insights.
Recommended Techniques for Scraping Data From Glassdoor
When you try to run a Glassdoor search, you’re soon met with a pop-up that requires you to create an account and submit a review, salary data, or interview experience to continue viewing data. It might give the impression that it’s hard to scrape Glassdoor, and that you need to use a complicated set of techniques to bypass the dynamic content.
While some initial data might be embedded in the page source, Glassdoor heavily relies on dynamic JavaScript to load its content and employs strict anti-bot measures. Because a simple HTML parsing tool will often get blocked or miss dynamically loaded data, you need a more robust solution that can render JavaScript to bypass the pop-up and scrape Glassdoor effectively.
One of the best tools to use for this purpose is a Python script together with the Playwright library for browser automation. Playwright enables you to mimic a real user doing actions in the web interface, which, together with using proxies, can be good enough for most Glassdoor scraper purposes.
How to Scrape Glassdoor Using Python
We’ll focus on showing you how to scrape job listings using Python and Playwright. The same technique can also be used to gather company data.
Setup
To follow the tutorial, you’ll need to have Python installed on your computer. If you don’t already have it, you can use the official instructions to download and install it.
You’ll also need to install Playwright. Use the following commands to install the library and the browser engine that it needs.
pip install playwright
playwright install
Create a new folder called glassdoor_scraper and create a file called glassdoor_scraper.py inside it. Open it in a code editor, and you’re ready to start.
Scraping the First Jobs Page
To scrape the web page, you first need to open it using Playwright. The following code opens a new browser and navigates to the job listings page on Glassdoor.
with sync_playwright() as pw:
browser = pw.chromium.launch(
headless=False,
)
context = browser.new_context(
viewport={"width": 1920, "height": 1080}
)
page = context.new_page()
page.goto(
'https://www.glassdoor.com/Job/index.htm')
After navigating to the necessary page, you need to make the Python script fill out the search bars for your Glassdoor search.
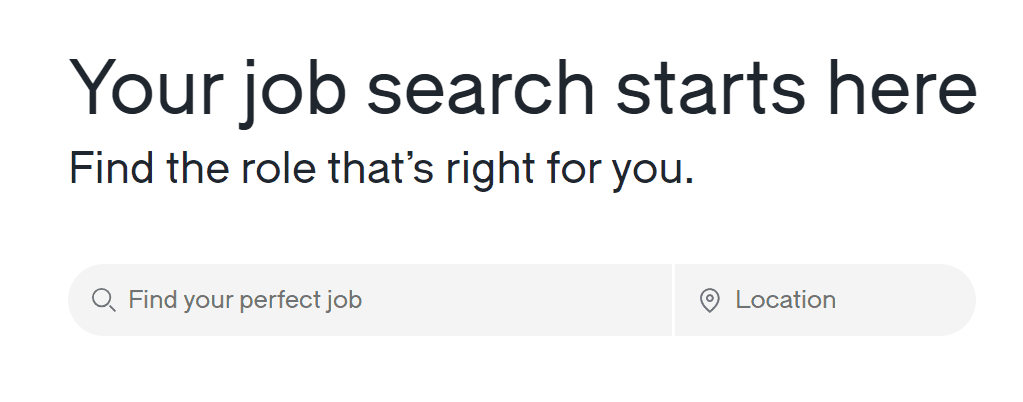
You can accomplish it with the code snippet below. It finds the job title textbox, types “Python developer” into it, then finds the country textbox, and types “Germany” into it. Then it presses the enter key and waits for the specific job listings to appear on the page.
For your purposes, you can change the “Python developer” and “Germany” strings to the job title and location you’re looking for in your Glassdoor search.
job_textbox = page.get_by_placeholder("Find your perfect job")
job_textbox.type("Python developer")
location_textbox = page.get_by_label("Search location")
location_textbox.type("Germany")
page.keyboard.press("Enter")
page.wait_for_selector('a.jobCard')
After the results have loaded, you need to scrape Glassdoor for the necessary job data from job listings. The listings are teeming with data, but for the sake of brevity, we’ll focus on scraping only the following things to include in your extracted data:
- The job title of the listing.
