'/%3e%3cellipse%20opacity='0.34'%20cx='327.5'%20cy='339'%20rx='264.5'%20ry='264'%20fill='url(%23paint1_linear_12724_35442)'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_12724_35442'%20x1='327'%20y1='-2.524e-06'%20x2='327'%20y2='389.286'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%2327D9E5'/%3e%3cstop%20offset='0.927406'%20stop-color='%23004047'%20stop-opacity='0'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_12724_35442'%20x1='328.02'%20y1='74.7771'%20x2='328.02'%20y2='395.312'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%2327D9E5'/%3e%3cstop%20offset='0.927406'%20stop-color='%23004047'%20stop-opacity='0'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)
How to Scrape Yellow Pages Without Getting Blocked
WebsitesBuild a reliable Yellow Pages scraper with undetected-chromedriver, residential proxies, and other tools for adaptive business data scraping.


Justas Vitaitis
Key Takeaways
-
Scraping Yellow Pages is not inherently illegal if you stay within public listings and use the data responsibly.
-
To scrape Yellow Pages reliably, you need rotating residential proxies, spoofed browser identities, and human-like behavior profiles.
-
Company names, addresses, and phone numbers may need cleaning due to inconsistent formatting.
Scraping Yellow Pages is never a plug-and-play process, but setting one up is worth it. A reliable Yellow Pages data scraper provides access to business names, phone numbers, addresses, and other business details that fuel lead generation, outreach, or competitive tracking.
This article shows you how to scrape Yellow Pages data in 2026 without getting blocked and what to prepare before writing a single line of code.
Is It Legal and Worth It to Scrape Yellow Pages?
The truth is, scraping always resides in a gray area, but a case called hiQ Labs v. LinkedIn provided us with a solid foundation to work with. At one point, the courts pushed back against LinkedIn’s aggressive anti-scraping stance, suggesting that collecting data from public profiles isn’t inherently unlawful.
The outcome didn’t fully settle the debate, but it confirmed something important: just because your scraper is automated doesn’t mean it’s a hacker. What matters most is what you access and whether you’re honoring reasonable boundaries.
Most websites, including Yellow Pages, do everything they can to block you. Still, for the proper use case, extracting Yellow Pages business listing data is worthwhile. Especially if what you need is raw, structured, local business information at scale.
Think about what this directory holds: business names, telephone numbers, addresses, categories, and hours. It’s the online version of the traditional printed phone book. You can:
- Generate leads for SEO or cold outreach: Lead scraping on this website gives you a fresh pool of geo-targeted phone numbers and business details for lead campaigns.
- Track competitor listings: Yellow Pages data gives you a clear view of how your competitors show up in the directory.
But, as with everything these days, it takes some effort.
Challenges When Scraping Yellow Pages
Say you go ahead and write a simple script to scrape Yellow Pages business data. Chances are, it’s going to run into session tracking, aggressive bot detection, rotating JavaScript layouts, and hard blocks. If your scraper doesn’t account for all that, you won’t even get the chance to extract business details, let alone build anything useful.
- Rate limits and bans
You won’t get a neat little pop-up saying you’ve been banned for trying to scrape Yellow Pages. That would be way too easy. What you’re more likely to hit is a soft ban.
One minute, your web scraper is pulling business names and telephone numbers just fine. Next, you’re getting redirected to splash pages, the HTML starts shifting for no reason, or you’re served a vague “something went wrong” message that doesn’t go away.
- CAPTCHAs
Sometimes, the Yellow Pages just comes out and says it: prove you’re not a bot. That usually happens when you’re scraping too fast, your requests are too neat and linear, or you’re recycling sessions or cookies recklessly.
It can also kick in if your scraper keeps revisiting pages like it’s stuck in a loop. It’s their polite way of calling you out, but let’s be honest, they know you’re not human.
- Data consistency and cleaning
If you do manage to get past the blocks, the next thing you’ll run into is messy data. You may see small businesses with slightly different names, telephone numbers in different formats, and business addresses split or jumbled, depending on the page.
Sometimes the business information may be duplicated with subtle changes, and sometimes it’s missing key fields entirely.
Now let’s discuss how you’ll actually overcome the challenges we just walked through. First, you get your tools in place. Then we’ll break down the logic that powers a scraper that doesn’t get blocked or trip over inaccurate data.
- Residential proxies
Start with a small pool of residential proxies . Make sure the proxy location matches your target. If you’re scraping roofing contractors in Los Angeles, you don’t want your IP address showing up in Nepal.
The Yellow Pages typically display around 50 listings per page. In light scraping, a single proxy might work. But if you encounter rate limits or soft blocks, you’ll need to rotate. As a rule of thumb, running two to five rotating proxies per active page is usually sufficient to stay under the radar.
Global Pool, Precise Targeting, Zero Contracts
Premium Residential Proxies
- Undetected-chromedriver
You’re using undetected-chromedriver because it removes the fingerprint giveaways that trigger bot detection on Yellow Pages. It doesn’t make you invisible, but it keeps your scraper from revealing itself before it even loads the first listing.
- Python
You’ll need Python installed, preferably the latest version. Most scraping scripts today are written in Python due to its ease of integration with Selenium, proxy rotation, and data processing.
- Code editor
Finally, you’ll need a code editor. It doesn’t matter if it’s VS Code, Sublime, or anything else. You’ll use it to write, test, and iterate your scraper until it performs as needed.
What Data Can You Extract From Yellow Pages?
Your scraper can gather the following data when properly configured:
- Business name
This is the anchor of your scraping stack. But Yellow Pages listings don’t follow strict naming conventions. You’ll see slight variations in abbreviations, legal suffixes, or typos that make it hard to treat names as unique identifiers. You’ll need to normalize these if you’re building anything off company names.
- Business address
You’ll get the full address, but the structure isn’t reliable. Sometimes it’s broken into a street, city, and state. Other times, it’s a single long string with inconsistent separators. Yellow Pages doesn’t enforce a single format, so your scraper needs logic to detect and clean addresses that come jumbled or incomplete.
- Telephone number
This is the data you probably need the most. However, the formatting is often inconsistent. Some Yellow Pages business numbers use dashes, others parentheses, and some include country codes, while others do not.
- Website
Not every listing has one, but when it’s there, it’s usually in a clean anchor tag. Sometimes you’ll find third-party pages instead of official domains. If your goal is to scrape business websites for deeper crawling, plan for some noise.
Step-By-Step Guide to Scraping Yellow Pages
So, here’s what really brought you here: we’re going to build a scraper that collects company names and telephone numbers for roofing contractors in Los Angeles.
Step 1: Install Dependencies
You are going to need just a few tools to get this scraper running:
- Python: This is the language you’ll write everything in. Use the latest version (3.9 or higher is recommended) to avoid compatibility issues.
- Selenium: Even though we’re using undetected-chromedriver, it’s built on top of Selenium, so this is required
- Undetected-chromedriver: This is the stealth layer. It hides navigator.webdriver, patches WebGL, AudioBuffer, and canvas fingerprints to bypass bot detection.
Installing Python
Step 1: Open Command Prompt or Terminal and type:
Python --version
If it returns something like Python 3.11.5, you're good to go.
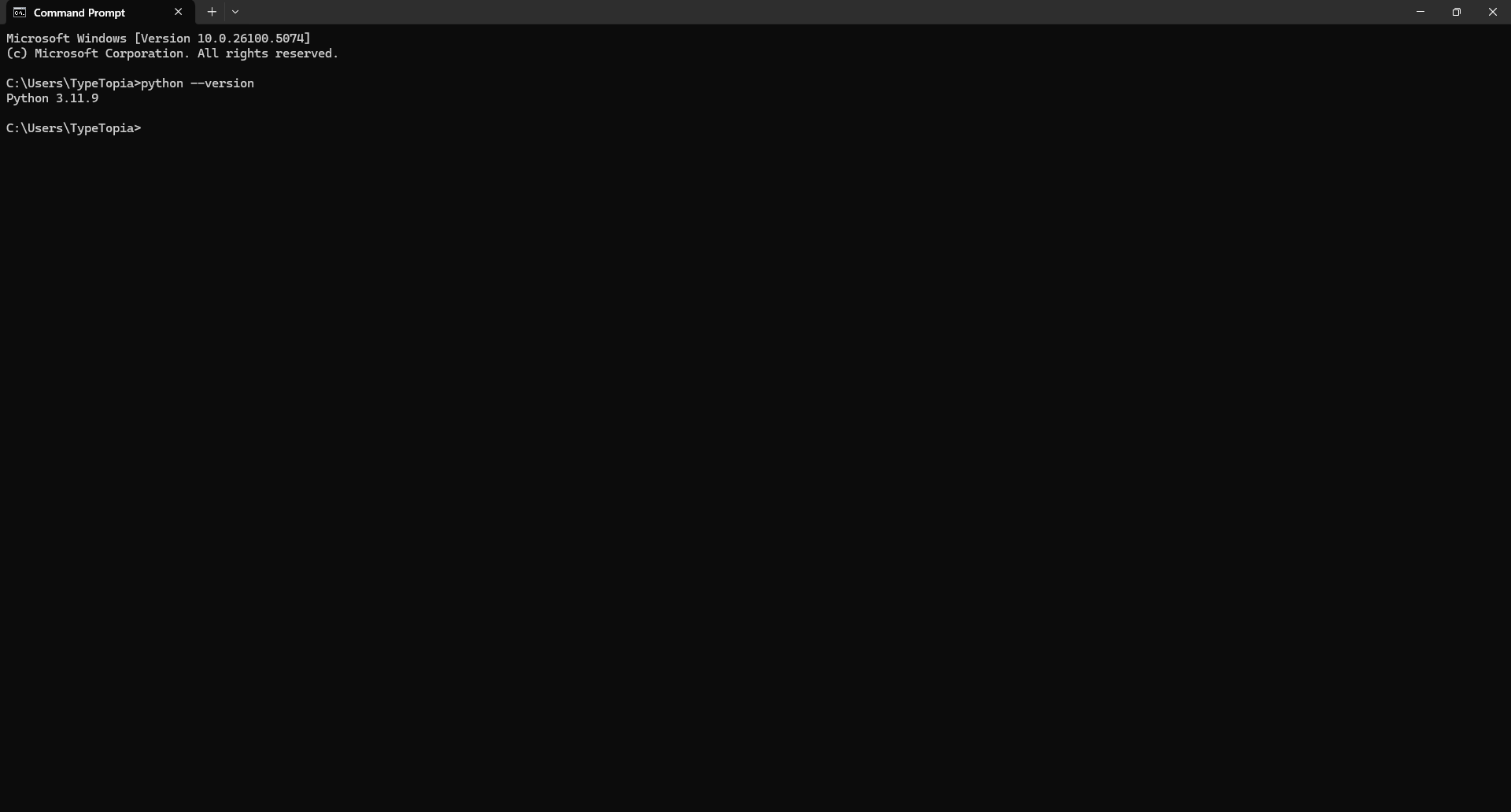
If not, download the latest version from Python.org . During setup, check the box that says “Add Python to PATH.” That part matters.
Installing Selenium
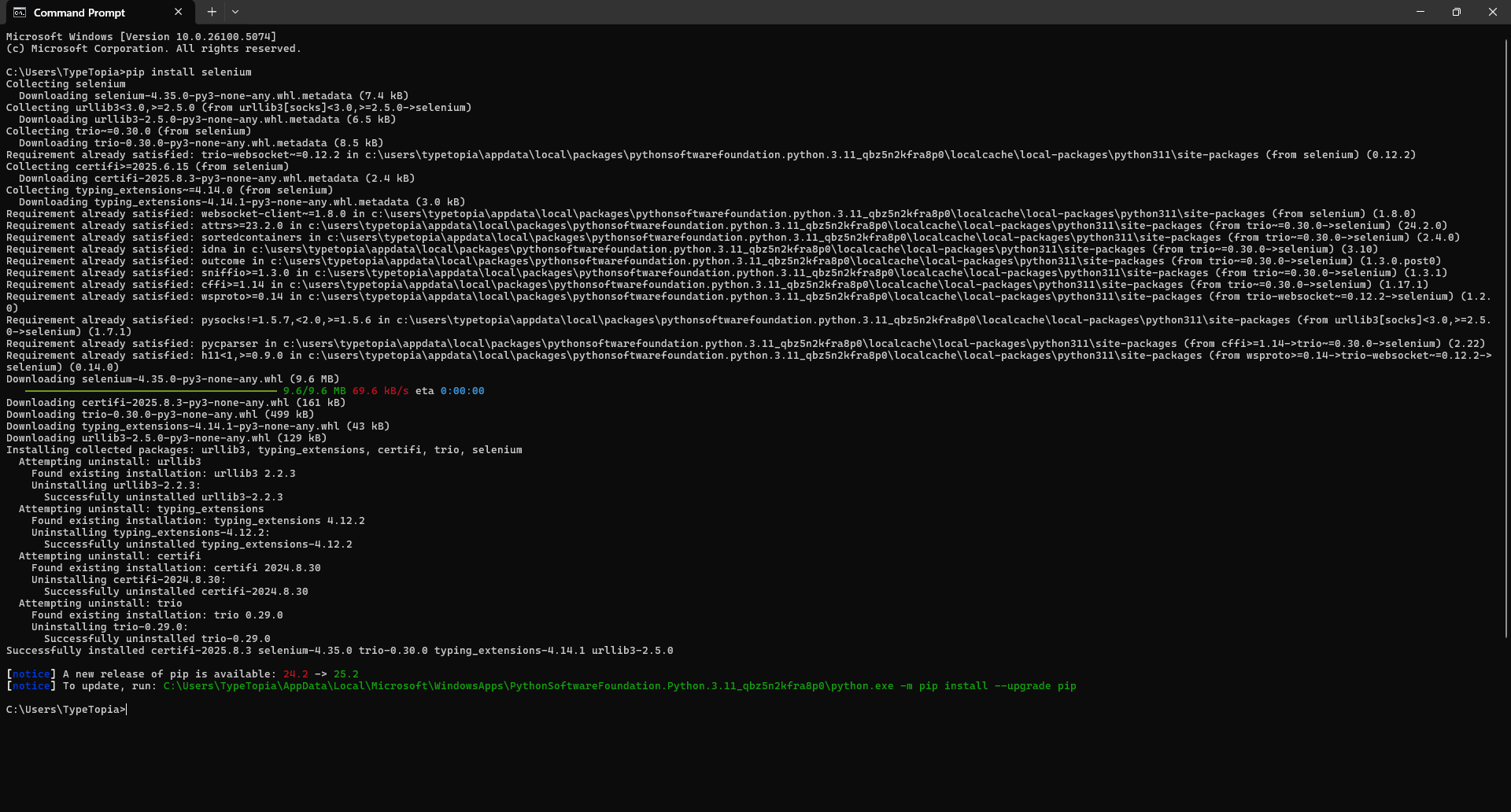
Still in your Command Prompt or Terminal, write this command:
pip install selenium
It should take a minute or two to download and install.
