API vs. Web Scraping: Choosing the Right Data Retrieval Method
Proxy fundamentals

Vilius Dumcius
Has Google Maps ever rerouted you around traffic? That’s the power of data. The “Because you watched” recommendation on Netflix isn’t magic—it’s data. Even when your phone guesses the next word you are going to type—it’s data. We can’t list the many ways data has become a core pillar in our day-to-day lives; one article wouldn’t be enough, let alone ten.
Instead, we’ll explain the two primary ways of collecting information: APIs vs. web scraping . By reading today’s comprehensive piece, you’ll understand how these two approaches work and their use cases, making it easier to choose the right approach for extracting data from the internet. Join us below.
What Is an API?
So, let’s get right into it.
You will likely come across the term API, or application programming interface, during data collection. So what exactly is it? Think of it as a vending machine, but instead of dispensing soda, it dispenses data. You press a button, which, as you’ll see later, is making a request, and then the machine, i.e., the API, processes your input, which translates to accessing its database and dispensing the requested data.
These tools date back to the early days of the internet, back when computers were as large as a refrigerator and had computing power similar to that of a modern smartphone. Back then, APIs were mainly internal tools used by application software to communicate with the mainframe OS.
We can trace the first sophisticated remote APIs to the dot-com boom of the late ’90s and early 2000s. Salesforce is credited with launching what is widely accepted as the first modern API , allowing customers to integrate their customer relationship management tools directly into their systems.
When mobile phones and cloud computing gained mainstream traction in the 2010s, APIs became integral to powering mobile apps by allowing them to connect with servers and databases. The “API economy” emerged with companies like Stripe and Twilio offering API-first products.
As of the time of this publication in 2024, we’re in the middle of another revolution set to transform how APIs are used: the AI era. Companies like OpenAI and Google now offer APIs for artificial intelligence APIs. Examples include ChatGPT API, DALL·E API, and Whisper API, among many others.
How APIs Work
As you can probably tell by now, APIs provide an easy way for different software programs to communicate with each other. To understand how this process unfolds, let’s take a look at the different components of an API.
- Client (requester)
The software or application that sends a request to the application programming interface. This request is known as an API call. For instance, a mobile app may ask a weather API for the current temperature readings.
- API Endpoint
This is the URL or address where the API is accessible ; an example would be https://api.weather.com/v3/weather .
- Server (provider)
This is the system or application hosting the API . In our example, the weather provider’s database responds with the requested data.
Now that you know the different components API scraping, let’s look at how these programs function in practice:
- Step 1: Sending a request
The client starts the process by sending an API call to the API’s endpoint. The request will include the protocol, which we will discuss later, the headers containing critical information like authentication keys and the content type, and parameters that provide additional details about the requested information.
- Step 2: API processes the request
The server then receives the request, but before responding, it verifies that the client has the proper permissions via API keys or tokens. Once verified, it retrieves the requested data or performs the requested action.
- Step 3: Sending a response
The API then sends the structured response to the client, which includes the status code and the requested data, often in JSON format .
You must understand that the method through which the client and the server communicate via the API is governed by a set of rules known as the protocol. It ensures that the process of extracting data happens reliably and securely. Here are the different types of API protocols:
- HTTP/HTTPS (HyperText Transfer Protocol)
This is the most widely used protocol for APIs , especially for web-based interactions. It supports methods like GET to retrieve data, POST to send data to the server, PUT to update existing data, and DELETE to remove data.
- REST (Representational State Transfer)
REST uses HTTP as its foundation. It’s stateless , which means no session data is stored on the server, and it also supports XML in addition to JSON .
- SOAP (Simple Object Access Control)
SOAP is designed for structured communication using XML . One of its defining features is built-in security and error handling.
- GraphQL
GraphQL is a runtime API query language developed by Facebook . It allows clients to extract requested data in a single query to the same endpoint.
- gRPC (Google Remote Procedure Call)
This is a modern, high-performance API developed by Google . It uses Protocol Buffers for data serialization.
Types of APIs
By now, you understand the process and protocols that APIs use to extract data. You should also know that there are different types of APIs, depending on levels of access:
- Public APIs
Also known as Open APIs, these are accessible to the general public. They are designed to promote innovation and expand the ecosystem around a company’s product or service. Common examples include the Google Maps API and the Twitter API.
