Web Scraping With C# — The Ultimate Guide
Tutorials

Justas Vitaitis
Web scraping with C# is an invaluable business tool.
In general, web scraping is powerful. It allows you to collect and process data at scale. You can monitor prices, collect user reviews, analyze competitors, check business trends and news, and more.
And web scraping with C# / .NET can be surprisingly easy and performant.
Today we look into how you can scrape websites with C# using - headless browsers . From installing an IDE to collecting data, everything is covered.
In addition, you’ll learn how you can do web scraping without getting blocked .
Let’s get started!
Can You Perform Web Scraping With C#?
Yes, you can do web scraping with C#. You can use code libraries, parsers, or headless browsers. Headless browsers, such as Playwright, allow you to control browsers via code, so you can mimic user behavior, collect data, interact with pages and take screenshots just like a regular user would do.
Is C# Good for Web Scraping?
C# is great for web scraping. It’s performant, and it is very easy to get started. Another advantage is a big community, with lots of code libraries and examples.
It’s quite easy to find someone facing the same issues as you, so you don’t lose too much time figuring out completely new issues.
What Is the Best C# Web Scraping Library?
The best C# web scraping library is Playwright . It allows you to collect data from and interact with any site you want.
But before we dive into it, let’s see why using a headless browser like Playwright dotnet is your best option.
There are mainly four options when it comes to C# web scraping:
- Scrape raw HTML contents using c# cURL or something similar, and use regular expressions — this isn’t a reliable solution since Regex expressions are hard to build, and they can break quite easily.
- Get the HTML contents using c# curl, then send this data to a parser, such as the HTML Agility Pack — this isn’t a great solution either. Parsers only mimic how browsers work with limited features. They don’t load dynamic content, and might not load the contents you need.
- Load the XHR requests, or use an API — this can work well if available. But most sites don’t allow API access for everything you need.
- Use a headless browser — that’s the winner.
A headless browser allows you to mimic a real user controlled via code. Therefore, you use code to open up the browse, load a URL, interact with the page, click on links, fill in forms, click buttons, and scroll. Then you can read some data from this page or take screenshots.
Everything automated.
But when it comes to c# headless browsers, there are two main options - PuppeteerSharp and Playwright dotnet.
What Is PuppeteerSharp?
PuppeteerSharp is a C# .NET library to access headless browsers. It works just like Puppeteer for other languages, allowing you to access the browser APIs and control them via code for automated tasks.
Is Playwright Better Than Puppeteer?
Playwright offers more API options, and it’s way easier to use than Puppeteer. Microsoft is behind the Playwright project. Therefore, they have a lot of resources to ship a very robust product for many languages, including C#.
For this reason, we are going to use Playwright in this tutorial.
Can Websites Detect Web Scraping?
Websites can detect web scraping if the developer doesn’t hide their activity. You need to use tools like proxies and browser metadata to ensure that your visits look legitimate.
It’s worth mentioning that web scraping is perfectly legal. But many sites try to block it.
They do so either by identifying odd user metadata or by identifying suspicious browsing patterns.
The first part is about how legitimate the request looks. Some libraries don’t send user metadata, such as browser, OS, or language. Therefore, target sites can look at these requests and deem them suspicious. After all, most browsers send this data, so this is likely a request made by a bot.
You don’t need to worry about this, though. Playwright connects to a real browser (Firefox, Chrome, and Chromium), so all requests look and feel legitimate because they are.
Website owners can look at your browsing patterns as well. If you visit too many pages, or a specific page at specific times, that might look odd. They can only track these requests down using your IP address, though.
If you use different IP addresses, it’s like a new visitor.
For this reason, you can use . With it, you can connect to sites using a different IP address every time. So, they won’t even know that you are loading more than one page.
Once you sign up for the residential proxies service, you get access to the client area. In it, you can see your connection details:
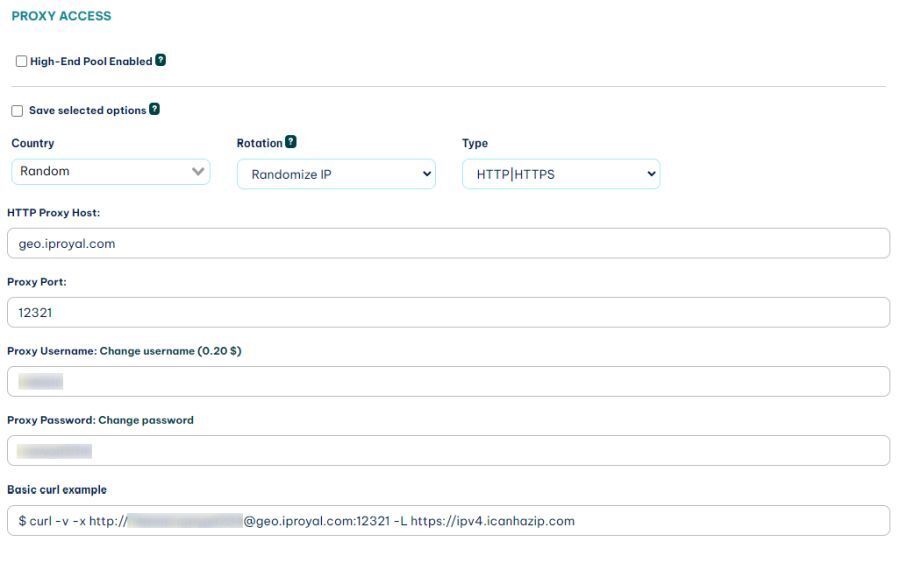
You can use these details in your code to hide your IP address.