Installing Undetected-Chromedriver
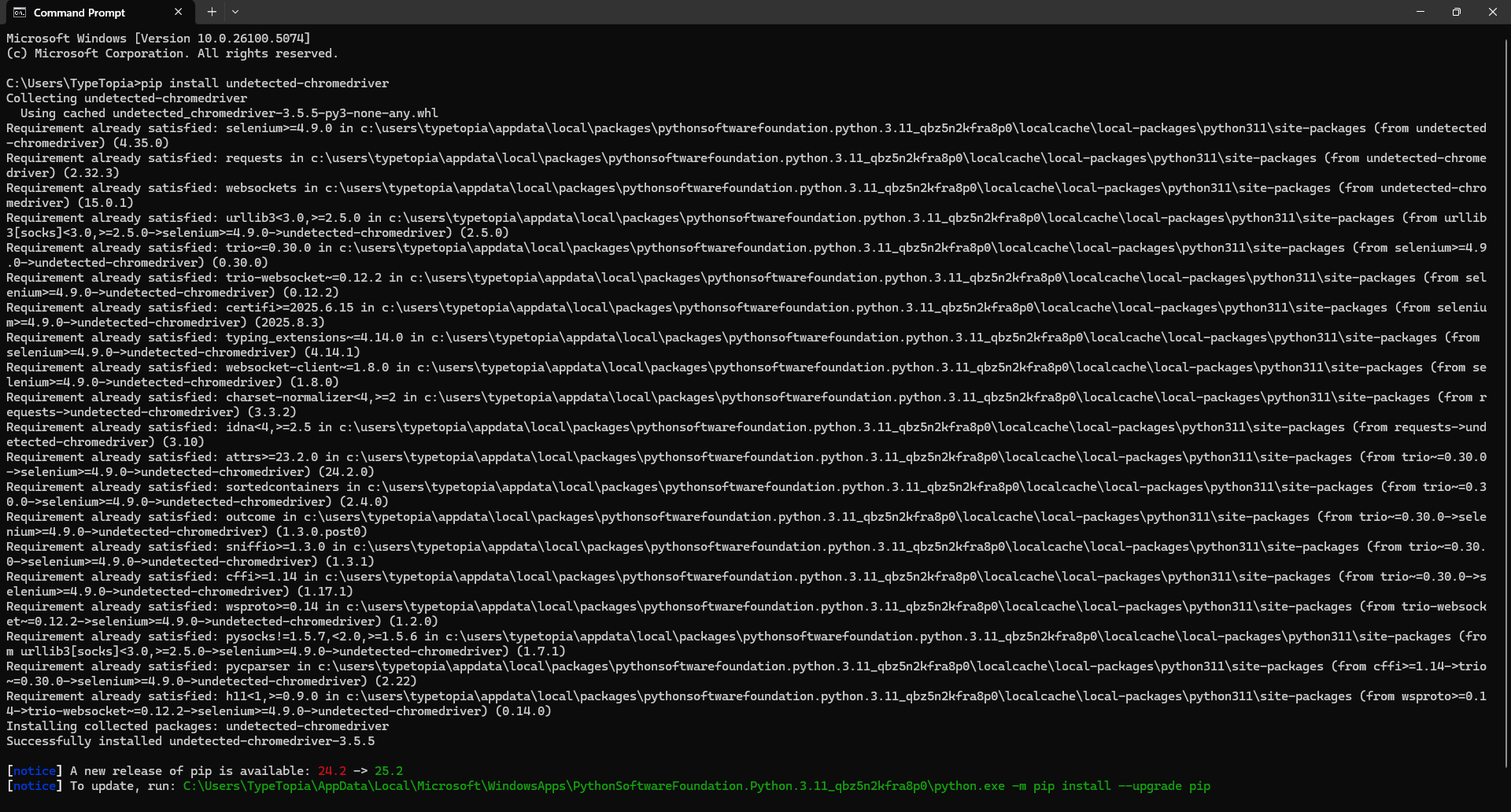
Run the following command in your terminal:
pip install undetected-chromedriver
It should take a minute or two to download and install.
That’s it, you now have all the prerequisites installed. Now let’s create the Python file.
Step 2: Create and Store Your Yellow Pages Scraper
Let’s keep things simple and store your scraper on the Desktop. In your Command Prompt, type:
cd %USERPROFILE%\Desktop & mkdir yellowpages-scraper & cd yellowpages-scraper
This opens your Desktop folder, creates a subfolder called yellowpages-scraper, and puts you inside it. Let's name our file 'YellowPageExtractor'. Use the following command to create it:
type nul > YellowPageExtractor.py
Now, open the file we just created in your favorite code editor so we can start writing code.
Step 3: Write Your Import Statements
The first step is to import the modules that we need. Here they are:
#Browser Control & Stealth Automation
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.desired_capabilities import DesiredCapabilities
import undetected_chromedriver as uc
#Proxy, Fingerprint & Spoofing Logic
import time
import random
import os
import sys
import uuid
import logging
import itertools
import re
import base64
# Alerting & Output
import smtplib
from email.message import EmailMessage
from email.mime.text import MIMEText
import csv
import json
import pandas as pd
from datetime import datetime
Browser Control and Stealth Imports
This first group of imports enables your scraper to behave like a real person using a browser. Each one serves a specific role in making that behavior believable.
- from selenium.webdriver.common.by import By
This tells the scraper what kind of locator it will use to find elements. Whether it's an ID, class, or CSS selector, this line lays the groundwork for grabbing names and phone numbers from Yellow Pages.
- from selenium.webdriver.common.keys import Keys
We will use this to simulate keyboard actions such as typing, pressing Enter, or correcting a typo. This is part of what makes the bot look human.
- from selenium.webdriver.common.action_chains import ActionChains
This allows your scraper to move the mouse, hover over elements, or pause briefly before clicking. These tiny actions help it avoid standing out.
- from selenium.webdriver.support.ui import WebDriverWait and from selenium.webdriver.support import expected_conditions as EC
Together, these give the bot the ability to wait until something is actually on the page before interacting with it. That means it doesn't click on a search button before the page is ready.
- from selenium.webdriver.chrome.options import Options
This brings up the settings menu for how Chrome should behave. You will use it to set the language, screen size, and turn off any features that might trigger detection.
- import undetected_chromedriver as uc
This is the core of your stealth setup. It launches a modified version of Chrome that hides most signs of automation. Without it, Yellow Pages would likely block you before the first result even loads.
Anti-bot and Spoofing Utilities
The next set of imports provides your scraper with adaptive intelligence. With these tools, it can behave unpredictably and respond to what it sees in real time.
- import time and import random
Grouped because they always work as a pair. Time.sleep() is our delay engine. It creates pauses between actions so the bot doesn’t move at machine speed. Random adds jitter to those delays, making them feel more human and less predictable.
- Import os and import sys
These give the scraper control over the environment it's running in. Os handles file-level tasks, such as checking if our output CSV exists. Sys lets us exit the script cleanly if stealth checks fail or scraping hits a dead end.
- import uuid
We will use this to generate unique values, such as session IDs, cookie markers, or temp filenames. It keeps each run distinct and harder to fingerprint.
- import logging
Replaces messy print() calls with structured, timestamped logs. This lets us track what the scraper is doing, when it fails, and why.
- import re
Brings in Python’s regular expression engine. You’ll use it in extract_timezone() to extract the city or state from proxy strings and map them to time zones.
Data Logging and Output
This set of imports powers our output logging system:
- import csv
Used to write the scraped company data into a structured CSV file.
- from datetime import datetime
Adds a timestamp to each entry so we know exactly when each record was logged.
Step 4: Configure Logging
We already imported logging to track what the scraper is doing. Now we configure it with this line:
logging.basicConfig(level=logging.INFO, format='[%(asctime)s] %(message)s')
This sets up Python’s built-in logging system to only display messages at INFO level or higher. It also formats each log entry with a timestamp, so you can see exactly when each action occurs.
Step 5: Set Up Global Settings
We’re almost done laying the groundwork. This step defines the key configuration variables that control how your scraper behaves during execution. Add the following lines to your script:
# Global Settings
HEADLESS = False # Set to True later if you spoof it correctly
MAX_RETRIES = 5
BLOCK_BACKOFF_STEPS = [5, 10, 20, 30] # seconds
- HEADLESS
Set to False so you can see Chrome as it runs. Once everything is set up and you’re ready to go stealth, switch it to True to run headlessly in the background.
- MAX_RETRIES
Defines the number of times the scraper should retry after encountering a block or error. Right now, it’s set to five attempts before giving up.
- BLOCK_BACKOFF_STEPS
Controls how long the scraper waits between retries. It starts with 5 seconds and increases with each failure to reduce detection risk.
Step 6: Format Your Proxy String
Because we’re scraping listings for roofing contractors in Los Angeles, it makes sense to route all traffic through Los Angeles-based proxies. Yellow Pages listings are geo-targeted, meaning your search results depend heavily on where your IP address appears to be located.
We're using Residential Proxies for this purpose. Here is our pool:
#Proxy pool
PROXIES = [
"http://geo.iproyal.com:12321/country-us_city-losangeles_session-TCDPEKCM_lifetime-30m",
"http://geo.iproyal.com:12321/country-us_city-losangeles_session-ZbgnB6u4_lifetime-30m",
"http://geo.iproyal.com:12321/country-us_city-losangeles_session-wrAACjQS_lifetime-30m",
"http://geo.iproyal.com:12321/country-us_city-losangeles_session-EE8Rhsih_lifetime-30m",
"http://geo.iproyal.com:12321/country-us_city-losangeles_session-fGo0pPHi_lifetime-30m",
"http://geo.iproyal.com:12321/country-us_city-losangeles_session-7JrqLZN2_lifetime-30m",
"http://geo.iproyal.com:12321/country-us_city-losangeles_session-mCRJTcks_lifetime-30m",
"http://geo.iproyal.com:12321/country-us_city-losangeles_session-51dDpfgf_lifetime-30m",
"http://geo.iproyal.com:12321/country-us_city-losangeles_session-Ve2WXTEV_lifetime-30m",
"http://geo.iproyal.com:12321/country-us_city-losangeles_session-jurD1lGK_lifetime-30m"
]
Each proxy follows this format:
[ADDRESS]:[PORT]:[LOCATION/SESSION ID]
We don’t pass usernames or passwords directly in the proxy string. This approach simplifies authentication and avoids compatibility issues with undetected-chromedriver, which doesn’t always play well with proxies requiring inline credentials.
Instead, we use IP whitelisting. This means we pre-authorize the IP address of our scraping machine directly in the IPRoyal dashboard.
Step 7: Create a Time Zone Lookup Table
This is part of our stealth layer. We've already defined a pool of 10 unique Los Angeles residential proxies, but that alone isn’t enough.
If your proxy indicates you're in LA but your browser's time zone shows India, a site like Yellow Pages can flag the discrepancy. So we need a way to translate the proxy’s location into the correct time zone.
That’s what the following line does:
TIMEZONE_MAP = {
"city-losangeles": "America/Los_Angeles"
}
It maps the city tag from your proxy to a real time zone. Later, when we extract "city-losangeles" from the proxy string, this lookup informs the scraper to set the browser clock to "America/Los_Angeles", ensuring everything remains aligned.
Step 8: Match Proxy Location to the Right Time Zone
We’ve already defined our proxy pool and the time zone lookup table. Now we need a translator that connects the two, so our scraper knows what time zone to assign based on the proxy.
That’s where this function comes in:
def extract_timezone(proxy_string):
match = re.search(r"(city|state)-([a-z]+)", proxy_string)
if not match:
raise ValueError(f"Could not extract location from: {proxy_string}")
loc_key = f"{match.group(1)}-{match.group(2)}"
timezone = TIMEZONE_MAP.get(loc_key)
if not timezone:
raise ValueError(f"No timezone mapped for: {loc_key}")
return timezone
Here’s what it does:
- Takes the whole proxy string as input.
