Puppeteer Sharp and XPath: The Ultimate Web Scraping Guide
Tutorials

Justas Vitaitis
If you want to start web scraping, Puppeteer Sharp is a formidable tool.
With Puppeteer Sharp, you get the easy-to-use headless browser commands from Puppeteer in C#, a robust and performant programming language. However, there are some challenges you need to overcome to scrape data from the web successfully.
The first is telling Puppeteer what data to scrape. There are many options in terms of selectors, and sometimes CSS can be ambiguous.
Then, you need to avoid getting blocked. Website owners try to block web scrapers, and you need to be aware of that if you want to keep collecting data.
And lastly, you need to know how to interact with your target pages, execute functions, send form data, and emulate real user behavior.
Today you’ll learn how to overcome all these issues. We are using a combination of XPath, residential proxies, Puppeteer Sharp , and a bit of code to bring it all together.
You will learn how to scrape data, but also how to use XPath, how to take screenshots, print PDFs, interact with forms, click buttons, and so on.
With this knowledge, you can build a web scraper for many uses. But this ties particularly well with programmatic websites.
Recently, we worked on a 4-part series on how you can build a programmatic SEO website from start to finish. From idea to implementing, a site that has potential to bring millions of visits. If you are curious, here are the four main topics we are covered in this series:
- A programmatic SEO blueprint - What is programmatic SEO, why you should do it, how to plan your site, how to research keywords.
- How to perform automated web scraping in any language - How to pick the right programming language and libraries depending on your target sites, how to set up the backend for automated web scraping, and the best tools for web scraping.
- How to build a Facebook scraper - Here, we dive into how to collect data from our target site, how to collect data from other sites (such as Amazon), how to process data, and how to deal with errors.
- Easy programmatic SEO in WordPress - In the last part of the series, you are going to learn how to use your scraped data to build a WordPress site.
If you want, you can use Puppeteer Sharp to replace Playwright, on the second step of this series.
Let’s get started!
What Is Puppeteer Sharp?
Puppeteer Sharp is a C# library to port the NodeJS library Puppeteer. It allows you to control headless browsers via code. This means you can perform any action that a real user would programmatically.
You can use it for software testing, automation, and web scraping. In our example, we focus on web scraping and how you can use these functions to extract data from sites.
How to Start Using Puppeteer Sharp?
To use Puppeteer Sharp, you need an IDE, like Visual Studio. Create a new web application project in it:
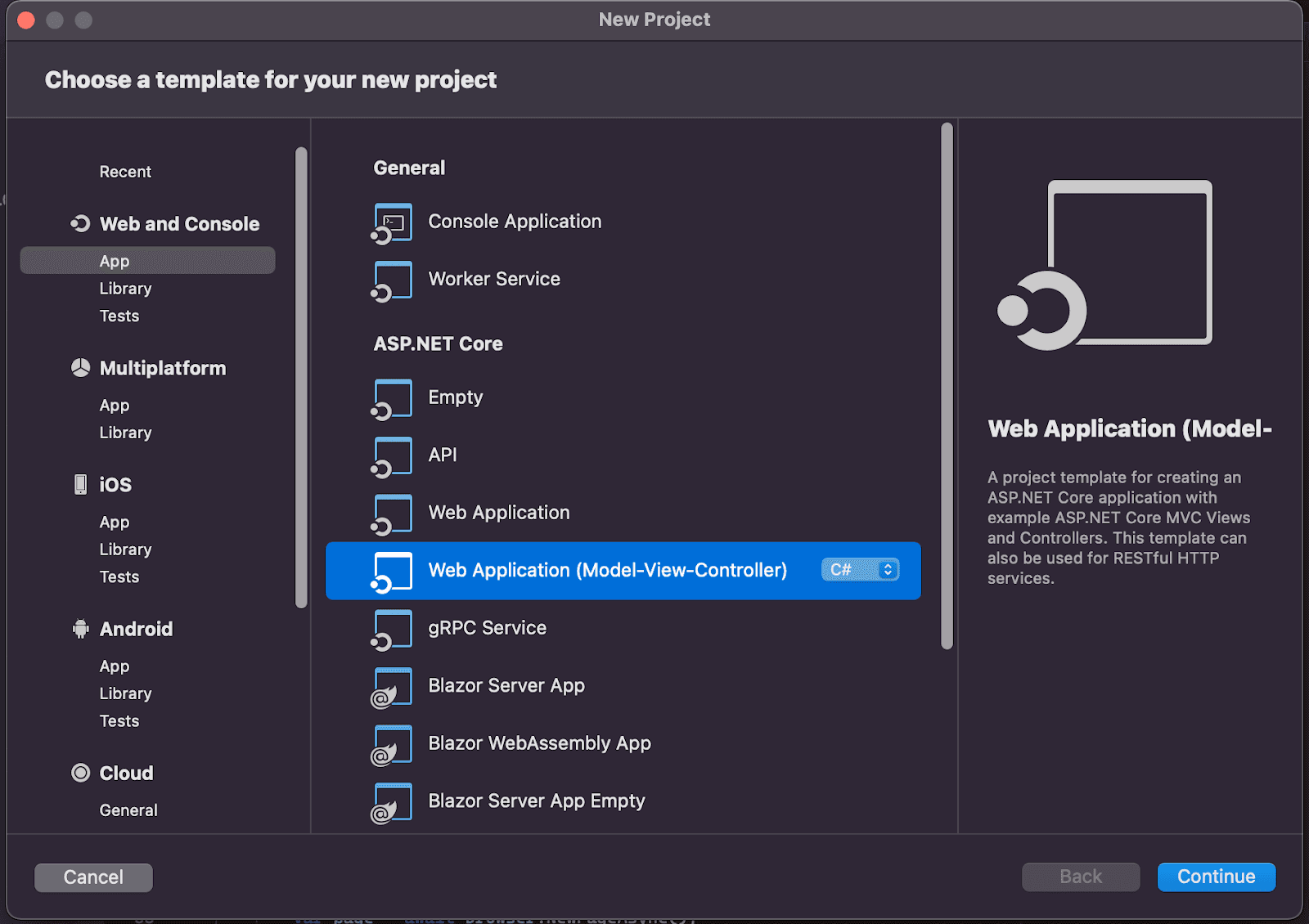
Go to Tools > Manage NuGet Packages > Search for Puppeteer, and you’ll find PuppeteerSharp as one of the top options.
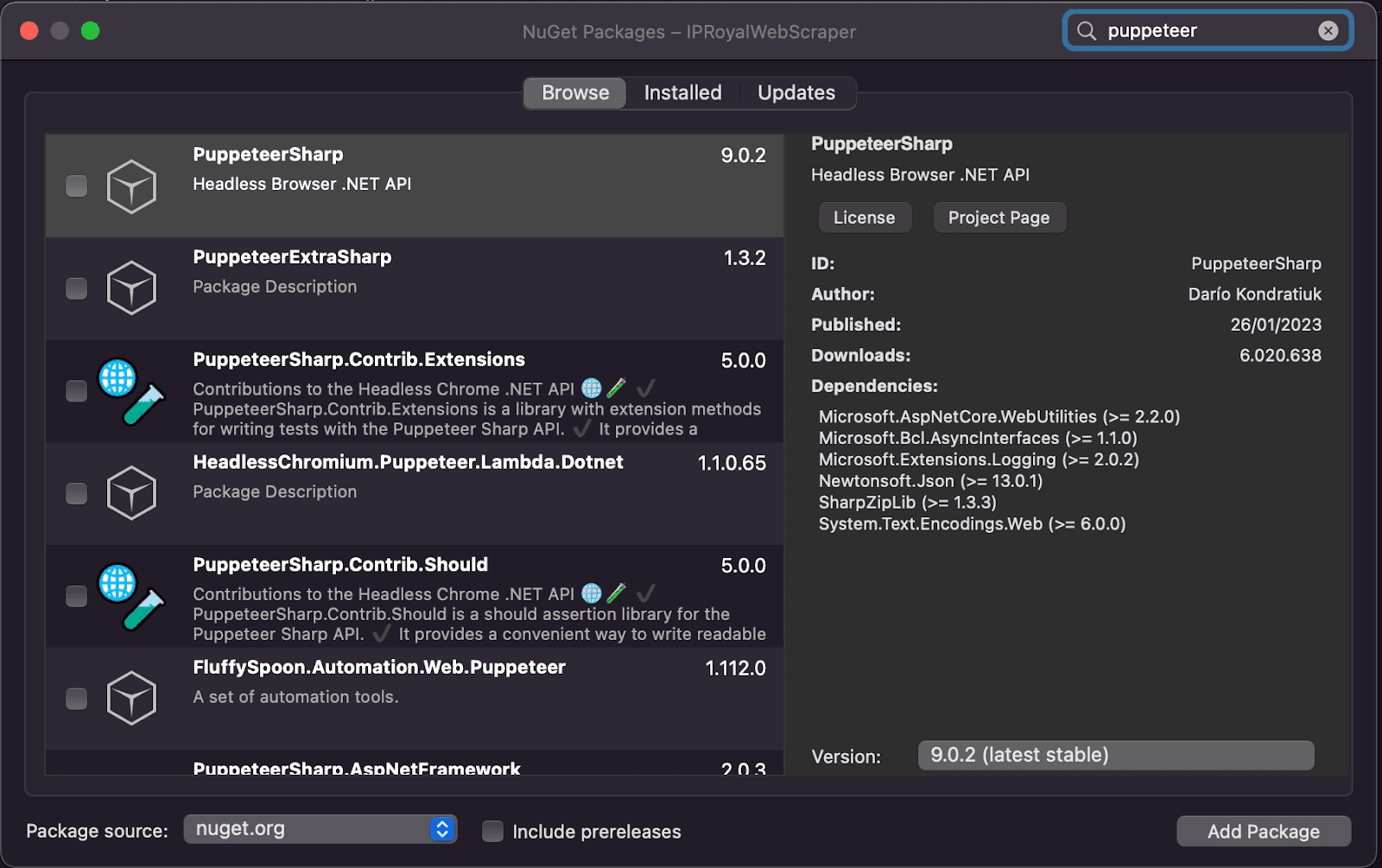
Check the little box, click on “Add Package”, and you are good to go.
Can I use XPath in Puppeteer?
You can send information about which elements your headless browser will interact with using locators. These locators can be CSS selectors , checks for text contents, checks for layout components (which element is to the right of another element), and XPath.
The XPath of an element is the address of that element on the DOM tree. It can be a generic selector, like CSS (targeting multiple elements), but it can easily identify a specific element unambiguously.
For example, a usual CSS selector looks like this:
html body div#container article div.text h2
On the other hand, an XPath looks like this:
/html/body/div[4]/div/article/div[1]/div[2]/h2[1]
In this case, the XPath tells you which branches of the DOM tree you need to follow, finding precisely the element you want.
How Can I Find the XPath of a Button?
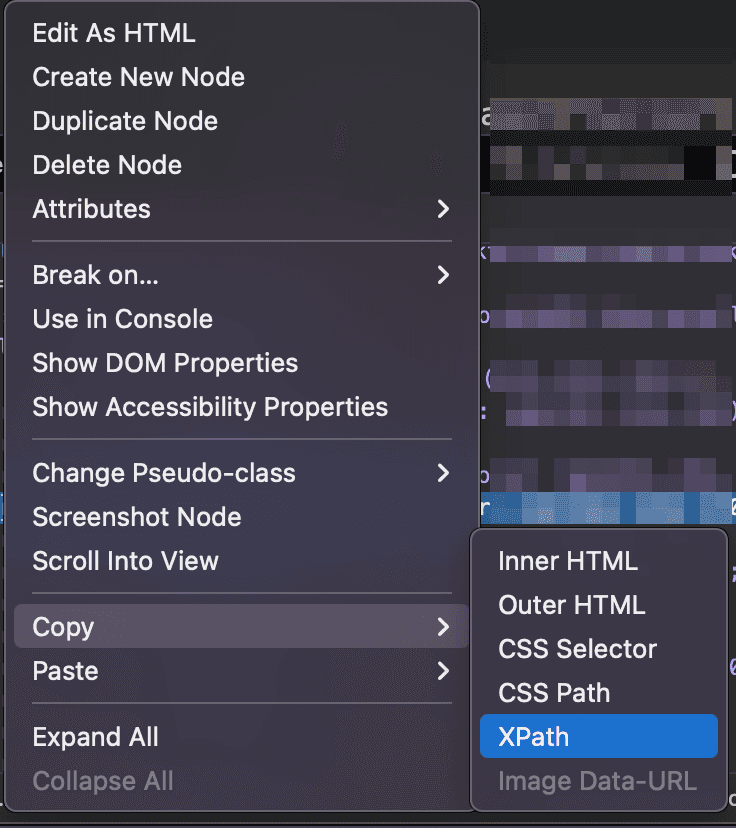
You can find the XPath of a button or any element using the code inspector. Right-click your target element and click on “Inspect”. Then, on the Inspector panel, right-click your desired element, and click on Copy > XPath:
How Do I Select a Button Using XPath?