- The company name that published the listing.
- The company’s rating on Glassdoor.
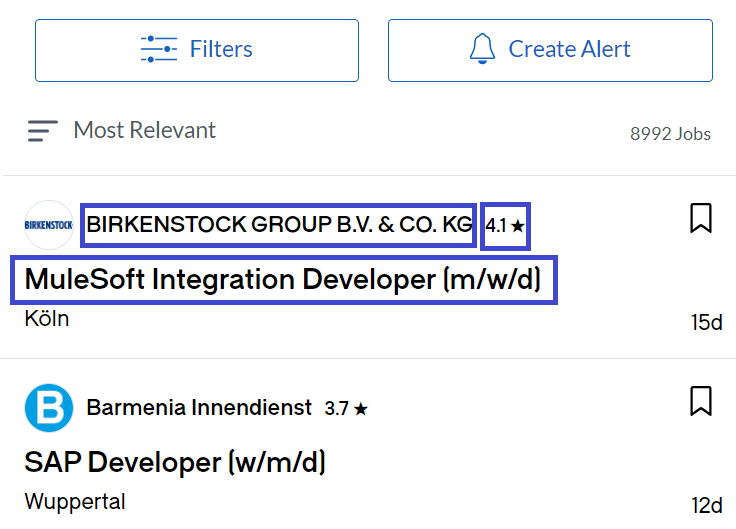
First, locate all the job cards on the page using your Glassdoor scraper:
job_boxes = page.locator('a.jobCard').all()
Then create a new array called jobs, and iterate over the job cards to scrape Glassdoor for the company information and populate the array.
For the job title and company name, you can use regular CSS selectors, which are accessible with the locator() function.
For the rating, you can use the special get_by_text() function to locate an element that has the ★ symbol. Since some of the job listings don’t have such an element, you should create an if-else statement that handles the missing piece of company data.
for job_box in job_boxes:
title = job_box.locator('div.job-title').text_content()
if job_box.get_by_text("★").is_visible():
rating = job_box.get_by_text("★").text_content()
else:
rating = "Not available"
company = job_box.locator(
"[id^=job-employer]>div:nth-child(2)").text_content().split(rating)[0]
job = {"title": title, "company": company, "rating": rating}
jobs.append(job)
Finally, print out the array and close the browser:
print(jobs)
browser.close()
Here’s the full script for convenience:
from playwright.sync_api import sync_playwright
with sync_playwright() as pw:
browser = pw.chromium.launch(
headless=False,
)
context = browser.new_context(
viewport={"width": 1920, "height": 1080}
)
page = context.new_page()
page.goto(
'https://www.glassdoor.com/Job/index.htm')
job_textbox = page.get_by_placeholder("Find your perfect job")
job_textbox.type("Python developer")
location_textbox = page.get_by_label("Search location")
location_textbox.type("Germany")
page.keyboard.press("Enter")
page.wait_for_selector('a.jobCard')
job_boxes = page.locator('a.jobCard').all()
jobs = []
for job_box in job_boxes:
title = job_box.locator('div.job-title').text_content()
if job_box.get_by_text("★").is_visible():
rating = job_box.get_by_text("★").text_content()
else:
rating = "Not available"
company = job_box.locator(
"[id^=job-employer]>div:nth-child(2)").text_content().split(rating)[0]
job = {"title": title, "company": company, "rating": rating}
jobs.append(job)
print(jobs)
browser.close()
It should print out a list of job listings such as this:
[{'title': 'Specialist Software Developer:in Python/C++ für mathematische Optimierungungen', 'company': 'Deutsche Bahn', 'rating': '3.8 ★'}, {'title': 'Web-Developer (m/w/d)', 'company': 'Allpersona GmbH', 'rating': 'Not available'} .. ]
Handling Pagination
When you build a Glassdoor scraper, you’ll inevitably need to navigate through multiple pages to collect a comprehensive dataset. Showcasing next-button detection and clicking ensures that your script doesn't stop after the initial results load.
You must define clear stop conditions, such as when the next button becomes disabled, when there are no more results displayed, or when you reach a specific page count limit. Always program your scraper to wait for selectors or a page change before proceeding.