- Partner APIs
Unlike public APIs, partner APIs are only shared with select business partners who have agreed to specific business terms. For instance, FedEx uses APIs for package tracking, while Stripe APIs are provided to partnered top payment platforms.
- Internal APIs
As you may have guessed, these are used within a company to connect internal systems and applications.
Advantages of Using APIs
So, why use APIs? What unique advantages do they offer when compared to other data extraction methods like web scraping? Here are the advantages:
- Structured data access
One of the main advantages of using APIs for data extraction is their ability to access data in structured formats like JSON or XML.
- Security and authentication
These programs also provide mechanisms like API keys and authentication tokens that ensure only authorized users can access data or services .
- Rate limiting and quotas
To protect the server from overloading with a large number of requests, most APIs can limit the number of requests a client can make in a given time frame.
Disadvantages of Using APIs
It’s not all sunshine and roses with APIs; here are some factors that can deter you from using these programs for data extraction:
- Dependency on provider availability
When working with external APIs, the server’s uptime, updates, and long-term support decisions directly affect your access to data. If the API goes down, the features dependent on the API will be affected.
- Potential costs
Not all APIs are free to use. Most come with pricing models based on usage. So, if your application requires premium features and extensive data, costs can escalate pretty quickly.
- Limited data access scope
The decision to allow access to data is entirely dependent on the provider , and this may not always align with your application’s needs.
What Is Web Scraping?
Web scraping takes a different approach. While APIs work like vending machines, web scraping can be likened to harvesting fruit from a tree. In this case, the tree is a website, and the fruit represents publicly available data ready for extraction. So essentially, web scraping is systematically “picking” the fruit (data) from the tree (website) using automated tools.
Just like APIs, web scraping has evolved over the years. It, too, can be traced to the early days of the internet in the ’90s when the web became publicly available. Websites mainly had static HTML, and people realized that they could manually save data from web pages, the precursors to automated web scraping. But even with the simple nature of websites back then, automation was still evident as people would use simple programs to automate downloading content from multiple web pages.
When search engines like Google emerged in the early 2000s, they designed the first web crawlers to index web pages for search results. It was at this time that developers saw the potential for using the same techniques to gather specific data, hence the rise of modern web scrapers.
As the demand for data grew, developers started building web scrapers, and this was when tools like BeautifulSoup and Scrapy started being implemented for automated web scraping . When dynamic websites became mainstream in the 2010s, tools like Selenium and Puppeteer allowed web scrapers to extract data from dynamic websites as if they were real users.
Today, web scraping has become more important than ever. Artificial intelligence large language models like ChatGPT feed on data , leading to machine learning and AI to bypass anti-scraping mechanisms and analyze unstructured data.
There are two options when it comes to web scraping: custom scrapers and web scraping APIs. A custom web scraper is built in-house to extract select data, whereas a web scraping API is typically bought off the shelf to collect structured data.
How Web Scraping Works
Web scraping is all about automation, so the best way to understand how it works is by looking at the core components, which often involve tools and libraries:
- HTTP requests
The web scraper first begins by sending a request to the target website’s server to fetch the HTML content. This is done through tools like the requests library in Python or similar HTTP clients in other languages.
- HTML parsing
The next step is parsing the retrieved HTML content to locate and extract data. To do this, it will use libraries like BeautifulSoup or lxml to parse the HTML content.
- Data extraction
Once the desired data is located, the scraper will use BeautifulSoup and similar programs to parse static content and headless browsers like Selenium to extract dynamic data.
- Data storage
The web scraper will now store the extracted data in a structured format like CSV or JSON. Learn more about their key differences in our JSON vs CSV article.
- Anti-scraping mechanisms
Websites implement CAPTCHAs, rate limiting, or IP blocking to deter web scrapers. To circumvent these restrictions, use rotating residential proxies and CAPTCHA solvers.
Advantages of Web Scraping
So now that you understand what web scraping is and how it works, what benefits do you stand to gain by opting for this approach compared to APIs? Let’s find out:
- Access to vast amounts of data
You can scrape vast amounts of information using automated web scraping methods, which saves time and reduces manual effort. A web scraping API saves you the trouble and complexity of building and maintaining your own scraper while providing access to a treasure trove of information.
- Independence from API limitations
Web scraping allows you to extract data directly from a website, sidestepping the limitations of APIs. Some APIs only offer a subset of the data available on a website, whereas web scraping retrieves any publicly accessible information . To avoid API limitations, use a web scraping API to collect structured data from any public website automatically.