- Uses a regular expression to extract the city or state, like "city-losangeles."
- If it doesn’t find a valid location, it raises an error, so you can check your proxy formatting.
- It then builds the key for our lookup table and checks if there’s a matching time zone.
- If there’s no match, it raises another error to help you debug.
- If all goes well, it returns the correct time zone string, ready to be used to set the browser clock.
This is a small but essential step in making sure your browser and proxy match.
Step 9: Define Your Identity Pool
We’re still building stealth. It’s all about closing tiny leaks that could reveal we’re not human. You won’t patch everything, but you’ll get close enough for your scraper to remain under the radar.
The identity pool below gives your scraper multiple browser “costumes” to wear. Each one looks, feels, and behaves like a real person using a real device in Los Angeles. You can always tweak or expand it to fit your project.
# Identites to use
IDENTITY_POOL = [
{
"identity_id": "la_win_edge_01",
"device_group": "desktop-windows",
"timezone": "America/Los_Angeles",
"user_agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.6422.113 Safari/537.36 Edg/125.0.2535.67",
"viewport": (1920, 1080),
"platform": "Win32",
"hardware_concurrency": 8,
"max_touch_points": 0,
"webgl_vendor": "Intel Inc.",
"webgl_renderer": "Intel UHD Graphics 770"
},
{
"identity_id": "la_mac_safari_02",
"device_group": "desktop-mac",
"timezone": "America/Los_Angeles",
"user_agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 13_5_2) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/17.0 Safari/605.1.15",
"viewport": (1680, 1050),
"platform": "MacIntel",
"hardware_concurrency": 8,
"max_touch_points": 0,
"webgl_vendor": "Apple Inc.",
"webgl_renderer": "Apple M2 Pro GPU"
},
{
"identity_id": "la_linux_chrome_03",
"device_group": "desktop-linux",
"timezone": "America/Los_Angeles",
"user_agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.6367.119 Safari/537.36",
"viewport": (1600, 900),
"platform": "Linux x86_64",
"hardware_concurrency": 4,
"max_touch_points": 0,
"webgl_vendor": "Mesa/X.org",
"webgl_renderer": "Mesa Intel(R) Arc A380 Graphics (DG2)"
},
{
"identity_id": "la_win_chrome_04",
"device_group": "desktop-windows",
"timezone": "America/Los_Angeles",
"user_agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.6312.86 Safari/537.36",
"viewport": (1366, 768),
"platform": "Win32",
"hardware_concurrency": 6,
"max_touch_points": 0,
"webgl_vendor": "NVIDIA Corporation",
"webgl_renderer": "NVIDIA GeForce GTX 1660"
},
{
"identity_id": "la_mac_firefox_05",
"device_group": "desktop-mac",
"timezone": "America/Los_Angeles",
"user_agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 12.6) Gecko/20100101 Firefox/117.0",
"viewport": (1440, 900),
"platform": "MacIntel",
"hardware_concurrency": 4,
"max_touch_points": 0,
"webgl_vendor": "ATI Technologies Inc.",
"webgl_renderer": "AMD Radeon Pro 560 OpenGL Engine"
},
{
"identity_id": "la_linux_firefox_06",
"device_group": "desktop-linux",
"timezone": "America/Los_Angeles",
"user_agent": "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:126.0) Gecko/20100101 Firefox/126.0",
"viewport": (1920, 1080),
"platform": "Linux x86_64",
"hardware_concurrency": 8,
"max_touch_points": 0,
"webgl_vendor": "X.Org",
"webgl_renderer": "Radeon RX 6600 (DRM 3.40.0)"
},
{
"identity_id": "la_win_ie_compat_07",
"device_group": "desktop-windows",
"timezone": "America/Los_Angeles",
"user_agent": "Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; Trident/6.0)",
"viewport": (1024, 768),
"platform": "Win32",
"hardware_concurrency": 2,
"max_touch_points": 0,
"webgl_vendor": "Microsoft",
"webgl_renderer": "Microsoft Basic Render Driver"
},
{
"identity_id": "la_mac_chrome_08",
"device_group": "desktop-mac",
"timezone": "America/Los_Angeles",
"user_agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 11_2_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.6099.110 Safari/537.36",
"viewport": (1280, 800),
"platform": "MacIntel",
"hardware_concurrency": 4,
"max_touch_points": 0,
"webgl_vendor": "Apple Inc.",
"webgl_renderer": "Apple M1 GPU"
},
{
"identity_id": "la_win_firefox_09",
"device_group": "desktop-windows",
"timezone": "America/Los_Angeles",
"user_agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:115.0) Gecko/20100101 Firefox/115.0",
"viewport": (1360, 768),
"platform": "Win32",
"hardware_concurrency": 4,
"max_touch_points": 0,
"webgl_vendor": "Google Inc.",
"webgl_renderer": "ANGLE (Intel, Intel HD Graphics 630, Direct3D11 vs_5_0 ps_5_0)"
},
{
"identity_id": "la_linux_edge_10",
"device_group": "desktop-linux",
"timezone": "America/Los_Angeles",
"user_agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.6422.113 Safari/537.36 Edg/125.0.2535.67",
"viewport": (1536, 864),
"platform": "Linux x86_64",
"hardware_concurrency": 4,
"max_touch_points": 0,
"webgl_vendor": "Google Inc.",
"webgl_renderer": "ANGLE (NVIDIA, GeForce RTX 3070, Direct3D11 vs_5_0 ps_5_0)"
}
]
Let's pick the first one apart:
- identity_id: Just a nickname for debugging. It helps you track which persona is active.
- device_group: The type of device we’re simulating. In this case, a Windows desktop.
- timezone: Tied to your proxy’s location. Here, it’s set to match a Los Angeles IP.
- user_agent: What the browser claims to be. This one mimics Edge on Windows.
- viewport: The screen resolution. This identity uses full HD: 1920x1080.
- platform: Another JavaScript fingerprint - this tells the site we’re on Win32.
- hardware_concurrency: How many CPU cores the browser exposes (JavaScript level).
- max_touch_points: Tells sites how many fingers the device supports. 0 = no touchscreen.
- webgl_vendor + webgl_renderer: GPU fingerprints. These must match your virtual setup to avoid flags.
You can use this as a starting point to build your own identity list. Just make sure to mix in a variety of OS, browsers, and hardware to help your scraper look like dozens of different real people.
Step 10: Define a Function to Pair a Proxy With a Matching Identity
The next step is to define a function that selects a random proxy from your proxy pool and pairs it with a browser identity from your identity pool, but only after verifying that both share the same time zone. Use the following function:
# Proxy assignment and identity logic
def assign_proxy_and_identity():
proxy = random.choice(PROXIES)
logging.info(f"Selected proxy: {proxy}")
try:
timezone = extract_timezone(proxy)
except ValueError as e:
logging.error(f"Failed to extract timezone: {e}")
raise
# Filter identities by matching timezone
matching_identities = [idn for idn in IDENTITY_POOL if idn["timezone"] == timezone]
if not matching_identities:
logging.error(f"No identities found for timezone: {timezone}")
raise Exception(f"No identities match timezone: {timezone}")
identity = random.choice(matching_identities)
logging.info(f"Assigned identity with user agent: {identity['user_agent']}")
return proxy, identity
Here’s what it does:
- Selects a random proxy from your PROXIES list.
- Logs which proxy was chosen.
- Extracts the time zone from the proxy string using extract_timezone().
- Filters your identity pool for matches with the same time zone.
- If no match is found, it raises an error.
- Otherwise, it picks one identity at random.
- Logs the assigned identity’s user agent.
- Returns the matched proxy and identity pair.
This makes sure your scraper presents a consistent and believable browser profile that aligns with the geographic location of your proxy.
Step 11: Define Behavior Profiles for Stealth Scraping
To help your scraper stay undetected, define a list of behavior profiles that control how it interacts with the page. Each profile simulates a different type of user by tweaking things such as scroll speed, typing style, and mouse movement. Here’s the full list. You can customize or expand it as needed:
# Each profile defines timing, interaction, and navigation tendencies
BEHAVIOR_PROFILES = [
{
"name": "Fast Clicker",
"base_delay": 0.5,
"scroll_pattern": "none",
"hover_before_click": False,
"re_click_probability": 0.05,
"slow_typing": False,
"move_mouse_between_actions": True,
},
{
"name": "Deliberate Reader",
"base_delay": 2.5,
"scroll_pattern": "linear",
"hover_before_click": True,
"re_click_probability": 0.02,
"slow_typing": True,
"move_mouse_between_actions": True,
},
{
"name": "Back-and-Forth Browser",
"base_delay": 1.2,
"scroll_pattern": "jittery",
"hover_before_click": True,
"re_click_probability": 0.1,
"slow_typing": True,
"move_mouse_between_actions": True,
},
{
"name": "Precise Shopper",
"base_delay": 1.0,
"scroll_pattern": "none",
"hover_before_click": False,
"re_click_probability": 0.01,
"slow_typing": True,
"move_mouse_between_actions": True,
},
{
"name": "Researcher",
"base_delay": 2.0,
"scroll_pattern": "linear",
"hover_before_click": True,
"re_click_probability": 0.03,
"slow_typing": True,
"move_mouse_between_actions": True,
},
{
"name": "Curious Clicker",
"base_delay": 1.7,
"scroll_pattern": "jittery",
"hover_before_click": True,
"re_click_probability": 0.2,
"slow_typing": False,
"move_mouse_between_actions": True,
},
{
"name": "Hesitant User",
"base_delay": 3.0,
"scroll_pattern": "none",
"hover_before_click": True,
"re_click_probability": 0.0,
"slow_typing": True,
"move_mouse_between_actions": True,
},
]
Each profile includes these core elements:
- name: A simple nickname to identify the profile in logs or during tests.
- base_delay: The base wait time (in seconds) between actions like typing, clicking, or scrolling. A value like 0.5 simulates a fast user, while higher values mimic slower, more deliberate interaction.
- Scroll_pattern: Controls whether and how the scraper scrolls the page. Options like "linear" or "jittery" simulate browsing, while "none" skips scrolling entirely.
- Hover_before_click: If set to True, the bot will briefly hover over elements before clicking, mimicking natural user behavior.
- Re-click_probability: Adds randomness by allowing the bot to occasionally click the same button twice, just like a real user might.
- Slow_typing: If enabled, simulates human-like keystroke delays instead of typing everything instantly.
- Move_mouse_between_actions: When True, the bot moves the mouse cursor between actions to avoid looking robotic.
These profiles add unpredictability and variation, which helps your scraper bypass detection.
Step 12: Define a Function to Pick a Random Behavior Profile
To make each session act like a unique user, we define a function that randomly selects one of the behavior profiles we created earlier.
# Function to randomly select a behavior profile for a session
def assign_behavior_profile():
return random.choice(BEHAVIOR_PROFILES)
This function pulls a random user behavior style, such as ‘Fast Clicker’ or ‘Deliberate Reader’, ensuring that every scraping run behaves slightly differently.
Step 13: Prepare Your CSV File for Output
Let’s set up a clean CSV file to store your scraping results. This function checks if yellowpages_data.csv already exists. If not, it creates it and adds column headers for timestamp, name, and phone.
ef initialize_csv():
filename = "yellowpages_data.csv"
if not os.path.exists(filename):
with open(filename, mode="w", newline="", encoding="utf-8") as f:
writer = csv.writer(f)
writer.writerow(["timestamp", "name", "phone"])
That’s it, groundwork’s done. Now it’s time to start building the scraping logic.
Step 14: Launch Your Stealth Browser
Time to build the heart of your bot: the undetected browser launcher. This function spins up a stealth Chrome instance patched against major fingerprint leaks, helping you stay invisible to anti-bot systems.
def launch_stealth_browser(proxy: str, identity: dict):
"""
Launch a stealthy undetected Chrome browser instance with proxy and identity settings applied.