Once you have the XPath for an element, let’s select that element. Use this code snippet:
using var browserFetcher = new BrowserFetcher();
await browserFetcher.DownloadAsync(BrowserFetcher.DefaultChromiumRevision);
var browser = await Puppeteer.LaunchAsync(new LaunchOptions
{
Headless = true
});
var page = await browser.NewPageAsync();
await page.GoToAsync("https://en.wikipedia.org/wiki/Mario_Kart:_Super_Circuit");
var link = await page.XPathAsync("//html/body/div[1]/div/div[3]/main/div[2]/div[3]/div[1]/p[3]/a[1]");
var innerTextHandle = await link[0].GetPropertyAsync("innerText");
var innerText = await innerTextHandle.JsonValueAsync();
// Use the link text in any way you want to
Trace.WriteLine(innerText);
return View();
This code starts up the Puppeteer Library, creates a new browser window, a new page, and navigates to a wiki page. Then it selects a link from the content using the XPath. Notice that the XPathAsync function returns an array of all results, even if you have just one item.
So in order to interact with that element, you need to access the array element , as we did with link[0].
The CSS equivalent of that selector could be:
var link = await page.QuerySelectorAsync("a[href='/wiki/List_of_best-selling_Game_Boy_Advance_video_games']");
What Can I Use Instead of XPath?
You can use XPath to select your elements. Some other alternatives aren't as strict, such as CSS selectors, which might return more elements. You could use the :nth-child() or nth-of-type CSS pseudo-class along with the > separator to get the same result as the XPath selectors, specifying the exact element you want to follow in the DOM tree.
For example, this XPath:
//html/body/div[1]/div/div[3]/main/div[2]/div[3]/div[1]/p[3]/a[1]
Is the equivalent to this CSS selector:
html > body > div:nth-of-type(1) > div > div:nth-of-type(3) > main > div:nth-of-type(2) > div:nth-of-type(3) > div:nth-of-type(1) > p:nth-of-type(3) > a:nth-of-type(1)
How to Use a Proxy in Puppeteer Sharp?
If you want to scrape pages with Puppeteer Sharp, you must avoid detection. Even though web scraping is legal, a lot of sites try to block it since it can give other businesses a competitive advantage by analyzing data at scale.
These sites detect web scrapers by looking at a few indicators in the connection request. One of them is the connection headers . Some scraping libraries won't set the correct browser headers out of the box, and they can be detected using this method. But since you are using Puppeteer Sharp, you are actually using a real browser to connect to these sites. Therefore, the request is just like it would be if you were visiting that page manually.
Another point website owners look at is the requested IP address. It helps them identify users who are loading a lot of pages, who are loading pages too fast, or who load pages at the same time every day.
You can circumvent this by using a service like IPRoyal's residential proxies . With it, you get a new IP address for each request, making it impossible for them to track you down. From their point of view, these are different users from different places in the world loading pages.