- Flexibility in data extraction
Whereas an API only offers access to specific data, web scraping allows access to any dataset so long as it is accessible to the public. You can even tailor your web scraper to collect only the data that you need and skip unnecessary information .
Disadvantages of Web Scraping
While it’s more flexible than using APIs for extracting data, web scraping also comes with its fair share of disadvantages. Here is what you need to know:
- Legal and ethical considerations
You must adhere to the website’s terms of service, legal frameworks, and ethical data collection principles when you scrape data using a web scraping API. Failure to do so can lead to legal disputes and bans.
- Potential for IP blocking
Many websites will ban IP addresses that send a suspicious number of data extraction requests. There are many reasons for this, including proprietary information and the protection of server resources. Use rotating residential proxies to reroute your web scraping API requests and steer clear of these restrictions.
- Data accuracy and consistency issues
It’s possible that scraped data may be incomplete, inconsistent, or include irrelevant information . For instance, a web scraper may extract product details but fail to capture dynamically loaded stock availability data.
Web Scraping vs API: A Comparison
Let’s put APIs and web scrapers side to side and determine how they fair in data collection for real-world applications:
- Data accessibility
APIs provide access to structured data through predefined endpoints, whereas web scraping can extract publicly available data in an unstructured format. So, on the one hand, you have APIs whose access to data can be limited, but the data is easier to process. On the other hand, you have web scraping, which can extract all publicly available data, but you must parse the collected information . Web scraping APIs give the best of both worlds: access to unstructured data and automation capabilities.
- Ease of implementation
Using an API is generally easier because many come with clear documentation and predictable formats. On the other hand, web scraping can be pretty complex to set up, especially for advanced use cases such as when working with dynamic content.
- Maintenance and scalability
APIs are maintained by the provider, and scaling up or down is easy with predictable usage tiers. But you can also be bogged down with downtimes and performance issues that may be out of your control . Web scrapers require regular updates, and scalability when using them requires advanced tools.
- Cost implications
Many API providers have free tiers that you can use for small-scale data extraction, but pricing can get expensive for large-scale use. For data scrapers, the cost is initially low but may incur higher costs for proxies, maintenance, and scaling.
Use Cases for APIs
As we mentioned earlier, APIs are a core to the internet ecosystem. Here are common use cases:
- E-commerce
APIs are used in online transactions to integrate payment gateways like Stripe or PayPal.
- Travel aggregators
Booking websites and applications rely on APIs from platforms such as Amadeus or Skyscanner to gather and present flight, hotel, and other travel-related data in real-time .
- Social media
Brands use APIs from platforms like Twitter and Facebook to gather data about brand mentions and user sentiment in real-time.
Use Cases for Web Scraping
Here are situations where web scraping may be more beneficial than using an API for data extraction:
- Market analysis
E-commerce platforms and other businesses use web scraping tools to extract data on competitors’ websites for pricing, promotions, and product availability.
- Price monitoring
Businesses use web scraping tools to gather pricing data from different platforms for any type of products and services, from travel fares to real estate and stock market.
- Academic research and journalism
Scholars use web scraping techniques to gather data from public datasets from government or academic institution websites.
Legal and Ethical Considerations
Because websites may contain sensitive, protected, and personal information, there are several legal and ethical considerations to keep in mind when collecting data using an API or a web scraper.
API Usage Policies
Whichever API you decide to use for data extraction, first take time to understand its usage policies. Understand how authentication works for API access—API keys and OAuth tokens.
- Rate limiting
Many APIs also have a rate limit on the number of requests that you send within a given time frame . This ensures the server resources are used efficiently.
- Terms of Service (ToS)
Don’t just skim through the terms of service and hit accept. Make sure you read and understand how the API can and cannot be used , as violations can result in legal action and bans.
Web Scraping Legalities
When using tools like a web scraping API to collect data, you need to play it by the book and adhere to several legal guidelines:
- Copyright laws and ToS violations
Just because something is visible does not necessarily mean it is free to use. Copyright laws protect the content hosted on a website as intellectual property , so if you extract this data using a custom scraper or web scraping API, you may infringe on these protections, which can lead to costly legal disputes.