"""
# Extract proxy credentials and IP
proxy_address = proxy.split("/")[2] # Extracts 'geo.iproyal.com:12321'
proxy_address = proxy.split("/")[2] # Gets host:port from your whitelisted proxy string
# Stealthy browser options
options = uc.ChromeOptions()
options.add_argument(f'--proxy-server=http://{proxy_address}')
options.add_argument(f"--window-size={identity['viewport'][0]},{identity['viewport'][1]}")
options.add_argument(f"--lang=en-US,en;q=0.9")
options.add_argument("--disable-blink-features=AutomationControlled")
options.add_experimental_option("prefs", {
"credentials_enable_service": False,
"profile.password_manager_enabled": False
})
if HEADLESS:
options.add_argument("--headless=new")
# Start undetected Chrome driver
driver = uc.Chrome(options=options)
driver.execute_script("window.localStorage.setItem('bb_test_key', 'value');")
driver.execute_script("window.sessionStorage.setItem('bb_test_key', 'value');")
driver.execute_script("document.cookie = 'bb_user_sim=1234567; path=/';")
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": f"""
Object.defineProperty(navigator, 'webdriver', {{get: () => undefined}});
Object.defineProperty(navigator, 'userAgent', {{get: () => "{identity['user_agent']}" }});
Object.defineProperty(navigator, 'platform', {{get: () => "{identity['platform']}" }});
Object.defineProperty(navigator, 'hardwareConcurrency', {{get: () => {identity['hardware_concurrency']} }});
Object.defineProperty(navigator, 'maxTouchPoints', {{get: () => {identity['max_touch_points']} }});
Object.defineProperty(navigator, 'languages', {{get: () => ['en-US', 'en'] }});
Object.defineProperty(navigator, 'language', {{get: () => 'en-US' }});
"""
})
# Enable DevTools protocol
driver.execute_cdp_cmd("Page.enable", {})
# Add fake chrome.runtime support
driver.execute_cdp_cmd("Runtime.evaluate", {
"expression": "Object.defineProperty(navigator, 'chrome', { get: () => ({ runtime: {} }) });"
})
driver.execute_script("""
Object.defineProperty(navigator, 'plugins', {
get: () => [1, 2, 3, 4, 5]
});
Object.defineProperty(navigator, 'mimeTypes', {
get: () => [1, 2, 3]
});
navigator.mediaDevices = {
enumerateDevices: () => Promise.resolve([
{ kind: 'audioinput', label: 'Built-in Microphone' },
{ kind: 'videoinput', label: 'Integrated Camera' }
])
};
Object.defineProperty(screen, 'colorDepth', {
get: () => 24
});
""")
# Proxy authentication via DevTools Protocol
driver.execute_cdp_cmd('Network.enable', {})
# Set timezone via DevTools
driver.execute_cdp_cmd("Emulation.setTimezoneOverride", {"timezoneId": identity["timezone"]})
# Inject WebGL vendor/renderer spoofing if needed
driver.execute_script("""
Object.defineProperty(navigator, 'platform', {get: () => '%s'});
Object.defineProperty(navigator, 'hardwareConcurrency', {get: () => %d});
Object.defineProperty(navigator, 'maxTouchPoints', {get: () => %d});
Object.defineProperty(navigator, 'languages', {get: () => ['en-US', 'en']});
Object.defineProperty(navigator, 'language', {get: () => 'en-US'});
Object.defineProperty(navigator, 'webdriver', {get: () => undefined});
""" % (
identity['platform'],
identity['hardware_concurrency'],
identity['max_touch_points']
))
behavior = assign_behavior_profile()
webgl_vendor = identity['webgl_vendor']
webgl_renderer = identity['webgl_renderer']
driver.execute_script(f'''
const getParameter = WebGLRenderingContext.prototype.getParameter;
WebGLRenderingContext.prototype.getParameter = function(parameter) {{
if (parameter === 37445) return "{webgl_vendor}";
if (parameter === 37446) return "{webgl_renderer}";
return getParameter(parameter);
}};
''')
logging.info(f"WebGL spoof applied: {webgl_vendor} / {webgl_renderer}")
# Canvas fingerprint spoofing and AudioBuffer
driver.execute_script('''
const origToDataURL = HTMLCanvasElement.prototype.toDataURL;
HTMLCanvasElement.prototype.toDataURL = function() {
return "data:image/png;base64,canvasfakestring==";
};
const origGetChannelData = AudioBuffer.prototype.getChannelData;
AudioBuffer.prototype.getChannelData = function() {
const results = origGetChannelData.apply(this, arguments);
for (let i = 0; i < results.length; i++) {
results[i] = results[i] + Math.random() * 0.0000001;
}
return results;
};
''')
logging.info("Stealth browser launched successfully.")
return driver, behavior
We can't go line by line to see what each code block does, so let's look at it from a high-level perspective. You can modify this code as needed to suit your specific setup.
What you’ll notice right off the bat is that this function takes input from most of the functions we designed above, specifically the proxy and identity objects that define how the browser should behave.
The first thing it does is launch the stealth browser using undetected-chromedriver, with the proxy and identity as the two main arguments. It extracts the proxy address from the whole string, then builds a custom Chrome session.
During this setup, it applies the proxy, sets the screen size based on your identity profile, sets the language headers, turns off automation features, and patches things such as localStorage, sessionStorage, and cookies.
What comes next is a full-on fingerprint override. The function spoofs everything from user agent, platform, WebGL renderer/vendor, to navigator flags like webdriver, plugins, and even time zone. It also injects fake audio and canvas fingerprints to avoid canvas/audio-based tracking.
All of this is what makes the browser “undetectable.” Once spoofing is in place, the function returns the driver and a behavior profile, allowing your scraper to blend in like a real human user.
Step 15: Verify Your Stealth Setup
Let’s make sure everything we’ve built so far is actually working. To do that, we’ll use SannySoft , a website designed to show exactly what your browser reveals to the outside world. Add the following function to your code to verify that your spoofed identity and stealth patches are sticking:
def verify_stealth_setup(driver, identity):
try:
# Go to a tool that reflects fingerprint info
driver.get("https://bot.sannysoft.com")
time.sleep(3)
# Step 1: Basic navigator checks using JS
navigator_checks = driver.execute_script("""
return {
webdriver: navigator.webdriver === undefined,
platform: navigator.platform,
hardwareConcurrency: navigator.hardwareConcurrency,
languages: navigator.languages,
userAgent: navigator.userAgent
};
""")
if not navigator_checks['webdriver']:
logging.warning("webdriver flag detected — browser likely flagged as bot")
return False
if navigator_checks['platform'] != identity['platform']:
logging.warning(f"Platform mismatch: expected {identity['platform']}, got {navigator_checks['platform']}")
return False
if navigator_checks['userAgent'] != identity['user_agent']:
logging.warning(f"User-Agent mismatch: expected {identity['user_agent']}, got {navigator_checks['userAgent']}")
return False
# Step 2: Timezone check via JS
browser_tz = driver.execute_script("return Intl.DateTimeFormat().resolvedOptions().timeZone")
if browser_tz != identity['timezone']:
logging.warning(f"Timezone mismatch: expected {identity['timezone']}, got {browser_tz}")
return False
# Passed all checks
logging.info("Stealth verification passed.")
return True
except Exception as e:
logging.error(f"Error during stealth verification: {e}")
return False
Since we set HEADLESS = False, you’ll be able to see the verification run in real-time. The function first retrieves the spoofed fingerprints and then compares them against the identity you assigned. This step simply confirms that the browser appears exactly how you told it to.
Step 16: Searching Yellow Pages Like a Human
We’re now ready to write a function that can search the Yellow Pages. For this tutorial, remember we’re scraping roofing contractors in Los Angeles. If you visit the Yellow Pages homepage, this is what you’ll see:
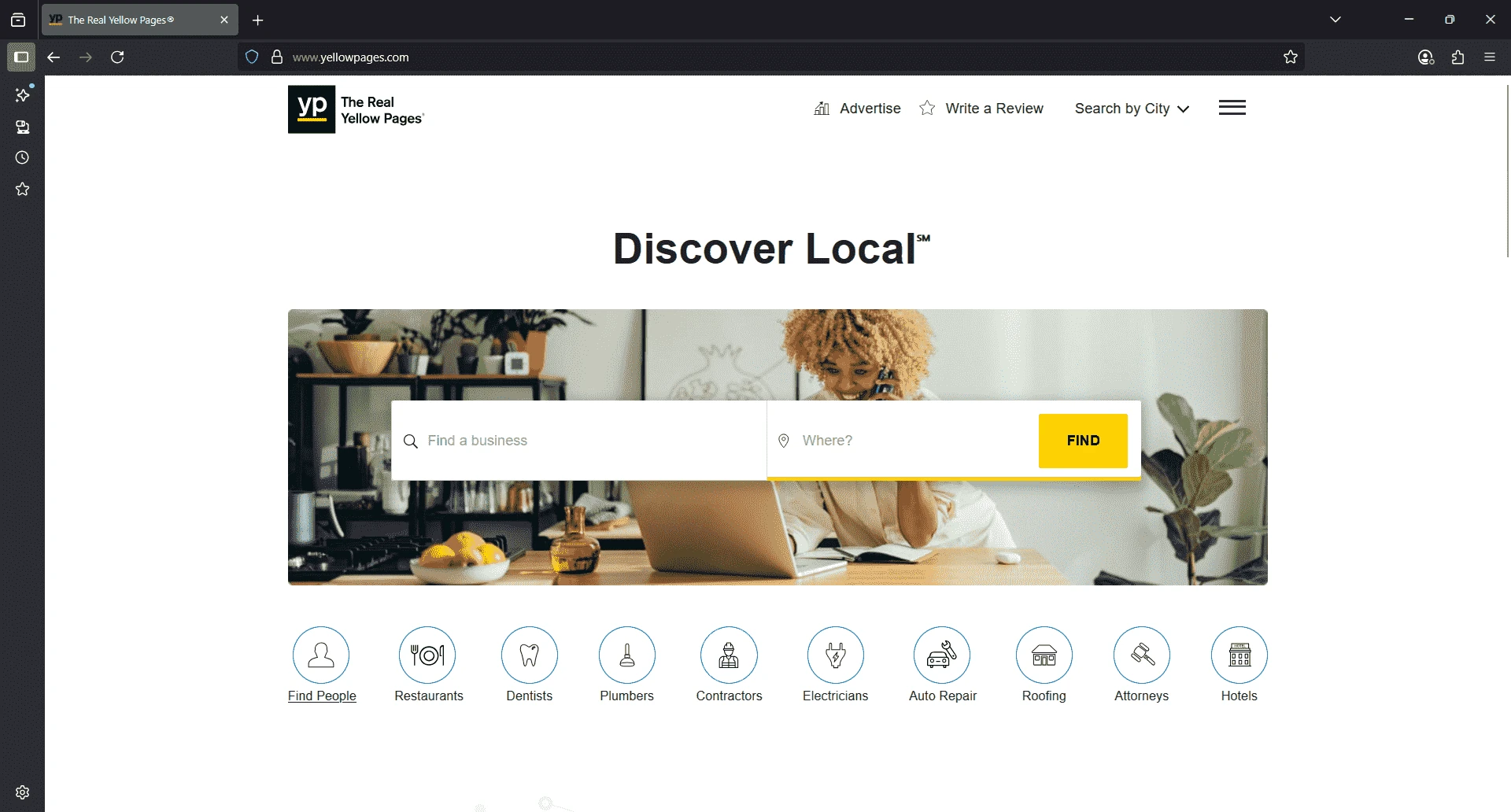
Now, we could go straight to the results page that lists roofing contractors in LA. But that shortcut increases our chances of getting flagged. Bots that skip the natural flow of a site tend to stand out.
Instead, the safest path is to start like a clueless user:
- Land on the homepage
- Manually type in the location
- Type in the business type
- And click 'Find'
That way, we blend in with expected user behavior and drastically reduce our odds of getting caught.
On the homepage above, right-click on the 'Find a business' search box and click 'Inspect'. In the highlighted HTML, you will see something like this:
<input id="query" type="text" value="" placeholder="Find a business" autocomplete="off" data-onempty="recent-searches" name="search_terms">
Take note of the id="query" - that’s what we’ll use in our code. Then do the same for the location box. You'll see something like:
<input id="location" type="text" value="Cleveland, OH" placeholder="Where?" autocomplete="off" data-onempty="menu-location" name="geo_location_terms" data-gtm-form-interact-field-id="0">
Take id="location" as your second target.
Now we can add these elements to our code below:
def search_yellowpages_homepage(driver, behavior, query="roofing contractors", location="Los Angeles, CA"):
try:
logging.info("Navigating to YellowPages homepage...")
driver.get("https://www.yellowpages.com")
search_input = WebDriverWait(driver, 20).until(
EC.presence_of_element_located((By.ID, "query"))
)
location_input = driver.find_element(By.ID, "location")
# Type location first + accept autosuggest
location_input.clear()
for ch in location:
location_input.send_keys(ch)
time.sleep(behavior["base_delay"] + random.uniform(0.05, 0.18))
location_input.send_keys(Keys.TAB)
time.sleep(random.uniform(0.2, 0.5))
# Type query with tiny typo chance
typo_chance = 0.15 if behavior.get("slow_typing") else 0.05
base_delay = behavior["base_delay"]
search_input.clear()
for ch in query:
if random.random() < typo_chance:
wrong = random.choice("abcdefghijklmnopqrstuvwxyz")
search_input.send_keys(wrong)
time.sleep(base_delay + random.uniform(0.08, 0.22))
search_input.send_keys(Keys.BACKSPACE)
time.sleep(base_delay + random.uniform(0.08, 0.22))
search_input.send_keys(ch)
time.sleep(base_delay + random.uniform(0.08, 0.22))
# mild human wiggle
try:
ActionChains(driver).move_by_offset(random.randint(5,30), random.randint(5,30)).pause(random.uniform(0.2,0.6)).perform()
except Exception:
pass
search_input.send_keys(Keys.RETURN)
# Wait for results + URL to settle
WebDriverWait(driver, 30).until(
EC.presence_of_all_elements_located((By.CSS_SELECTOR, "div.srp-listing, .result"))
)
time.sleep(base_delay + random.uniform(1.5, 3.0))
WebDriverWait(driver, 10).until(lambda d: "/search" in d.current_url or "?search_terms=" in d.current_url)
url = driver.current_url
logging.info(f"YellowPages search completed. URL captured: {url}")
return url
except Exception as e:
logging.error(f"Error during YellowPages homepage search: {e}")
return None
Let’s break down exactly what’s happening here:
- def search_yellowpages_homepage(driver, behavior, query="roofing contractors", location="Los Angeles, CA")
This function instructs the bot to visit Yellow Pages, enter a location and business type, and submit the search. It takes the customized stealth browser (driver), a random behavior profile (behavior), and default search terms (query and location).
- driver.get(" https://www.yellowpages.com ")
This line opens the Yellow Pages homepage. It’s inside a try block to prevent the scraper from crashing if anything goes wrong.
- WebDriverWait(driver, 15).until(...)