Web scraping with C#
This is where the fun starts.
In order to scrape pages with C#, we need to install an IDE, create a new project, and include Playwright. Then you can work on your code, loading a browser, using a proxy, taking screenshots, and extracting data.
Let’s work on each of these points now.
Step 1 — Web Scraping Project Setup
You need an IDE to edit code. Visual Studio is a great free option for Windows, macOS, and Linux if you don’t have one.
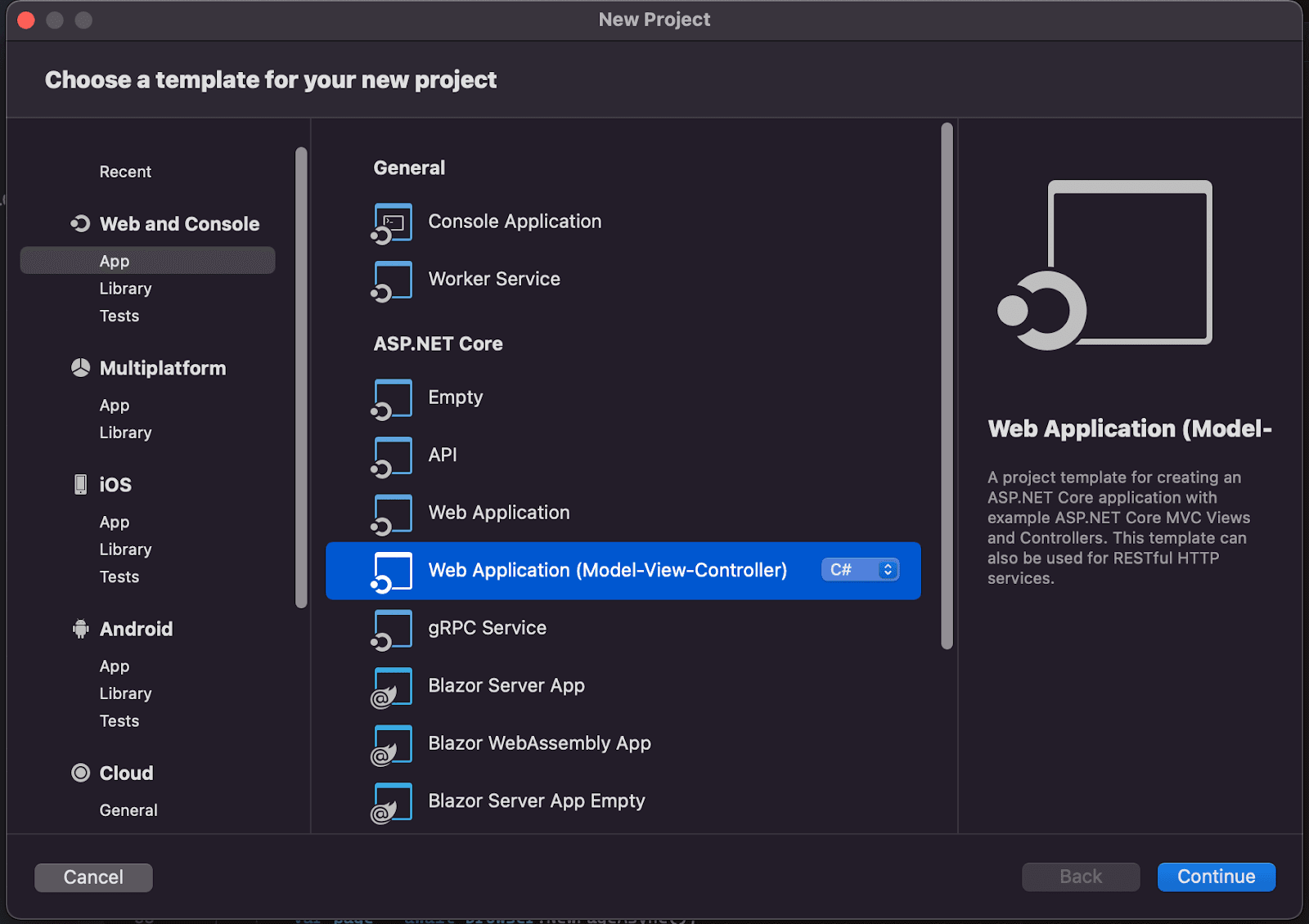
Once you have your IDE installed, create a new project to add your code. You can use the “Web Application (Model-View-Controller)” project type:
Then, in order to scrape pages using a headless browser, you need Playwright. You can include it in your project using Tools > Manage NuGet Packages > Search for Playwright:
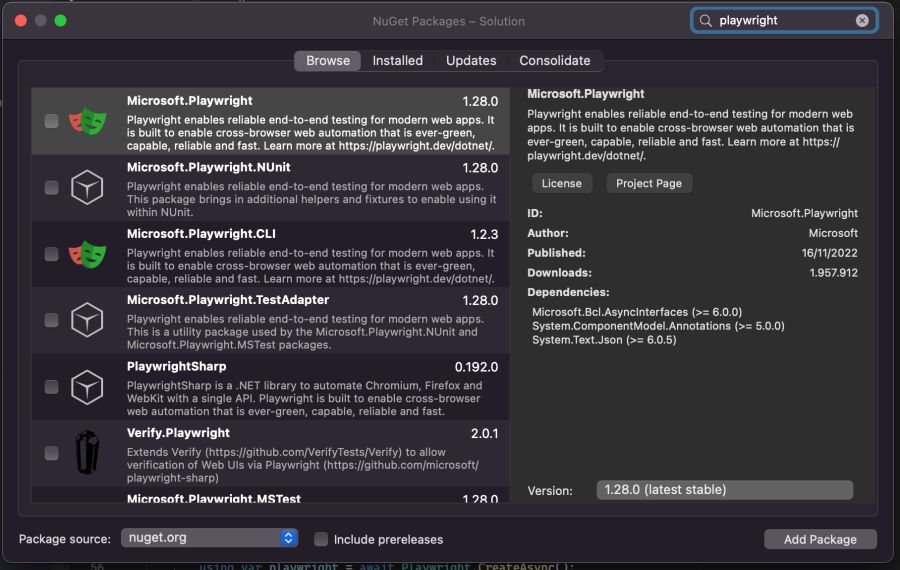
Make sure you check the package “Microsoft.Playwright” and click “Add Package”.
That’s all you need in terms of setup.
To make sure it is working as it should, edit the /Controllers/HomeController.cs file. Replace your current Index() with this one:
public async Task<IActionResult> Index()
{
var proxy = new Proxy
{
Server = "http://geo.iproyal.com:12321",
Username = "username",
Password = "password"
};
using var playwright = await Playwright.CreateAsync();
await using var browser = await playwright.Chromium.LaunchAsync(new() {
Proxy = proxy
});
var page = await browser.NewPageAsync();
await page.GotoAsync("https://ipv4.icanhazip.com/");
await page.ScreenshotAsync(new() { Path = "screenshot.png" });
return View();
}
In general, this code is loaded when you load your server’s homepage.
