'/%3e%3cellipse%20opacity='0.34'%20cx='327.5'%20cy='339'%20rx='264.5'%20ry='264'%20fill='url(%23paint1_linear_12724_35442)'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_12724_35442'%20x1='327'%20y1='-2.524e-06'%20x2='327'%20y2='389.286'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%2327D9E5'/%3e%3cstop%20offset='0.927406'%20stop-color='%23004047'%20stop-opacity='0'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_12724_35442'%20x1='328.02'%20y1='74.7771'%20x2='328.02'%20y2='395.312'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%2327D9E5'/%3e%3cstop%20offset='0.927406'%20stop-color='%23004047'%20stop-opacity='0'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)
Why Relying on a Single Proxy Provider Is a Business Risk You Can’t Afford
NewsRelying on one proxy provider exposes you to outages, policy shifts, and capacity limits. See how a multi-vendor setup reduces those risks.


Karolis Toleikis
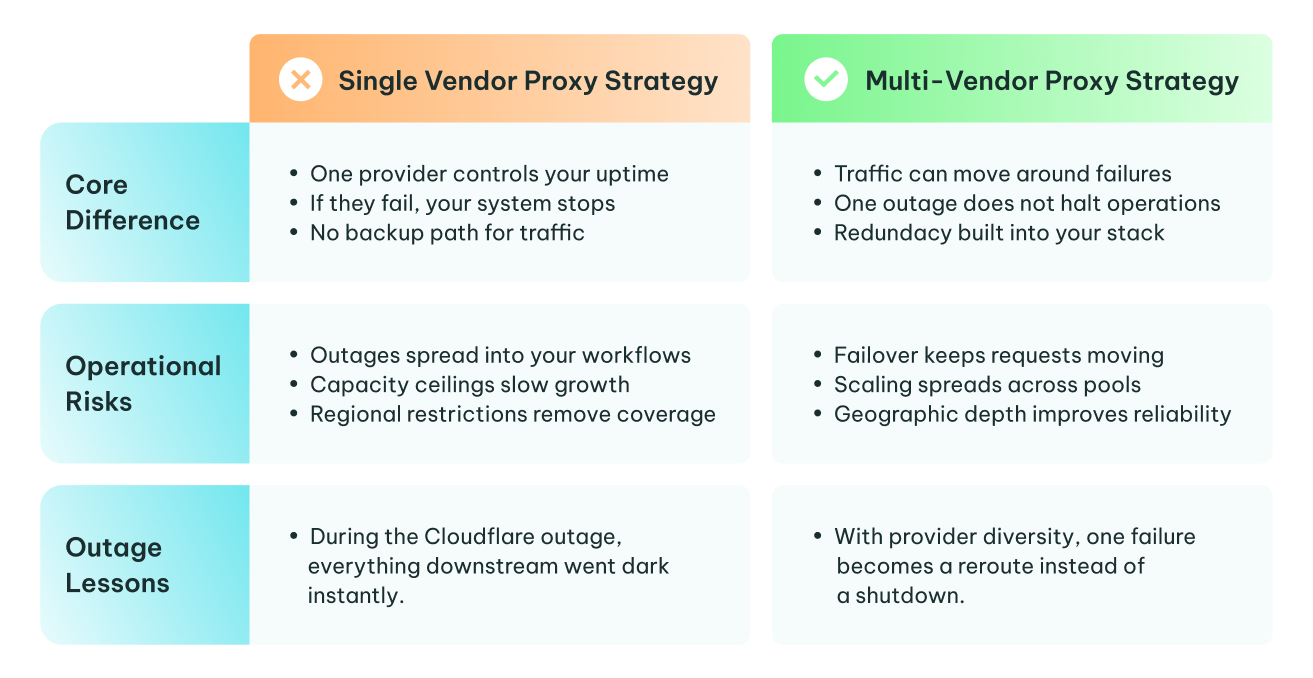
If proxies make a critical component of your operations, continuity is what keeps your data moving when you need it. Many companies stick with one vendor because it feels clean and efficient, and for a while, it usually is.
The problem is that single-vendor dependency turns your proxy layer into a single point of failure. When that provider experiences downtime, throttles capacity, changes direction, or encounters a policy wall, your workflows do not slow down gracefully. They stop.
Real-World Example: Cloudflare Outage Case Study
A recent outage showed how fast a provider-side fault can spread through dependent systems. The Cloudflare incident on November 18, 2025 illustrated that impact clearly.