Once you sign up for the residential proxies service, you get access to the client area. In it, you can see your connection details like this:
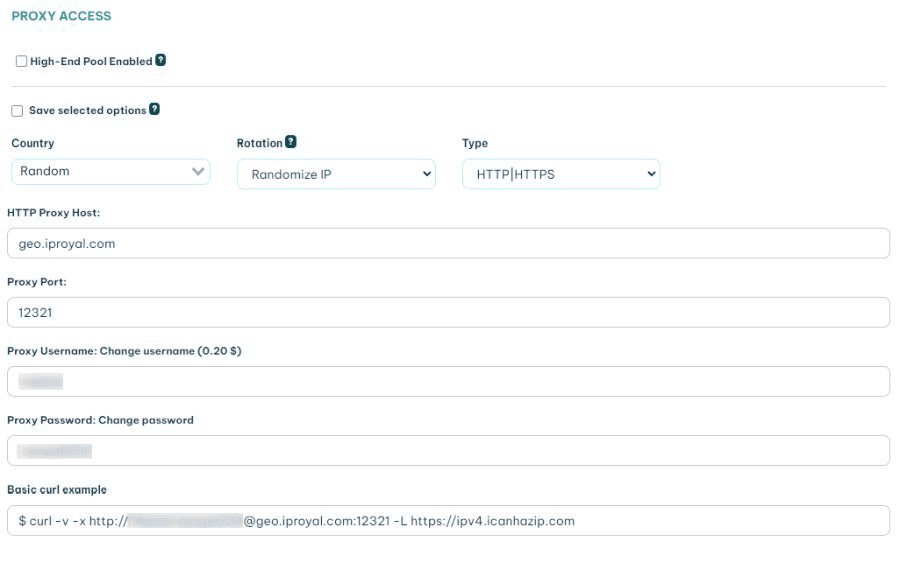
Now it's time to use it in your code.
As you saw in the previous code snippets, you can use LaunchOptions to pass arguments to Puppeteer. You can start your browser using a proxy with this code:
var browser = await Puppeteer.LaunchAsync(new LaunchOptions
{
Headless = true,
Args = new[] { "--proxy-server=geo.iproyal.com:12321" }
});
And use this snippet to authenticate your proxy connection if you don’t want to whitelist your current IP address:
await page.AuthenticateAsync(new Credentials() { Username = "username", Password = "password" });
Here is a snippet to bring it all together:
var browser = await Puppeteer.LaunchAsync(new LaunchOptions
{
Headless = true,
Args = new[] { "--proxy-server=geo.iproyal.com:12321" }
});
using (var page = await browser.NewPageAsync())
{
await page.AuthenticateAsync(new Credentials() { Username = "username", Password = "password" });
await page.GoToAsync("https://ipv4.icanhazip.com/");
await page.ScreenshotAsync("proxy-screenshot.png");
}
You can do anything you want once the browser page is ready. Don’t forget to play around with timeout limits to ensure you have enough time to process your code and the proxy request.
How to Scrape Anything with Puppeteer Sharp?
Now let's explore a few different use cases for your web scraping needs with some examples. Here you'll see a list of tasks and how you can achieve them using Puppeteer Sharp and XPath. Don't forget to add your proxy details at the beginning of your code, and you can always replace the XPath selector with the CSS selector using QuerySelectorAsync instead.
How to Take a Screenshot with Puppeteer Sharp
You can take a screenshot of a page using this code snippet:
var page = await browser.NewPageAsync();
await page.GoToAsync("https://en.wikipedia.org/wiki/Mario_Kart:_Super_Circuit");
await page.ScreenshotAsync("screenshot.png");
You can change the browser size to change the image output. In addition, you can query a specific element and take a screenshot:
var page = await browser.NewPageAsync();
await page.GoToAsync("https://en.wikipedia.org/wiki/Mario_Kart:_Super_Circuit");
var sidebar = await page.XPathAsync("//html/body/div[1]/div/div[3]/main/div[2]/div[3]/div[1]/table");
await sidebar[0].ScreenshotAsync("sidebar.png");
How to Use Puppeteer Sharp to Convert HTML to PDF
You can save pages as PDF files. To use Puppeteer Sharp to turn HTML pages into PDFs, you can use this code:
var page = await browser.NewPageAsync();
await page.GoToAsync("https://en.wikipedia.org/wiki/Mario_Kart:_Super_Circuit");
await page.PdfAsync("page.pdf");
Just like with screenshots, you can change the browser sizes, which also changes the PDF sizes as well.