The first bits of the code create a variable for the proxy information. Make sure you replace them with your own URL, username, and password.
Then, you create a new playwright instance. That’s the main instance that is used to load everything else.
Next, you are loading a Chromium browser using the proxy options loaded before.
The following few lines are there to open a new browser tab, navigate to a page and take a screenshot.
Run this code, and you’ll get a screenshot in your project’s folder. In it, you’ll see the IP address of your proxy, not your own.
This is the playwright c# web scraper screenshot:

And this is what I see when I visit https://ipv4.icanhazip.com/ directly:
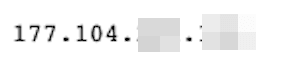
This means that the C# web scraper request went through the proxy. Cool, right?
Let’s explore your C# web scraper a bit further.
Step 2 — Take screenshots
You can take a simple screenshot with:
await page.ScreenshotAsync(new() { Path = "screenshot.png" });
But there are many other options to pick from.
For example, you can take a full-page screenshot with this code:
await Page.ScreenshotAsync(new()
{
Path = "screenshot.png",
FullPage = true,
});
And you can even capture a screenshot of a specific element with this code:
await page.Locator(".header").ScreenshotAsync(new() { Path = "screenshot.png" });
Notice how you are accessing ScreenshotAsync from the locator, not the page. That’s how you select page elements as well. In this case, the code snippet selects the “.header” section and takes a screenshot.
Step 3 - How to Read Data From a Website Using C#
If you want to extract data from an element, you need to locate it. So you can use locators to extract data from pages in your C# web scraper.