Waits up to 15 seconds for the search input box to appear. Specifically, it targets the input field with the ID "query".
- location_input = driver.find_element(By.ID, "location")
After the page loads, this grabs the location input field using the ID selector.
- location_input.clear() + typing the location
Clears any pre-filled text, then types the location character by character.
Delays between keystrokes are randomized based on the selected behavior profile to mimic human typing.
- typo_chance = 0.15 if behavior.get("slow_typing") else 0.05
This sets how likely the bot is to make a typo. Slow typists (in the profile) have a 15% typo chance, otherwise, it's 5% - helping the bot appear more human.
- search_input.clear() + typing the business query
Just like the location field, we clear the search box and type the business name letter by letter. We simulate occasional typos and correct them using the backspace key, just like a human would.
- search_input.send_keys(Keys.RETURN)
Once typing is done, this line mimics pressing Enter to submit the search.
- WebDriverWait(...) + time.sleep(...)
After submitting, we wait for the results section to load (using .srp-listing as a signal), then add a random delay to mimic natural idle time before scraping.
- url = driver.current_url
Captures the results page URL. This is essential for the next scraping step.
If an error arises, we catch it and log it using the except block.
Step 17: Define a Function That Scrapes Business Listings
Now that we’ve captured a clean, fingerprint-free URL, let’s use it to extract listings for roofing contractors. Add the following function:
def scrape_yellowpages(driver, behavior, url=None):
results = []
try:
# IMPORTANT: if we're already on the results page, do NOT reload it
if url:
current = driver.current_url
# Only navigate if we're not already there (avoid losing referrer/cookies)
if not current or current != url:
driver.get(url)
WebDriverWait(driver, 30).until(
EC.presence_of_all_elements_located((By.CSS_SELECTOR, "div.srp-listing, .result"))
)
# tiny scroll & idle
driver.execute_script("window.scrollBy(0, arguments[0]);", random.randint(150, 600))
time.sleep(random.uniform(1.2, 2.5))
listings = driver.find_elements(By.CSS_SELECTOR, "div.srp-listing, .result")
for idx, listing in enumerate(listings[:MAX_LISTINGS_PER_PAGE]):
try:
name_el = listing.find_element(By.CSS_SELECTOR, "h2.n a.business-name span, a.business-name span, a.business-name")
name = name_el.text.strip()
# phone can be missing or behind different templates
phone = ""
try:
phone_el = listing.find_element(By.CSS_SELECTOR, "div.phones.phone.primary, .phones")
phone = phone_el.text.strip()
except Exception:
pass
logging.info(f"Found listing: {name} {phone}")
results.append((name, phone))
if idx and idx % 5 == 0:
time.sleep(random.uniform(2.0, 4.5))
except Exception as e:
logging.debug(f"Skipping one listing: {e}")
continue
# light de-robotize movement
if behavior.get("move_mouse_between_actions"):
try:
header = driver.find_element(By.CSS_SELECTOR, "header, .header, body")
ActionChains(driver).move_to_element(header).pause(random.uniform(0.5, 1.1)).perform()
except Exception:
pass
time.sleep(random.uniform(1.8, 3.8))
return results
except Exception as e:
logging.error(f"YellowPages scraping failed: {e}")
return []
Here's what's happening:
- def scrape_yellowpages(driver, behavior, url=None)
We define a function that takes three arguments: the stealth Chrome browser we launched earlier, a behavior profile, and the search results URL we captured earlier.
- results = []
Initializes an empty list where we'll store (name, phone) tuples for each business found.
- if url:
If a URL was passed from the previous function, the bot gets the current page URL the driver is sitting on.
- if not current or current != url:
Avoids reloading the sample page to preserve referrers, cookies, and session tokens.
- Logging and WebDriverWait
Begins a try block to catch errors gracefully. It then logs the start of the scraping process and loads the search results page using the captured URL.
- driver.execute_script(...)
Scrolls the window a little bit downward to mimic a small human scroll.
- time.sleep(random.uniform(2.5, 5.0))
Adds a randomized pause to simulate human “reading” time before interacting with the page.
- listings = driver.find_elements(By.CSS_SELECTOR, "div.srp-listing")
Collects all visible business listing elements into a list for processing.
- For listing in listings + try block
Iterates over each business listing and extracts the company name and phone number using CSS selectors. Cleans the text to remove whitespace, then logs the result and appends it to the results list.
Step 18: Define a Function to Store the Results in a CSV File
Now that we’ve collected the business listings and created an empty CSV file, we use the function below to transfer the data into that file. Each listing is written as a new row, including the name, phone number, and a timestamp.
def log_business_to_csv(name, phone):
with open("yellowpages_data.csv", mode="a", newline="", encoding="utf-8") as f:
writer = csv.writer(f)
writer.writerow([datetime.now().isoformat(), name, phone])
Step 19: Define a Function to Detect Bot Blocks
Before we initialize the CSV, we need to check whether the bot has been soft-blocked. If we skip this step and a block occurs, the script could exit with a blank CSV file.
Use the following function to detect blocks like CAPTCHAs, rate limits, or access denials:
def detect_block(driver):
html = driver.page_source.lower()
if "unusual traffic" in html or "are you a robot" in html or "captcha" in html:
return "captcha"
if "access denied" in html or "403 forbidden" in html:
return "forbidden"
if "automated queries" in html or "too many requests" in html:
return "rate_limit"
if len(html.strip()) < 1000:
return "empty"
return None
initialize_csv()
Step 20: Write the Main Execution Block
Now that all the functions are defined, it’s time to put them to work. This step creates the main execution loop that ties everything together with smart retry logic. Without it, our script would just be a collection of unused functions - this is what actually runs the scraper.
Add the code below to execute your full scraping workflow:
for attempt in range(MAX_RETRIES):
try:
proxy, identity = assign_proxy_and_identity()
driver, behavior = launch_stealth_browser(proxy, identity)
logging.info(f" Behavior profile: {behavior['name']}")
# Optional health check — keep or remove
if not verify_stealth_setup(driver, identity):
raise Exception("Stealth verification failed.")
block = detect_block(driver)
if block:
raise Exception(f"Pre-check block: {block}")
url = search_yellowpages_homepage(driver, behavior,
query="roofing contractors",
location="Los Angeles, CA")
if not url:
raise Exception("Search submission failed or listings did not load.")
results = scrape_yellowpages(driver, behavior, url)
block = detect_block(driver)
if block:
raise Exception(f"Blocked while scraping YP: {block}")
if results:
for name, phone in results:
print(f" {name} — {phone}")
log_business_to_csv(name, phone)
driver.quit()
sys.exit(0)
else:
logging.warning("No YellowPages listings found on scanned pages.")
driver.quit()
# fall through to retry with new proxy
except Exception as e:
logging.error(f"Attempt {attempt + 1} failed: {e}")
backoff = BLOCK_BACKOFF_STEPS[min(attempt, len(BLOCK_BACKOFF_STEPS) - 1)]
logging.info(f"Waiting {backoff}s before retry with new proxy/identity.")
try:
driver.quit()
except:
pass
time.sleep(backoff)
else:
logging.critical(" All retry attempts failed. Exiting.")
sys.exit(1)
This block begins by starting a retry loop: for attempt in range(MAX_RETRIES). It runs the scraping logic multiple times in case of failure, based on the MAX_RETRIES global setting.
Inside the try block, it first calls the assign_proxy_and_identity() function to pick a fresh rotating proxy and a spoofed identity profile. It then launches a stealth browser session using launch_stealth_browser(), which launches an undetected-chromedriver instance configured with the assigned identity. Immediately after, it logs the behavior profile being used.
Next, it verifies whether the stealth setup was successful by calling verify_stealth_setup(), then checks the page source for any soft blocks using detect_block(). If no blocks are found, it calls the search_yellowpages_homepage() function to simulate a human search and capture the resulting URL.
That URL is then passed into the scrape_yellowpages() function, which handles the actual data extraction. After scraping, it performs one more block check. If the results are clean and contain business listings, it logs them to a CSV file using log_business_to_csv(). If no data is found or any part of the process fails, it exits or retries using the next proxy.
Step 21: Run Your Yellow Pages Scraper
Here is the full Yellow Pages scraper code:
#Browser Control & Stealth Automation
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.chrome.options import Options
import undetected_chromedriver as uc
#Proxy, Fingerprint & Spoofing Logic
import time
import random
import os
import sys
import uuid
import logging
import re
# Data logging and Outputt
import csv
from datetime import datetime
# Configure logging
logging.basicConfig(level=logging.INFO, format='[%(asctime)s] %(message)s')
# Global Settings
HEADLESS = False # Set to True later if you spoof it correctly
MAX_RETRIES = 5
BLOCK_BACKOFF_STEPS = [5, 10, 20, 30] # seconds
MAX_LISTINGS_PER_PAGE = 30
#Proxy pool
PROXIES = [
"http://geo.iproyal.com:12321/country-us_city-losangeles_session-TCDPEKCM_lifetime-30m",
"http://geo.iproyal.com:12321/country-us_city-losangeles_session-ZbgnB6u4_lifetime-30m",
"http://geo.iproyal.com:12321/country-us_city-losangeles_session-wrAACjQS_lifetime-30m",
"http://geo.iproyal.com:12321/country-us_city-losangeles_session-EE8Rhsih_lifetime-30m",
"http://geo.iproyal.com:12321/country-us_city-losangeles_session-fGo0pPHi_lifetime-30m",
"http://geo.iproyal.com:12321/country-us_city-losangeles_session-7JrqLZN2_lifetime-30m",
"http://geo.iproyal.com:12321/country-us_city-losangeles_session-mCRJTcks_lifetime-30m",
"http://geo.iproyal.com:12321/country-us_city-losangeles_session-51dDpfgf_lifetime-30m",
"http://geo.iproyal.com:12321/country-us_city-losangeles_session-Ve2WXTEV_lifetime-30m",
"http://geo.iproyal.com:12321/country-us_city-losangeles_session-jurD1lGK_lifetime-30m"
]
TIMEZONE_MAP = {
"city-losangeles": "America/Los_Angeles"
}
def extract_timezone(proxy_string):
match = re.search(r"(city|state)-([a-z]+)", proxy_string)
if not match:
raise ValueError(f"Could not extract location from: {proxy_string}")
loc_key = f"{match.group(1)}-{match.group(2)}"
timezone = TIMEZONE_MAP.get(loc_key)
if not timezone:
raise ValueError(f"No timezone mapped for: {loc_key}")
return timezone
IDENTITY_POOL = [
{
"identity_id": "la_win_chrome_11",
"device_group": "desktop-windows",
"timezone": "America/Los_Angeles",
"user_agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.6478.62 Safari/537.36",
"viewport": (1920, 1080),
"platform": "Win32",
"hardware_concurrency": 12,
"max_touch_points": 0,
"webgl_vendor": "NVIDIA Corporation",
"webgl_renderer": "NVIDIA GeForce RTX 4060"
},
{
"identity_id": "la_mac_safari_12",
"device_group": "desktop-mac",
"timezone": "America/Los_Angeles",
"user_agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 14_5) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/17.5 Safari/605.1.15",
"viewport": (1728, 1117),
"platform": "MacIntel",
"hardware_concurrency": 10,
"max_touch_points": 0,
"webgl_vendor": "Apple Inc.",
"webgl_renderer": "Apple M3 Pro GPU"
},
{
"identity_id": "la_linux_firefox_13",
"device_group": "desktop-linux",
"timezone": "America/Los_Angeles",
"user_agent": "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:127.0) Gecko/20100101 Firefox/127.0",
"viewport": (1600, 900),
"platform": "Linux x86_64",
"hardware_concurrency": 6,
"max_touch_points": 0,
"webgl_vendor": "X.Org",
"webgl_renderer": "Mesa Intel(R) UHD Graphics 730"
},
{
"identity_id": "la_win_edge_14",
"device_group": "desktop-windows",
"timezone": "America/Los_Angeles",
"user_agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.6478.62 Safari/537.36 Edg/126.0.2592.87",
"viewport": (1366, 768),
"platform": "Win32",
"hardware_concurrency": 8,
"max_touch_points": 0,
"webgl_vendor": "Intel Inc.",
"webgl_renderer": "Intel Iris Xe Graphics"
},
{
"identity_id": "la_mac_chrome_15",
"device_group": "desktop-mac",
"timezone": "America/Los_Angeles",
"user_agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/125.0.6422.141 Safari/537.36",
"viewport": (1440, 900),
"platform": "MacIntel",
"hardware_concurrency": 8,
"max_touch_points": 0,
"webgl_vendor": "Apple Inc.",
"webgl_renderer": "Apple M2 GPU"
},
{
"identity_id": "la_linux_edge_16",
"device_group": "desktop-linux",
"timezone": "America/Los_Angeles",
"user_agent": "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/126.0.6478.62 Safari/537.36 Edg/126.0.2592.87",
"viewport": (1536, 864),
"platform": "Linux x86_64",
"hardware_concurrency": 4,
"max_touch_points": 0,
"webgl_vendor": "AMD",
"webgl_renderer": "Radeon RX 6700 XT"
}
]
# Proxy assignment and identity logic
def assign_proxy_and_identity():
proxy = random.choice(PROXIES)
logging.info(f"Selected proxy: {proxy}")
try:
timezone = extract_timezone(proxy)
except ValueError as e:
logging.error(f"Failed to extract timezone: {e}")
raise
# Filter identities by matching timezone
matching_identities = [idn for idn in IDENTITY_POOL if idn["timezone"] == timezone]
if not matching_identities:
logging.error(f"No identities found for timezone: {timezone}")
raise Exception(f"No identities match timezone: {timezone}")
identity = random.choice(matching_identities)
logging.info(f"Assigned identity with user agent: {identity['user_agent']}")
return proxy, identity
# Each profile defines timing, interaction, and navigation tendencies
BEHAVIOR_PROFILES = [
{
"name": "Fast Clicker",
"base_delay": 0.5,
"scroll_pattern": "none",
"hover_before_click": False,
"re_click_probability": 0.05,
"slow_typing": False,
"move_mouse_between_actions": True,
},
{
"name": "Deliberate Reader",
"base_delay": 2.5,
"scroll_pattern": "linear",
"hover_before_click": True,
"re_click_probability": 0.02,
"slow_typing": True,
"move_mouse_between_actions": True,
},
{
"name": "Back-and-Forth Browser",
"base_delay": 1.2,
"scroll_pattern": "jittery",
"hover_before_click": True,
"re_click_probability": 0.1,
"slow_typing": True,
"move_mouse_between_actions": True,
},
{
"name": "Precise Shopper",
"base_delay": 1.0,
"scroll_pattern": "none",
"hover_before_click": False,
"re_click_probability": 0.01,
"slow_typing": True,
"move_mouse_between_actions": True,
},
{
"name": "Researcher",
"base_delay": 2.0,
"scroll_pattern": "linear",
"hover_before_click": True,
"re_click_probability": 0.03,
"slow_typing": True,
"move_mouse_between_actions": True,
},
{
"name": "Curious Clicker",
"base_delay": 1.7,
"scroll_pattern": "jittery",
"hover_before_click": True,
"re_click_probability": 0.2,
"slow_typing": False,
"move_mouse_between_actions": True,
},
{
"name": "Hesitant User",
"base_delay": 3.0,
"scroll_pattern": "none",
"hover_before_click": True,
"re_click_probability": 0.0,
"slow_typing": True,
"move_mouse_between_actions": True,
},
]
# Function to randomly select a behavior profile for a session
def assign_behavior_profile():
return random.choice(BEHAVIOR_PROFILES)
def initialize_csv():
filename = "yellowpages_data.csv"
if not os.path.exists(filename):
with open(filename, mode="w", newline="", encoding="utf-8") as f:
writer = csv.writer(f)
writer.writerow(["timestamp", "name", "phone"])