Cloudflare offers reverse proxy services along with security and traffic optimization tools used across the web. The company has grown large enough to sit in front of almost 20% of websites, which makes the impact of any failure immediate.
When a provider like that experiences disruption, every downstream operation inherits the downtime.
In this case, the failure began inside Cloudflare’s Bot Management stack. Bot Management uses ML-based features to score requests. Those features are bundled into a feature file built from ClickHouse data, then pushed out to Cloudflare’s edge network, so updates apply globally.
Here is what happened:
- Cloudflare pushed an internal database permission update during normal maintenance
- That update caused a ClickHouse query tied to Bot Management to pull duplicate entries
- The duplicate data expanded the feature file well beyond its intended size
- The deployment pipeline distributed that file automatically to edge nodes worldwide
- The edge proxy software could not ingest a file beyond its hard limit, so traffic-handling processes crashed
- Those crashes spilled into widespread HTTP 5xx errors and network-level latency
The main disruption window lasted about three hours, starting around 11:20 UTC (6:20 a.m. ET) and stabilizing close to 14:20 UTC (9:20 a.m. ET).
Cloudflare’s post-mortem made it clear that malicious traffic played no role. A routine internal change created an oversized file, automation pushed it across the network, and the system failed once edge processes could not load it.
From the outside, the impact showed up immediately.
Reuters recorded nearly 11,000 outage reports at the peak on Downdetector. One analysis from Finance
Magnates estimated that the disruption may have cut roughly $1.6 billion in trading volume for an average forex broker during that period.
The Cloudflare outage lessons were particularly impactful because they followed other large-scale disruptions recently, including one about a year earlier that took a meaningful slice of the internet offline for hours.
Specific Risks of Using a Single Proxy Provider
A LogicMonitor survey reports that global companies experienced at least one unplanned outage within the last three years. That kind of instability becomes your problem when your proxy layer depends on a single provider. With that in mind, here are the risks that come with relying on one proxy service provider:
Technical Failures
Technical failures are the most common single point of failure in a one-vendor proxy setup. They do not require a dramatic trigger. A routine change on the provider side can still interrupt your stack, and because you rely on one vendor, there is no alternative path when their platform experiences instability.
Here is how technical failures usually occur for proxy providers:
Server issues
Each proxy request depends on multiple services the provider controls. The system checks your credentials, selects a route, assigns an IP, and hands the request off through an exit node.
An issue in authentication, rotation, or a regional exit cluster will look like a scraper malfunction on your side, even though the fault is upstream. And without a backup provider integrated, there is no bypass when that happens.
Network disruptions
A provider’s servers may be stable, yet the networks between you and their edge, or between their edge and the target, can still degrade. When that occurs, latency may climb and slow your operations noticeably.
Certain routes may start dropping packets, causing additional retries and lower completion rates. For teams dependent on fresh data, such slowdowns can feel equivalent to downtime.
Maintenance windows
Providers carry out ongoing maintenance, whether scheduled or urgent, and those updates can create sudden drops in available IPs, unexpected session resets, or shifts in rotation logic.
In a single-vendor setup, that impact hits your workflow directly. With a diversified proxy strategy and tested failover, routine maintenance turns into a minor reroute rather than a complete shutdown.
Business Risks
A proxy server may be a critical part of your infrastructure, but it remains a service controlled by a company that can change course without warning - whether due to financial pressures, a strategic pivot, or pricing adjustments.
When your proxy layer relies on a single vendor, those changes affect your workflow immediately. Even with stable code and reliable targets, you can lose coverage because the vendor’s circumstances shift.
Regulatory Risks
Proxy providers do not create IPs. They source them through telecom relationships, ISP partners, SDK-based networks, and data center contracts, all inside legal frameworks that vary by country.
When a regulator tightens rules in a jurisdiction your provider depends on, the provider has to react quickly. Sometimes that means pulling supply from that region to stay compliant. Other times, it means changing how traffic is delivered so they reduce exposure.
If your proxy layer depends on one vendor, their regulatory exposure becomes yours. Decisions driven by regional rules impact your workflow whether you are ready for them or not.
Here is what that can look like for you:
- A regional pool shrinks or disappears. The provider may lose the ability to source residential or mobile IPs in a country, so coverage thins fast.
- Targets in that market stop working at scale. Success rates drop, rotation gets repetitive, and you end up with a blind spot in a region you still need to monitor.