You can select elements by:
- Text contents
- CSS Selector
- Combine text and CSS selectors
- xPath
- React selector
- Vue selector
- Layout positions (left of X)
Here are some examples:
Text Selector
With this option, you can select elements based on their text contents. So you can select a button with the text “home” and click on it.
Therefore, you don’t need to know the exact CSS selector, xPath, or anything else about that element.
This is quite handy if the page structure changes too much. You can use this code:
await page.Locator("text=Home").ClickAsync();
Or you can even use the shorthand version of it, with single quotes wrapped in double quotes:
await page.Locator("’Home’").ClickAsync();
This is assumed to be a text selector.
You can play around with exact matches and partial matches as well, using quotes for exact matches and the “has-text” selector for partial matches.
await page.Locator("a:has-text(‘Home’)").ClickAsync();
CSS Selectors
These are quite simple yet very powerful. Almost anything you can imagine as a CSS selector is fair game, including pseudo-selectors.
You can use the simple ID selector:
await page.Locator("#button").ClickAsync();
And you can use complex combinations of CSS selectors:
await page.Locator("article:has(div.gallery)").TextContentAsync();
By the way, you can load content from an element using the TextContentAsync() function above.
Playwright vs Puppeteersharp xpath
XPath is another powerful selector. You can get the xPath for any page element. Open the browser inspector, inspect an element, then on the browser inspector right-click an element, select Copy > xPath
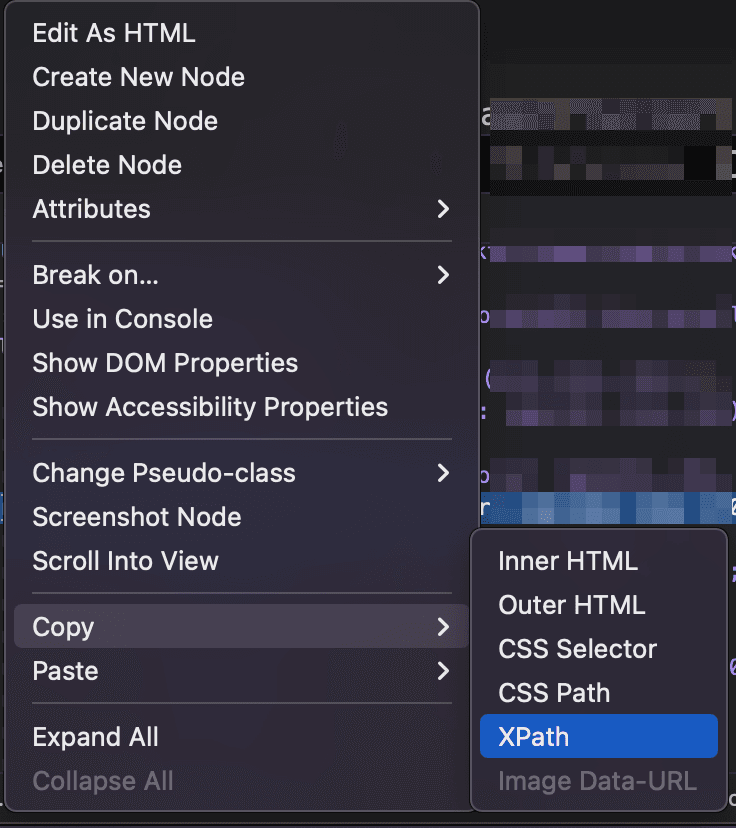
This gives you a unique selector just for that element.
Then you can use it in your headless browser, be it Playwright or PuppeteerSharp.
await page.Locator("a >> nth=-1").ClickAsync();
This clicks the last link on a page.
Conclusion
Today we learned web scraping with c#. We looked at simple questions, such as the current methods for web scraping, to complex tasks, such as loading elements based on complex CSS selectors.
We hope you’ve enjoyed it, and see you again next time!
FAQ
C# Only one compilation unit can have top-level statements
This usually happens when you have multiple entry points to your application. Make sure you didn’t create additional files and make sure you didn’t create more than one function to initialize your server.
ERROR: Playwright does not support Chromium on mac12
This typically happens when you have an older Chromium version or if your project can’t access Chromium for some reason.
Update everything, then double check if Chromium is available on your computer.
Microsoft.Playwright.PlaywrightException:Executable doesn't exist
This happens when you don’t have Chromium in your computer yet.
Open your project folder, then go to /bin/debug. In it you’ll see the actual folder name you need to use.
That’s because the error message tells you to run “pwsh bin/Debug/netX/playwright.ps1 install”. So you can replace X with your actual folder name.
In addition, if you don’t have PowerShell, you’ll need to install it.