# Here's the complete stealth launch function based on the provided context.
def launch_stealth_browser(proxy: str, identity: dict):
"""
Launch a stealthy undetected Chrome browser instance with proxy and identity settings applied.
"""
# Extract proxy credentials and IP
proxy_address = proxy.split("/")[2] # Extracts 'geo.iproyal.com:12321'
proxy_address = proxy.split("/")[2] # Gets host:port from your whitelisted proxy string
# Stealthy browser options
options = uc.ChromeOptions()
options.add_argument(f'--proxy-server=http://{proxy_address}')
options.add_argument(f"--window-size={identity['viewport'][0]},{identity['viewport'][1]}")
options.add_argument(f"--lang=en-US,en;q=0.9")
options.add_argument("--disable-blink-features=AutomationControlled")
options.add_experimental_option("prefs", {
"credentials_enable_service": False,
"profile.password_manager_enabled": False
})
if HEADLESS:
options.add_argument("--headless=new")
# Start undetected Chrome driver
driver = uc.Chrome(options=options)
driver.execute_script("window.localStorage.setItem('bb_test_key', 'value');")
driver.execute_script("window.sessionStorage.setItem('bb_test_key', 'value');")
driver.execute_script("document.cookie = 'bb_user_sim=1234567; path=/';")
driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", {
"source": f"""
Object.defineProperty(navigator, 'webdriver', {{get: () => undefined}});
Object.defineProperty(navigator, 'userAgent', {{get: () => "{identity['user_agent']}" }});
Object.defineProperty(navigator, 'platform', {{get: () => "{identity['platform']}" }});
Object.defineProperty(navigator, 'hardwareConcurrency', {{get: () => {identity['hardware_concurrency']} }});
Object.defineProperty(navigator, 'maxTouchPoints', {{get: () => {identity['max_touch_points']} }});
Object.defineProperty(navigator, 'languages', {{get: () => ['en-US', 'en'] }});
Object.defineProperty(navigator, 'language', {{get: () => 'en-US' }});
"""
})
# Enable DevTools protocol
driver.execute_cdp_cmd("Page.enable", {})
# Add fake chrome.runtime support
driver.execute_cdp_cmd("Runtime.evaluate", {
"expression": "Object.defineProperty(navigator, 'chrome', { get: () => ({ runtime: {} }) });"
})
driver.execute_script("""
Object.defineProperty(navigator, 'plugins', {
get: () => [1, 2, 3, 4, 5]
});
Object.defineProperty(navigator, 'mimeTypes', {
get: () => [1, 2, 3]
});
navigator.mediaDevices = {
enumerateDevices: () => Promise.resolve([
{ kind: 'audioinput', label: 'Built-in Microphone' },
{ kind: 'videoinput', label: 'Integrated Camera' }
])
};
Object.defineProperty(screen, 'colorDepth', {
get: () => 24
});
""")
# Proxy authentication via DevTools Protocol
driver.execute_cdp_cmd('Network.enable', {})
# Set timezone via DevTools
driver.execute_cdp_cmd("Emulation.setTimezoneOverride", {"timezoneId": identity["timezone"]})
# Inject WebGL vendor/renderer spoofing if neede
driver.execute_script("""
Object.defineProperty(navigator, 'platform', {get: () => '%s'});
Object.defineProperty(navigator, 'hardwareConcurrency', {get: () => %d});
Object.defineProperty(navigator, 'maxTouchPoints', {get: () => %d});
Object.defineProperty(navigator, 'languages', {get: () => ['en-US', 'en']});
Object.defineProperty(navigator, 'language', {get: () => 'en-US'});
Object.defineProperty(navigator, 'webdriver', {get: () => undefined});
""" % (
identity['platform'],
identity['hardware_concurrency'],
identity['max_touch_points']
))
behavior = assign_behavior_profile()
webgl_vendor = identity['webgl_vendor']
webgl_renderer = identity['webgl_renderer']
driver.execute_script(f'''
const getParameter = WebGLRenderingContext.prototype.getParameter;
WebGLRenderingContext.prototype.getParameter = function(parameter) {{
if (parameter === 37445) return "{webgl_vendor}";
if (parameter === 37446) return "{webgl_renderer}";
return getParameter(parameter);
}};
''')
logging.info(f"WebGL spoof applied: {webgl_vendor} / {webgl_renderer}")
# Canvas fingerprint spoofing and AudioBuffer
driver.execute_script('''
const origToDataURL = HTMLCanvasElement.prototype.toDataURL;
HTMLCanvasElement.prototype.toDataURL = function() {
return "data:image/png;base64,canvasfakestring==";
};
const origGetChannelData = AudioBuffer.prototype.getChannelData;
AudioBuffer.prototype.getChannelData = function() {
const results = origGetChannelData.apply(this, arguments);
for (let i = 0; i < results.length; i++) {
results[i] = results[i] + Math.random() * 0.0000001;
}
return results;
};
''')
logging.info("Stealth browser launched successfully.")
return driver, behavior
def verify_stealth_setup(driver, identity):
try:
# Go to a tool that reflects fingerprint info
driver.get("https://bot.sannysoft.com")
time.sleep(3)
# Step 1: Basic navigator checks using JS
navigator_checks = driver.execute_script("""
return {
webdriver: navigator.webdriver === undefined,
platform: navigator.platform,
hardwareConcurrency: navigator.hardwareConcurrency,
languages: navigator.languages,
userAgent: navigator.userAgent
};
""")
if not navigator_checks['webdriver']:
logging.warning("webdriver flag detected — browser likely flagged as bot")
return False
if navigator_checks['platform'] != identity['platform']:
logging.warning(f"Platform mismatch: expected {identity['platform']}, got {navigator_checks['platform']}")
return False
if navigator_checks['userAgent'] != identity['user_agent']:
logging.warning(f"User-Agent mismatch: expected {identity['user_agent']}, got {navigator_checks['userAgent']}")
return False
# Step 2: Timezone check via JS
browser_tz = driver.execute_script("return Intl.DateTimeFormat().resolvedOptions().timeZone")
if browser_tz != identity['timezone']:
logging.warning(f"Timezone mismatch: expected {identity['timezone']}, got {browser_tz}")
return False
# Passed all checks
logging.info("Stealth verification passed.")
return True
except Exception as e:
logging.error(f"Error during stealth verification: {e}")
return False
def search_yellowpages_homepage(driver, behavior, query="roofing contractors", location="Los Angeles, CA"):
try:
logging.info("Navigating to YellowPages homepage...")
driver.get("https://www.yellowpages.com")
search_input = WebDriverWait(driver, 20).until(
EC.presence_of_element_located((By.ID, "query"))
)
location_input = driver.find_element(By.ID, "location")
# Type location first + accept autosuggest
location_input.clear()
for ch in location:
location_input.send_keys(ch)
time.sleep(behavior["base_delay"] + random.uniform(0.05, 0.18))
location_input.send_keys(Keys.TAB)
time.sleep(random.uniform(0.2, 0.5))
# Type query with tiny typo chance
typo_chance = 0.15 if behavior.get("slow_typing") else 0.05
base_delay = behavior["base_delay"]
search_input.clear()
for ch in query:
if random.random() < typo_chance:
wrong = random.choice("abcdefghijklmnopqrstuvwxyz")
search_input.send_keys(wrong)
time.sleep(base_delay + random.uniform(0.08, 0.22))
search_input.send_keys(Keys.BACKSPACE)
time.sleep(base_delay + random.uniform(0.08, 0.22))
search_input.send_keys(ch)
time.sleep(base_delay + random.uniform(0.08, 0.22))
# mild human wiggle
try:
ActionChains(driver).move_by_offset(random.randint(5,30), random.randint(5,30)).pause(random.uniform(0.2,0.6)).perform()
except Exception:
pass
search_input.send_keys(Keys.RETURN)
# Wait for results + URL to settle
WebDriverWait(driver, 30).until(
EC.presence_of_all_elements_located((By.CSS_SELECTOR, "div.srp-listing, .result"))
)
time.sleep(base_delay + random.uniform(1.5, 3.0))
WebDriverWait(driver, 10).until(lambda d: "/search" in d.current_url or "?search_terms=" in d.current_url)
url = driver.current_url
logging.info(f"YellowPages search completed. URL captured: {url}")
return url
except Exception as e:
logging.error(f"Error during YellowPages homepage search: {e}")
return None
def scrape_yellowpages(driver, behavior, url=None):
results = []
try:
# IMPORTANT: if we're already on the results page, do NOT reload it
if url:
current = driver.current_url
# Only navigate if we're not already there (avoid losing referrer/cookies)
if not current or current != url:
driver.get(url)
WebDriverWait(driver, 30).until(
EC.presence_of_all_elements_located((By.CSS_SELECTOR, "div.srp-listing, .result"))
)
# tiny scroll & idle
driver.execute_script("window.scrollBy(0, arguments[0]);", random.randint(150, 600))
time.sleep(random.uniform(1.2, 2.5))
listings = driver.find_elements(By.CSS_SELECTOR, "div.srp-listing, .result")
for idx, listing in enumerate(listings[:MAX_LISTINGS_PER_PAGE]):
try:
name_el = listing.find_element(By.CSS_SELECTOR, "h2.n a.business-name span, a.business-name span, a.business-name")
name = name_el.text.strip()
# phone can be missing or behind different templates
phone = ""
try:
phone_el = listing.find_element(By.CSS_SELECTOR, "div.phones.phone.primary, .phones")
phone = phone_el.text.strip()
except Exception:
pass
logging.info(f"Found listing: {name} {phone}")
results.append((name, phone))
if idx and idx % 5 == 0:
time.sleep(random.uniform(2.0, 4.5))
except Exception as e:
logging.debug(f"Skipping one listing: {e}")
continue
# light de-robotize movement
if behavior.get("move_mouse_between_actions"):
try:
header = driver.find_element(By.CSS_SELECTOR, "header, .header, body")
ActionChains(driver).move_to_element(header).pause(random.uniform(0.5, 1.1)).perform()
except Exception:
pass
time.sleep(random.uniform(1.8, 3.8))
return results
except Exception as e:
logging.error(f"YellowPages scraping failed: {e}")
return []
def log_business_to_csv(name, phone):
with open("yellowpages_data.csv", mode="a", newline="", encoding="utf-8") as f:
writer = csv.writer(f)
writer.writerow([datetime.now().isoformat(), name, phone])
def detect_block(driver):
html = driver.page_source.lower()
if "unusual traffic" in html or "are you a robot" in html or "captcha" in html:
return "captcha"
if "access denied" in html or "403 forbidden" in html:
return "forbidden"
if "automated queries" in html or "too many requests" in html:
return "rate_limit"
if len(html.strip()) < 1000:
return "empty"
return None
initialize_csv()
for attempt in range(MAX_RETRIES):
try:
proxy, identity = assign_proxy_and_identity()
driver, behavior = launch_stealth_browser(proxy, identity)
logging.info(f"Behavior profile: {behavior['name']}")
# Optional health check — keep or remove
if not verify_stealth_setup(driver, identity):
raise Exception("Stealth verification failed.")
block = detect_block(driver)
if block:
raise Exception(f"Pre-check block: {block}")
url = search_yellowpages_homepage(driver, behavior,
query="roofing contractors",
location="Los Angeles, CA")
if not url:
raise Exception("Search submission failed or listings did not load.")
results = scrape_yellowpages(driver, behavior, url)
block = detect_block(driver)
if block:
raise Exception(f"Blocked while scraping YP: {block}")
if results:
for name, phone in results:
print(f"{name} — {phone}")
log_business_to_csv(name, phone)
driver.quit()
sys.exit(0)
else:
logging.warning("No YellowPages listings found on scanned pages.")
driver.quit()
# fall through to retry with new proxy
except Exception as e:
logging.error(f"Attempt {attempt + 1} failed: {e}")
backoff = BLOCK_BACKOFF_STEPS[min(attempt, len(BLOCK_BACKOFF_STEPS) - 1)]
logging.info(f"Waiting {backoff}s before retry with new proxy/identity.")
try:
driver.quit()
except:
pass
time.sleep(backoff)
else:
logging.critical("All retry attempts failed. Exiting.")
sys.exit(1)
Save the code, then return to your Command Prompt (assuming you're still inside the yellowpages-scraper folder) and run:
Python YellowPagesExtractor.py
It’s best to keep the command prompt and browser windows separate so you can monitor the scraper’s progress in real-time. If you prefer to run it silently, just set HEADLESS to True.