- Traffic rules tighten without notice. To protect itself, the provider may throttle specific use cases or restrict automation-heavy traffic types, even if your work is legitimate.
- Compliance friction increases. You might face new account checks, usage reviews, or geo limits that make routine jobs harder to run.
The key point is that these disruptions may have nothing to do with your code or your targets. They can start with a policy shift or an enforcement move somewhere you never see.
Capacity Limitations
A provider’s IP address sources are not infinite. Some markets have abundant supply, while others are shallow due to costs, legal complexities, or scarcity.
If your company relies on one provider and you start adding more targets, expanding to new countries, or pushing higher concurrency, you can run into signs that the pool is reaching capacity.
This is what proxy provider capacity can look like:
Repeat IPs show up too often
Rotation starts recycling the same addresses quickly. Targets recognize the pattern, the number of failed requests increases, and success rates slide - even though your approach has not changed.
Concurrency hits a hard cap
The provider may throttle or enforce thread limits to protect its IP address pool. Your operations slow down, not because demand fell, but because the upstream can’t safely handle your load.
Some geos stop scaling cleanly
In regions with limited supply, the provider cannot maintain variety, so local scraping becomes unreliable or starts producing data too noisy to trust.
Throughput flattens as you grow
You keep pushing volume, yet completion times stretch and retries consume bandwidth. Your stack still runs, but growth no longer translates into more usable data. In practical terms, your workflows remain operational, but at a reduced speed or a lower accuracy than your business needs.
Benefits of a Multi-Vendor Strategy
By now, it’s clear how much exposure comes with relying on a single proxy provider. That is why teams serious about proxy risk mitigation rarely stay with one vendor for long. They identify multiple primary providers early and build a multi-vendor proxy strategy around that decision.
Here is what diversification gives you in practice:
Business Continuity
If one provider goes down, your work does not have to stop. You reroute traffic to the second pool and keep your operations running. Smaller teams may switch manually, while mature pipelines use proxy failover built into orchestration. Either way, proxy planning for business continuity means downtime becomes a detour, not a shutdown.
Risk Distribution
Single-vendor dependency creates one weak layer that absorbs every hit. A technical outage, a pricing shock, a regional policy change, or a capacity ceiling all land in the same place.
With multiple providers, that exposure spreads out. Each vendor relies on different upstream partners, routing logic, and operational constraints. When one lane wobbles, the rest of your proxy diversification strategy still holds.
Negotiation Power
With a single provider, you are locked into their terms. Pricing might seem stable at first, but leverage shifts over time. If rates raise, pools narrow, or usage rules tighten, your choice is limited to accepting the change or rebuilding under pressure.
With a multi-vendor proxy strategy, you can shift volume, pause spend, or walk away from terms that no longer fit, because alternatives already exist in your stack.
Geographic Diversification
Very few providers have deep coverage worldwide. One might be strong in North America but thin elsewhere. Another might excel in mobile coverage in parts of Europe, while Asia remains inconsistent.
By spreading traffic across multiple vendors, you route based on real pool strength rather than forcing a single provider’s weak regions into your critical path. This keeps your market coverage stable and reduces the chances that a single regional issue becomes your blind spot.