It maximizes the amount of gathered data, though keep in mind that Glassdoor typically caps pagination at a hard limit (often around 30 pages), and you may still need proxy rotation to avoid anti-bot blocks on longer runs.
Save Results to a CSV File or JSON
After gathering your data, the next logical step is to export it into a manageable format. You can easily save your results to a CSV file using Python's built-in csv module or the Pandas library.
Optionally, you might want to add JSON Lines (NDJSON) support for large datasets, because it allows you to append records one by one without loading the entire file into memory.
Furthermore, deduplication is a necessary process to ensure data quality. You should always deduplicate by the specific Job ID (often extracted from the data-id HTML attribute on the job card) rather than the job URL, as Glassdoor frequently alters URLs with dynamic tracking parameters and is known to repeat job listings on deeper pages.
What Data to Extract From Glassdoor
Understanding which specific fields to target helps you build a more efficient scraper. The following table outlines a compact set of recommended fields, and it groups them by page type so you can organize your company data effectively.
| Page type | Recommended fields to extract |
|---|---|
| Job listings | Job title, company name, rating, location, salary information (if present), job URL, posted date, job ID |
| Company cards | Company name, company ID, rating, industry, size, location, jobs count, reviews count, salaries count, company URL |
| Reviews | Rating breakdown, date, role, pros/cons (if shown), employment status, review URL |
| Salaries | Role, pay range, location, count, last updated (if shown) |
How Can Proxies Be Used to Enhance the Efficiency and Reliability of Glassdoor Scraping?
While lightly browsing a few pages manually might not trigger Glassdoor's strict anti-scraping measures, automated scripts are frequently detected and blocked almost immediately, especially as you scale up your requests.
For example, if you want to gather a dataset of available positions for a certain job and a country over time, you will need to scrape a lot and run scripts rather frequently to get enough job data.
If you use the same IP address for large-scale web scraping as the one described, you might get interrupted by the Glassdoor website blacklisting your IP address. For this reason, web scrapers use proxies. They act as middlemen between the client and the service they want to scrape, enabling the client to hide their IP address and the number of requests they're sending to the website.
A great option for a Glassdoor scraper is to use residential proxies. They're proxies that originate from real IP addresses that are distributed all around the world. They aren't bound to trigger detection as much as proxies that come from a data center would.
Here’s how you can improve your code to add a proxy. The example code will use the IPRoyal residential proxy service , but you’re welcome to follow along if you already have a different proxy provider; there should be no big difference.
First, you'll need to find the server, username, and password information for your proxy server.
If you’re using IPRoyal proxies, you can find this information in your dashboard. The server is the concatenation of the host and port fields.

browser = pw.chromium.launch(
headless=False,
proxy={
'server':'host:port',
'username':'username',
'password': 'password123',
}
)
Now all the requests from the Playwright session will be funneled through your chosen proxy server to protect your extracted data process.
How to Scrape Glassdoor Without Coding?
Besides libraries written in programming languages like Python and JavaScript, there are a lot of no-code tools that you can use to scrape Glassdoor. While they don’t allow the same degree of customization and flexibility as a hand-written solution, they can be useful for complete beginners in web scraping.
By using these solutions, you can gather company information from Glassdoor in an intuitive manner.
Octoparse
Octoparse is a web scraping tool that allows users to extract data from websites without using any code. It provides a user-friendly interface that allows users to configure the web scraping process visually.
Users can point and click on elements of a webpage to define what data they want to extract, such as text, images, links, and more. The tool also offers various features to handle pagination, data transformation, scheduling, and exporting extracted data to various formats like Excel, a CSV file, or databases.
Apify
Apify is a powerful platform that, while built primarily for developers, offers a massive store of pre-built scrapers called Actors. For non-coders, you can simply search for a ready-made Glassdoor Scraper Actor, enter your target job titles and locations into a visual web form, and run the extraction process without writing a single line of code.
Automatio
Automatio is an automation tool to extract data from websites. It provides a no-code interface that helps people without any coding skills build cloud-based web scrapers.
What Are the Legal Considerations When Scraping Data From Glassdoor?