Once you press Enter, a new Chrome window will open. The bot will navigate to SannySoft to run the fingerprint test we built into the code. Here’s what that looks like in action:
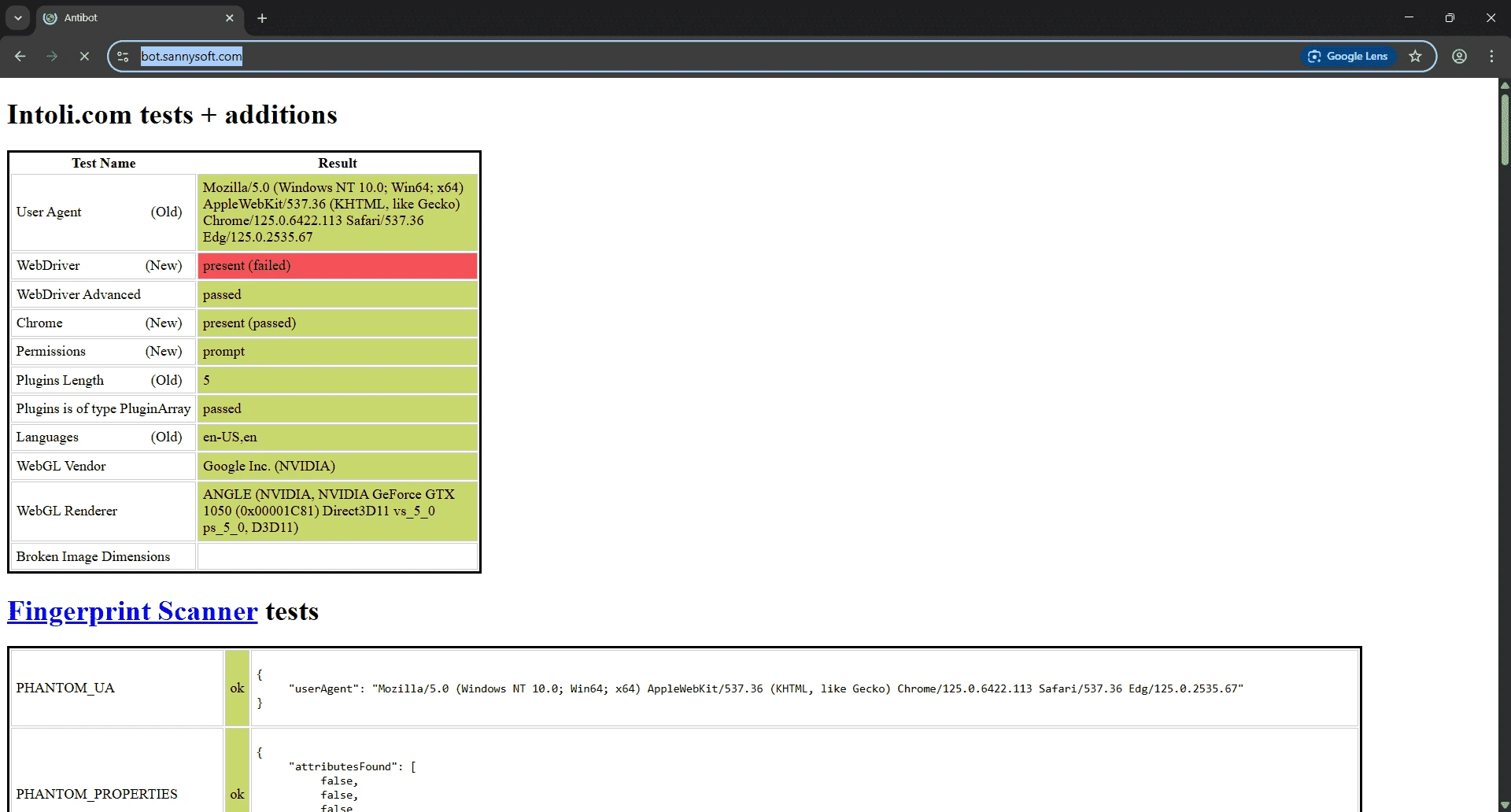
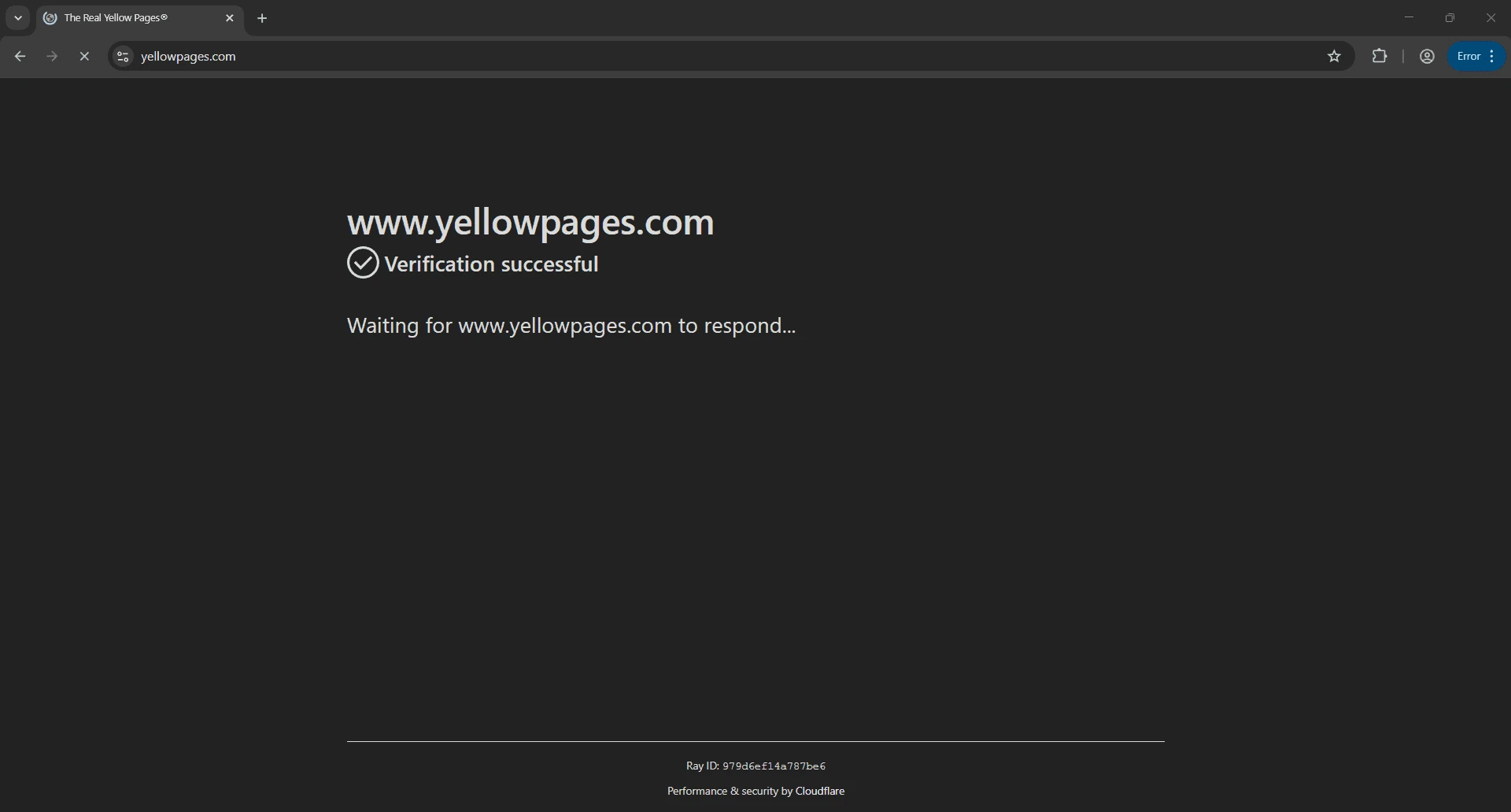
After passing all checks, the bot navigates to Yellow Pages. Give Cloudflare a moment to complete its verification process, as shown below:
Once that’s done, the bot lands on the homepage and begins typing the target location:
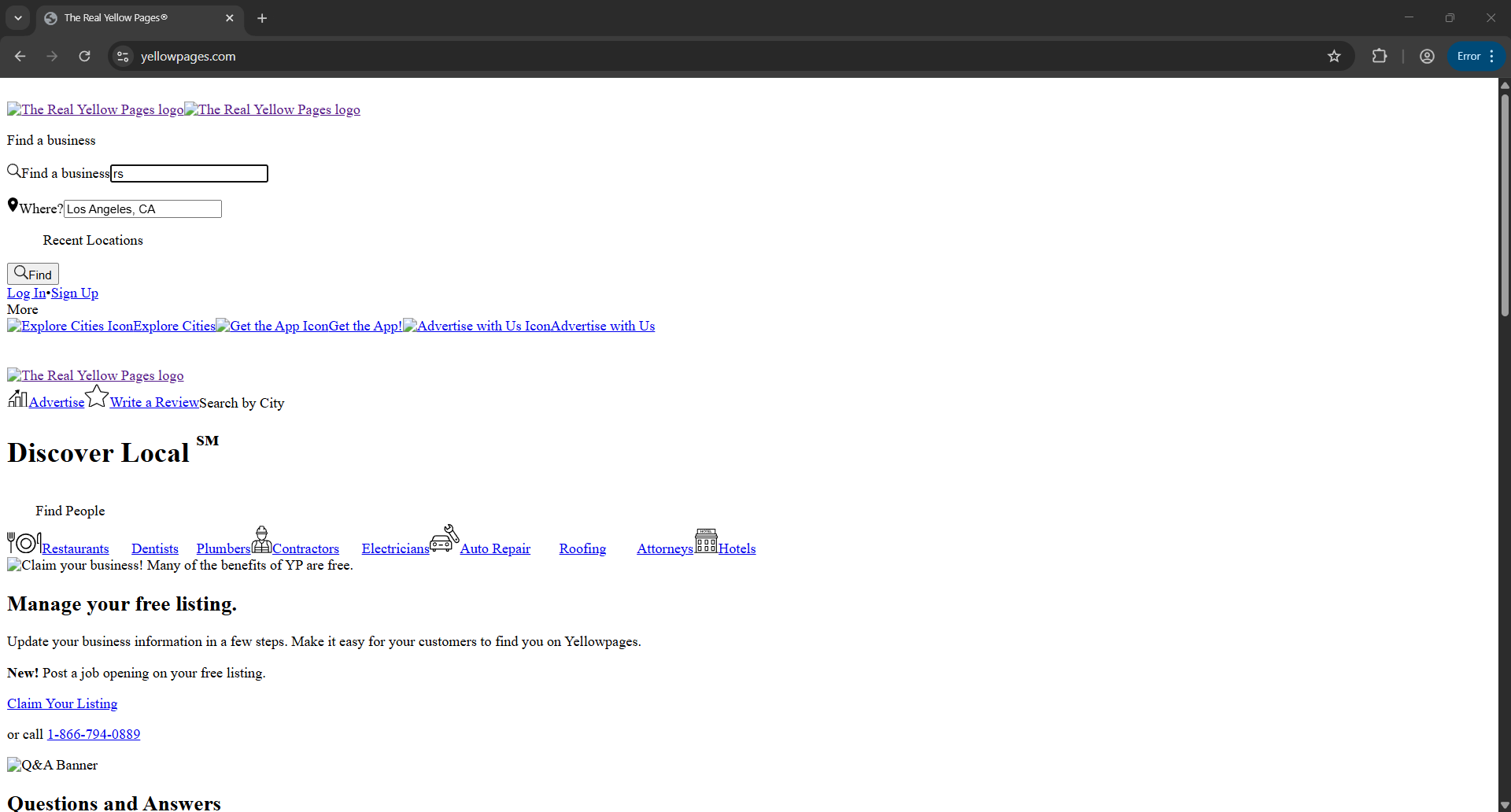
Next, it types the business keyword, “roofing contractors”:
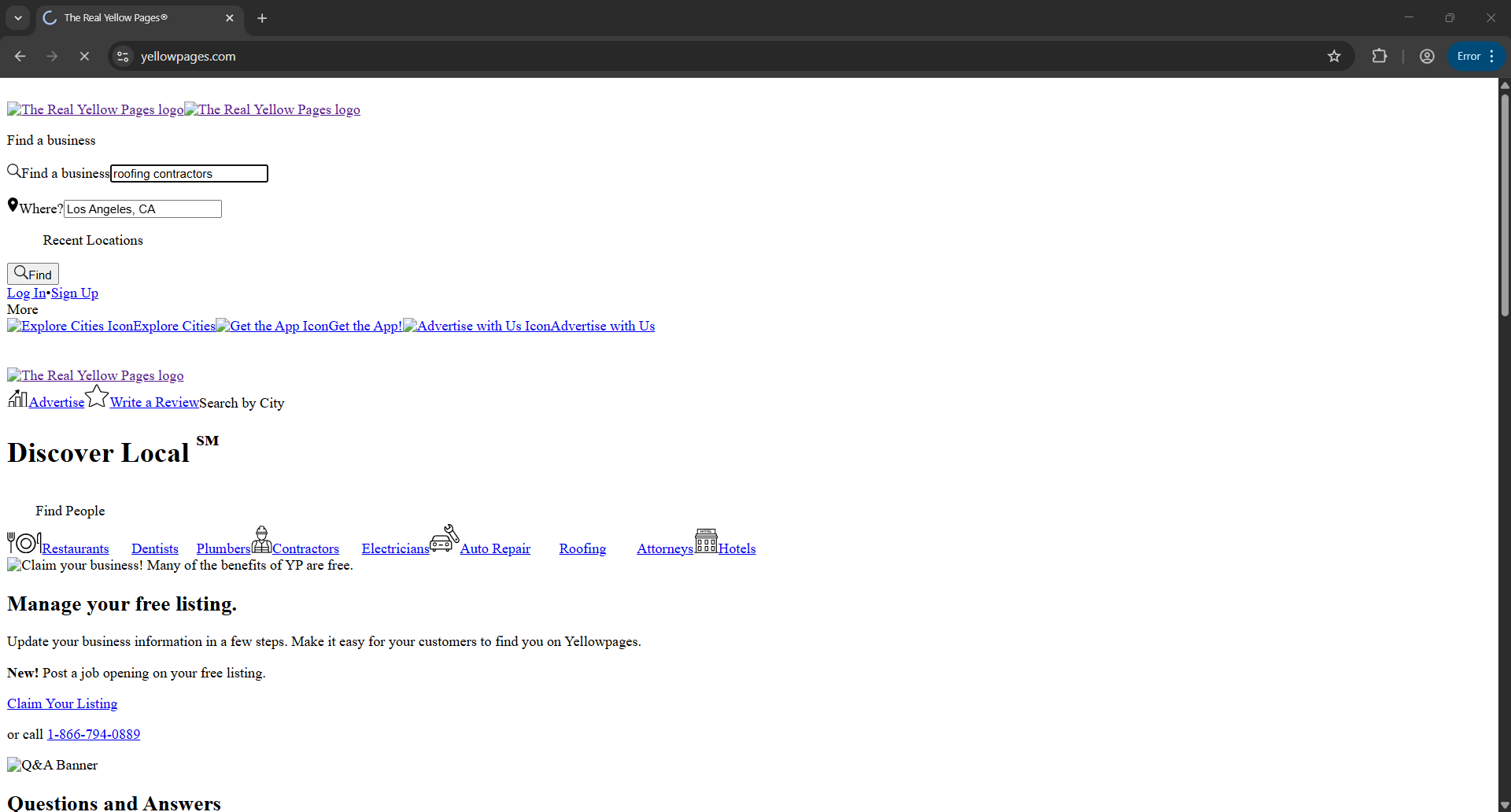
It then hits Enter and waits for the page to load. This is the page where the extraction happens:
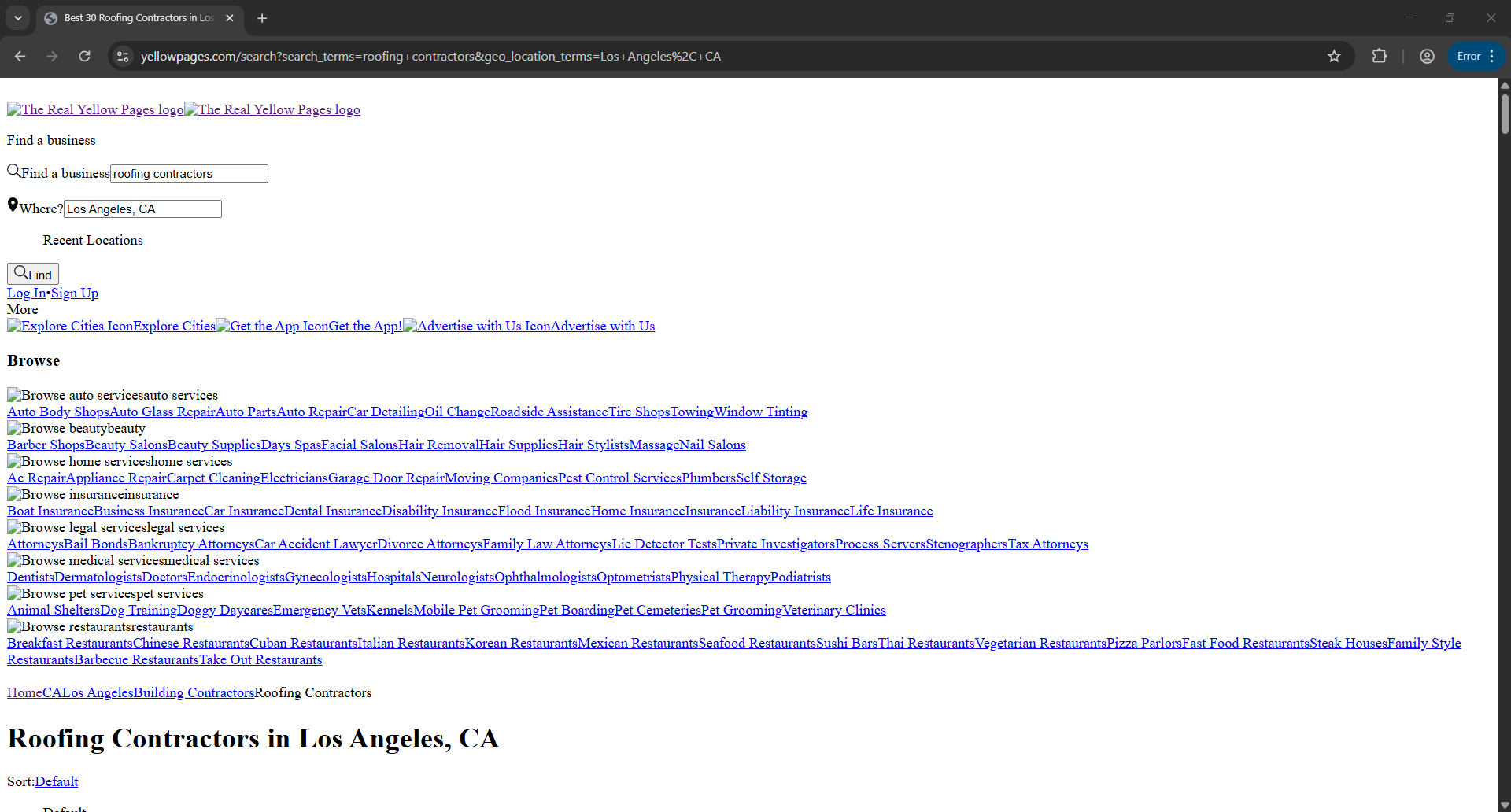
Once that's done, it will exit. Now for the moment of truth: Did our bot actually export the roofing contractor listings to a CSV file in our folder? Let's see. Navigate to our working folder and open the CSV file. You'll now see the extracted data below:
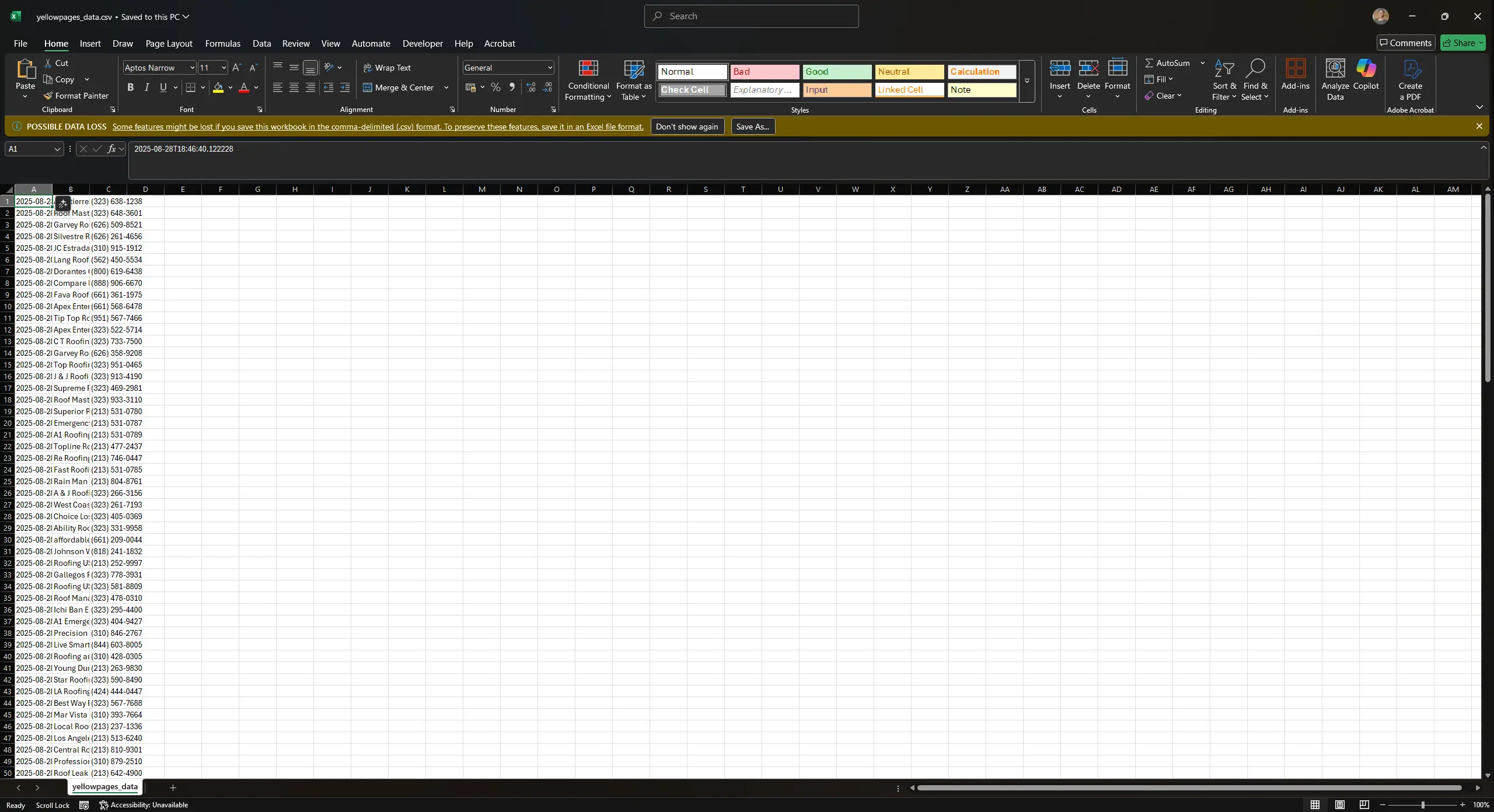
Cleaning up Yellow Pages Business Data
While the phone numbers we scraped this time were mostly clean, that won’t always be the case. Yellow Pages listings often come with phone numbers in inconsistent formats, such as:
(310) 555-1234
310.555.1234
+1-310-555-1234
3105551234
1 (310) 555 1234
What you really want is a clean, standardized format:
+13105551234
Here’s a quick Python script that cleans them up:
import pandas as pd
import re
def normalize_us_phone(phone):