Single-Vendor vs Multi-Vendor Proxy Strategy
How to Practically Implement Diversification
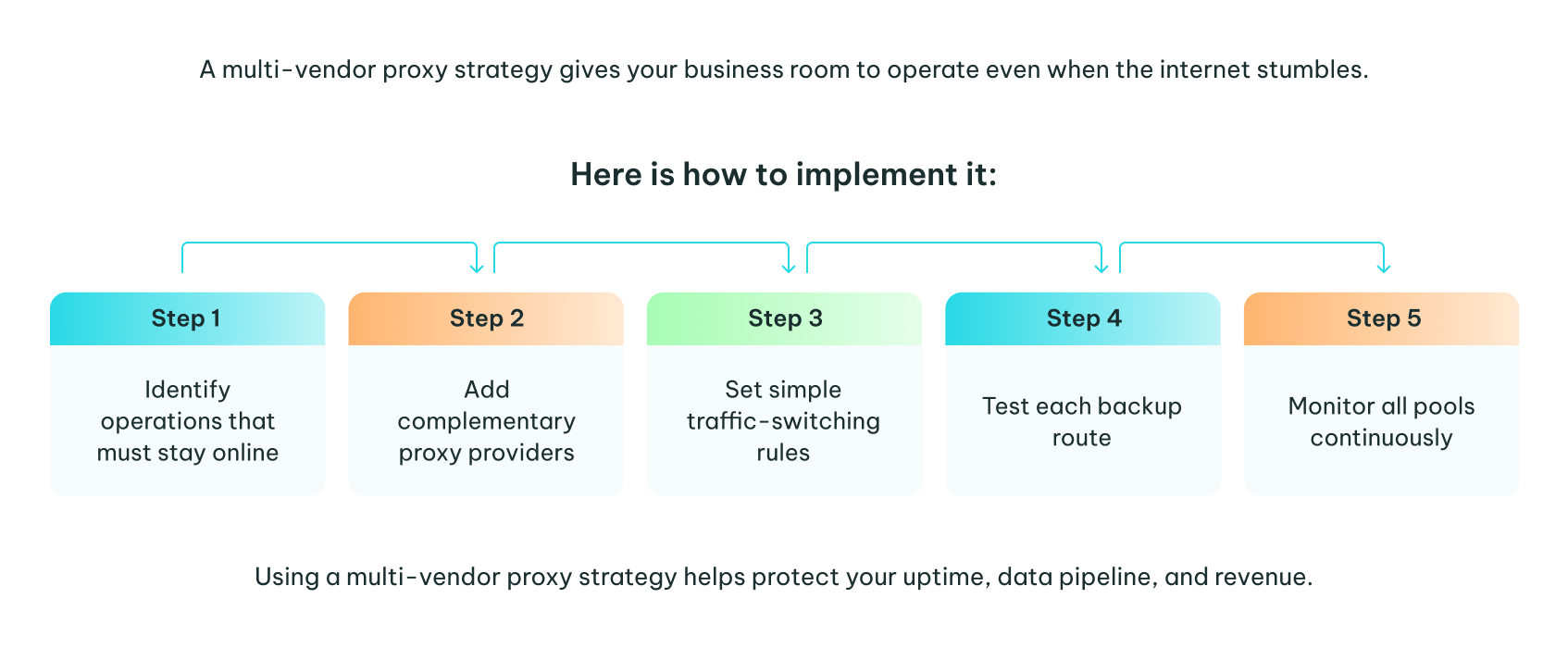
Shifting from single-vendor dependency to a multi-vendor proxy strategy doesn’t have to be complicated. The goal is to build a setup that remains steady even when a provider experiences a technical snag, a policy shift, or hits a capacity ceiling. Think of this process as reinforcing the parts of your system that matter most for operational continuity.
Step 1: Identify the Operations That Cannot Afford Disruption
These are the workflows where a stalled request creates a measurable loss, whether it is missed monitoring windows, delayed data delivery, or the inability to react in real time. Once you identify the sensitive areas, you can center your proxy provider risk mitigation plan around them.
Step 2: Select Providers That Cover Different Strengths
Look for contrasts in their networks, sourcing methods, and regional strengths. This forms the foundation of any proxy diversification strategy, because overlapping weaknesses erase the benefit of redundancy.
Step 3: Integrate Failover Logic Early
Some teams begin with a manual switch. Others build automatic routing that detects timeouts, slow pools, or unusual error spikes and shifts traffic immediately. Both approaches help you avoid the kind of standstill seen in events like the Cloudflare outage.
Step 4: Test Every Backup Routine Before You Rely on It
Failover is only beneficial if it triggers under pressure. Run scheduled checks, rotate through pools, and confirm that each provider can handle the workload you would send during an outage. These tests show whether your proxy infrastructure redundancy is strong enough to carry real traffic.
Step 5: Keep Ongoing Visibility Across All Providers
Track response times, success rates, IP freshness, and pool variety. Doing so helps you identify problems before they escalate into downtime. It also provides the insight needed to shift traffic smoothly as conditions change.
Conclusion
Recent disruptions have shown that even reliable providers can fail in ways that ripple outward quickly. If proxies are in your critical path, the safest approach is to design for that volatility instead of assuming consistency.
A multi-vendor proxy strategy provides operational breathing room during these moments. It doesn’t eliminate downtime entirely, but it prevents a single provider’s issues from halting your workflow.
IPRoyal supports this approach with a broad global pool of reputable residential, ISP, mobile, and datacenter proxy servers. The scale and variety of our network make us a dependable partner when other providers face pressure.