How to Define a Puppeteer Sharp Timeout
You can control the Puppeteer Sharp timeout using the NavigationOptions class. So instead of a simple GoToAsync command, you can use something like this:
var page = await browser.NewPageAsync();
await page.GoToAsync("https://en.wikipedia.org/wiki/Mario_Kart:_Super_Circuit", new NavigationOptions { Timeout = 60000 });
Set the timeout value you want in milliseconds here. The default value is 30 seconds, so it’s set as 30000.
How to Use Puppeteer Sharp to Fill In and Send Forms
You can interact with forms using many methods. It’s possible to type down text and interact with pages, which is quite a simple way to do it. In this case, the main downside is that you need to use a CSS selector. But then, you can use an XPath selector to click on the “submit” button.
How to Set Input Value
You can set values to inputs with the TypeAsync method on your page variable. In this case, you will need to use a CSS selector, not a XPath. Here is how to type into the search box for the Wikipedia page (equivalent to the XPath /html/body/div[1]/div/header/div[2]/div/div/div/form/div/div/div[1]/input ):
await page.GoToAsync("https://en.wikipedia.org/wiki/Mario_Kart:_Super_Circuit");
page.TypeAsync("html > body > div:nth-of-type(1) > div > header > div:nth-of-type(2) > div > div > div > form > div > div > div:nth-of-type(1) > input",”value to type”).Wait();
Then you can perform the search operation by pressing the return key or clicking the search button with some C# code.
How to Use Puppeteer Sharp to Evaluate JS Functions
You can use PuppeteerSharp to evaluate JS code on your target pages. This is similar to opening the developer tools and testing JS code.
Here is an example:
using (var page = await browser.NewPageAsync())
{
var four = await page.EvaluateExpressionAsync<int>("()=> 2 + 2");
var myObject = await page.EvaluateFunctionAsync<dynamic>("(value) => ({my: value})", 4);
Console.WriteLine(myObject.my);
}
In this code, we first create a variable to store the result of a JS function. The second example evaluates a JS function based on a passed variable (4), and then we log this variable in the console.
You could use similar snippets to extract data from pages directly, such as prices, stock, charts, etc.
With EvaluateExpressionAsync, you can run any JS code you want. Additionally, you can pre-process your data and add and remove elements, making it easier to deal with the scraped pages in your C# code or save it to your database.

Puppeteer Sharp vs Playwright
If you are wondering which library you should pick, the answer is simple. Both are great options, so you can pick the option that you are most comfortable with.
Playwright is updated more frequently and is more future-proof, though. But Puppeteer Sharp works fine as well, and it is a good option for quick projects and prototyping.
Conclusion
Today we looked into how you can use PuppeteerSharp and XPath to perform many actions. You can use these actions in your programmatic SEO website or your scraping tasks in general.
We hope you’ve enjoyed it, and see you again next time!
FAQ
browser.newpage is not a function
Make sure that you have premises and that you are using async functions in your entire code. Otherwise, you won’t be able to retrieve the correct browser status.
execution context was destroyed most likely because of a navigation
When you navigate to other pages, you may lose access to data in some of your variables since they aren’t there anymore. So you might be telling Puppeteer Sharp to deal with an element that doesn’t exist in that context.
ElementHandle[] does not contain a definition for 'GetPropertyAsync'
The full error message, in this case, is probably something along the lines of:
ElementHandle[] does not contain a definition for 'GetPropertyAsync' and no accessible extension method 'GetPropertyAsync' accepting a first argument of type 'IElementHandle[]' could be found (are you missing a using directive or an assembly reference?)
This happens if you try to access classes from elements loaded using XPath without accessing the array item. When you run page.XPathAsync(“XPath”), C# is always returning an array with the elements, even if it’s just one. Thus, you can only get a property of that element using variablename[0], for example.