While web scraping publicly available, non-personal data is generally considered legal in many jurisdictions, it can still be subject to copyright protections, data privacy laws (like GDPR or CCPA), and specific regional regulations.
But when creating a Glassdoor account, you accept the terms of use, which include a clause that expressly prohibits web scraping. Therefore, there is a possibility that a Glassdoor account might be suspended or linked to your identity, which could lead to legal ramifications.
For this reason, it’s important not to log in while using your Glassdoor scraper and to use proxies while scraping.
Are There Any Limitations or Restrictions on Scraping Data From Glassdoor?
Even with a reliable proxy network, you’ll still face platform restrictions. Because you’re scraping without logging in to avoid Terms of Service violations, you’ll only be able to access publicly visible preview data.
Full company reviews and comprehensive salary histories will remain behind Glassdoor's login wall. Additionally, your script will still be subject to Glassdoor's hard pagination limits on search results.
FAQ
Is scraping data from Glassdoor allowed according to their terms of service?
Scraping data from Glassdoor is against its Terms of Use . It expressly forbids to “scrape, strip, or mine data from the services without our express written permission”. Fortunately, most of the pages that you might want to access are publicly available, which means that it is legal to scrape them.
If you do not have an account, Glassdoor cannot suspend your profile, but they utilize strict anti-bot protections (like Cloudflare) to block scrapers through IP blacklisting, CAPTCHAs, and browser fingerprinting, which means you’ll often need anti-detect browsers or fingerprint-masking tools in addition to proxies to bypass them.
Are there any rate limits or IP blocking measures in place for scraping data from Glassdoor?
Glassdoor heavily protects its site using advanced bot-management systems. Because these systems analyze your browser's technical fingerprint, your scraper can be instantly flagged and blocked on the very first request, regardless of whether you are doing large-scale or low-volume scraping for job data.
To prevent this, you must distribute traffic using rotating proxies and simulate human behavior.
Can I scrape Glassdoor reviews and ratings using proxies?
Yes, using proxies to scrape Glassdoor reviews and ratings is technically possible without an account, but keep in mind that you’ll be restricted to publicly visible preview snippets. Full employee reviews are locked behind Glassdoor's login wall, which you cannot scrape without violating their Terms of Service.
Can you scrape Glassdoor without logging in?
Yes, you can absolutely scrape Glassdoor without creating an account or logging in. In fact, accessing the public pages without an active session is highly recommended to avoid violating the logged-in user's terms of service. You’ll easily find most company name details and job postings publicly available.
Why does Glassdoor show an overlay, and how to handle it?
Glassdoor frequently displays a login overlay to encourage user registration when you browse for a specific company name. Because Glassdoor heavily relies on JavaScript to render its data dynamically, bypassing the pop-up and interacting with the site requires using a headless browser rather than just attempting to parse the raw static HTML.
How do I scrape multiple pages (pagination)?
To successfully scrape multiple pages, you must configure your script to locate and click the 'Next' button at the bottom of the search results. Furthermore, incorporating proper wait times allows the new content to load fully before your script attempts to parse the next batch of results. It prevents your scraper from missing valuable entries.
What blocks Glassdoor scraping (CAPTCHA, Cloudflare, 403/429)?
Websites deploy various anti-bot measures, and Glassdoor is no exception. Without routing your connection through proxies and masking your browser's fingerprint, you risk having your session interrupted by CAPTCHAs, rate limits, or Cloudflare blocks. Implementing a strong proxy rotation strategy, combined with stealth plugins or anti-detect browser configurations, mitigates these blocks effectively.
Datacenter vs residential proxies: which is better for Glassdoor?
Generally, rotating residential proxies are best for avoiding detection. Since residential IPs come from genuine internet service providers, they look like regular user traffic, whereas datacenter proxies are easily identified and blocked by advanced security systems.
While datacenter proxies are cheaper and offer faster connection speeds for general web tasks, their IP subnets are easily flagged by Glassdoor's security systems, making them highly ineffective for this specific target.
Consequently, investing in residential proxies ensures a smoother and more reliable extraction process when looking for a specific company name or analyzing a Glassdoor search.