- Court cases and precedents
Web scraping legality is interpreted based on several past court cases, which interpreted regulations like the Computer Fraud and Abuse Act to address key critical issues like data privacy, intellectual property, and terms of service violations.
One notable case is LinkedIn vs. HiQ Labs (2017-2023), where LinkedIn sent a cease-and-desist letter to HiQ Labs, a data analytics company, for scraping publicly accessible LinkedIn profiles. HiQ argued that the data was publicly accessible, making scraping lawful. The courts sided with HiQ, affirming that LinkedIn profiles that are not behind a login wall are publicly available, so scraping is not illegal.
In brief, you should be mindful of website policies as you scrape data. By reading the terms of service, you will know whether scraping is permitted, and even when legal, data collection should be ethical, respecting the rights of website owners, data collectors, and users.
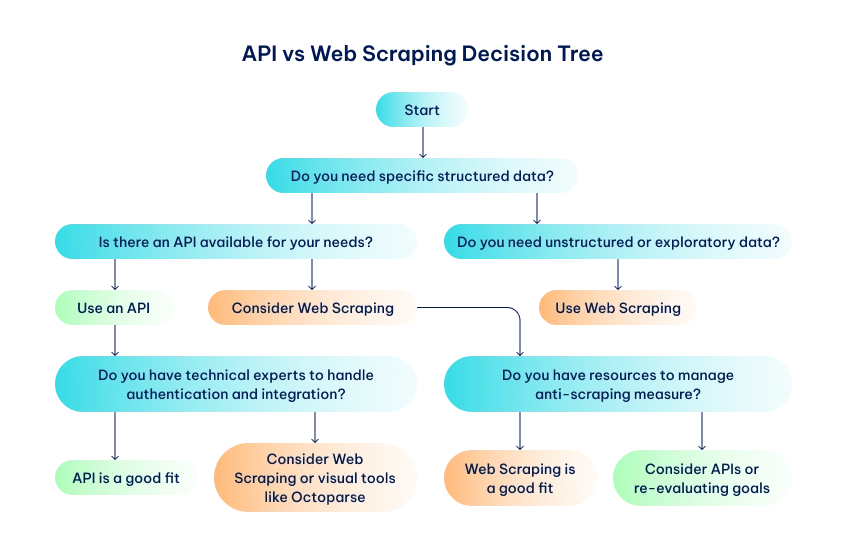
Choosing the Right Approach
Web scraping vs. API, which is the better option? By now, you know how to extract data through either of these methods, but choosing the right approach comes down to specific factors:
- Data requirements and scope
Choose API scraping when your data requirements align with what the API provides. You’ll retrieve reliable, clean, structured data, but if additional data is needed, you might need to turn to web scraping. Collecting data using scrapers gives you access to all data types as long as they are publicly accessible. Just be ready to parse unstructured information to pick out what you need . So if you require data from websites without an available API, a web scraping API might be your best option.
- Technical expertise and resources
You need some level of programming knowledge when working with both APIs and web scrapers . The difference is APIs will generally be easier to use when you have the right expertise. For web scrapers, you can opt for beginner-friendly scrapers like Octoparse and ParseHub . The expertise threshold rises when dealing with large dynamic datasets. To avoid the complexity of building an advanced scraper, it is better to use a web scraping API.
- Long-term maintenance and support
The web scraping API provider will provide long-term maintenance and support for their programs. Updates are normally announced well in advance to give users time to prepare. When working with custom scrapers, it’s your job to monitor and adapt to new anti-scraping mechanisms and update the code when the website changes its HTML structure.
Decision-Making Framework: Web Scraping vs API
- Is the data structured and predefined?
- Do you need real-time or frequently updated data?
- Is exploratory or unstructured data more important?
- Is an API available for the specific data you need?
- Are there APIs for similar datasets that could meet your requirements?
- Are web scraping APIs and frameworks suitable for the target website?
- Are you prepared to update scripts regularly (for web scraping)?
- Can you handle API versioning and deprecation?
- Do you have resources for proxies and anti-scraping measures?
- Given all that you know, which is the better option between web scraping vs API?
Conclusion
That’s a wrap! By now, you should have an easier time deciding the data extraction technique most suitable for your needs—web scraping vs. API scraping. Whichever option you use, understand the legal framework surrounding data collection at the target website and the API’s terms of service. Violating these rules can lead to costly consequences like bans and lawsuits.