digits = re.sub(r"\D", "", phone)
if digits.startswith("1") and len(digits) == 11:
digits = digits[1:]
return f"+1{digits}" if len(digits) == 10 else None
df = pd.read_csv("yellowpages_data.csv")
df["CleanPhone"] = df["Phone"].apply(normalize_us_phone)
df = df[df["CleanPhone"].notnull()]
df.to_csv("yellowpages_cleaned.csv", index=False)
This script strips out symbols, standardizes all numbers to the +1XXXXXXXXXX format, and drops anything invalid.
Using Scraped Data for Lead Generation
Once you’ve scraped and cleaned your data, the next step is enrichment. Start by appending missing email addresses using scraping tools or third-party platforms. You can also expand your script to capture business websites or social media profiles where available.
With a fully enriched dataset, import everything into your CRM. Segment by location, industry, or business size, and build cold outreach campaigns that feel tailored. Personalized messaging drives better response rates, and when done right, this workflow turns scraped listings into a high-conversion lead generation pipeline.
Conclusion You now have a working Yellow Pages scraper. Just remember: every time you run your scraper, it’s best to use a fresh batch of user agents, identity profiles, and proxies. The newer your fingerprint, the lower your chances of getting flagged. That first run usually gives you the best yield. Better yet, scale it. Use a pool of 100 proxies and 100 identities to minimize detection and maintain uninterrupted data flow.


