'/%3e%3cellipse%20opacity='0.34'%20cx='327.5'%20cy='339'%20rx='264.5'%20ry='264'%20fill='url(%23paint1_linear_12724_35442)'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_12724_35442'%20x1='327'%20y1='-2.524e-06'%20x2='327'%20y2='389.286'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%2327D9E5'/%3e%3cstop%20offset='0.927406'%20stop-color='%23004047'%20stop-opacity='0'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_12724_35442'%20x1='328.02'%20y1='74.7771'%20x2='328.02'%20y2='395.312'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%2327D9E5'/%3e%3cstop%20offset='0.927406'%20stop-color='%23004047'%20stop-opacity='0'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)
What Is a Dataset? A Breakdown of Types and Uses
News

Justas Palekas
Dataset is a fundamental concept for machine learning models, data analytics, and statistical analysis in general. Without structuring data in organized and standardized sets, it would be difficult to draw conclusions or even find the needed data points conveniently.
Much more decision-making rests on data quality than you might think. Web scraping and other forms of online data collection are no exception. Learning how to format the collected data starts with the knowledge of fundamental concepts like datasets.
Dataset Definition
A dataset (or data set) is a collection of information composed of different elements standardized to be analyzed, stored, or otherwise processed as a unit. The information can be random, but usually, elements in datasets are topically related.
For example, a dataset may contain information from the same website, company sales leads, competitor pricing, stock market data, and similar. The data must not necessarily be numbers. It can also include images, text excerpts, and even video or audio recordings.
Datasets are commonly stored in formats like CSV, XLSX, JSON, or SQL. A simple spreadsheet (XLSX, for example), may represent structured data points in rows and element features in columns.
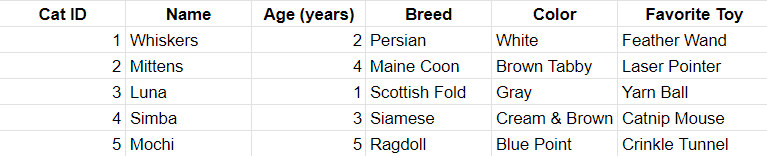
Key Elements of a Dataset
Our example dataset is quite simple. In practice, datasets are much larger, including numerous different elements and their features. However, all data sets have a few key elements that separate them from other similar data analysis concepts.
- Elements : entities on which the data is collected. In our example case, cats.
- Variables : attributes we can prescribe to our elements that can change, such as the cat’s age.
- Attributes : characteristics that are not subject to change, such as cat color. Even if the cat’s color changes, it will still have an attribute of having a color.
- Data points : single pieces of data that represent specific values, such as “2”, “Siamese breed,” “Yarn ball,” etc.
Various statistical measures can be applied to the data using exploratory data analysis to show general patterns or properties. Standard deviation, kurtosis, spread, skewness, correlation, and probability are some of the most common examples.
Often, they are treated as additional elements of a dataset. The amount of analysis possible may differ depending on the type of elements and variables. Datasets with numerical values often have more statistical properties.
It’s also important to note that our example dataset consists of structured data. While a big part of a data scientist’s work is to structure data, it’s not a requirement for something to qualify as a dataset. Here’s the same dataset in a semi-structured JSON format.
[
{
"CatID": 1,
"Name": "Whiskers",
"Details": {
"Age": "Two years",
"Breed": "Persian",
"Color": "White"
},
"FavoriteToy": "Feather Wand",
"CutenessRating": 9
},
{
"CatID": 2,
"Name": "Mittens",
"Age": 4,
"Breed": "Maine Coon",
"Color": "Brown Tabby",
"FavoriteToy": ["Laser Pointer", "String Toy"],
"CutenessRating": "Ten out of ten"
},
{
"CatID": 3,
"Name": "Luna",
"Breed": "Scottish Fold",
"Color": "Gray",
"FavoriteToy": null
}
Types of Datasets
There are many types of datasets depending on the various features they can have. Since there are so many types, it's easier to think of datasets when we distinguish two larger categories. Some types of datasets are defined by what data is used, others by how they are structured.
Based on Types of Data
- Qualitative datasets use data that cannot be represented by numbers but can be recorded otherwise, i.e., subjective answers to open-ended questions in interviews.
- Quantitative datasets use measures of values and counts expressed in numbers, i.e., number of sales, cats' age, speed of movement.
- Categorical datasets use variables that can take only a limited number of possible values. These datasets are rare, but categorical data is common, i.e., Marital status, temperature.
- Multivariate datasets are created from data where two or more elements are correlated to each other, called bivariate or multivariate data, i.e., height and weight, the relation between age, breed, and color.
- Web datasets use data gathered from websites with various web scraping methods, i.e., pricing data, search engine rankings, and sales leads.
- Multimedia datasets consist of images, videos, audio recordings, and other types of data.
Based on How Data is Structured
- Structured datasets use only data that has a well-defined format. Such datasets can come in multiple formats and are generally best for data analysis.
- Tabular datasets structure data in rows and columns. Such was our first example dataset.
- Non-tabular datasets are still structured but not in rows and columns. Instead, some other format, such as JSON code, is used. Often, datasets are non-tabular because multimedia data is used.
- Semi-structured datasets have data that is partially standardized and structured. Such was our second dataset example.
- Unstructured datasets do not have a well-defined format. Unstructured data is difficult to analyze since it can be of different types and formats.
Dataset Examples
Quality datasets are the backbone of most sciences and business ventures today. Machine learning models and data scientists use them daily to analyze trends or inquire about natural phenomena. Many of the datasets used are available online for everyone to analyze.
- The World Health Organization has lots of interesting datasets on the state of global health care.
- The United States Government's open data website provides thousands of datasets on various sectors of the country.
- CERN Open Data Portal provides petabytes of datasets from research performed at CERN.
- The International Genome Sample Resource provides datasets about human genetic variation between different populations.
- Kaggle is an online community of data scientists and machine learning specialists that hosts hundreds of datasets.
The data quality in most free datasets is good enough to practice data analysis without collecting your own data. Official sources are often used by professional data scientists to draw conclusions, but they are unlikely to reveal hidden insights. If you want to find even more datasets, there's Google Dataset Search .
Dataset vs. Database
The concepts of a dataset and a database are related in terms of describing the organization and management of data. The differences become clear from a closer look at definitions.
- A dataset is a collection of information on different elements that are often related but not necessarily structured. Usually, datasets are static and function as a unit for statistical analysis.
- A database refers to a structured collection of data held electronically on a computer system, usually servers. Its purpose is to provide long-term storage, access, and manipulation of data.
The structure of databases is usually more complex, involving various rules and indexes for accessing data. They are administered using database management tools, such as MySQL or Oracle RDBMS. One database can contain multiple different, not necessarily related, datasets.
For example, an airline reservation system might be considered a database that holds various datasets about flights. Similarly, the universal health coverage dataset can be found in the WHO database we provided earlier.
Dataset vs. Data Collection
Data collection is the process of gathering and evaluating information on the required elements. It's done with the purpose of performing later data analysis and drawing needed conclusions.
A dataset refers to data that has already been collected and can be used by data scientists to draw conclusions. One or multiple datasets are the result of successful data collection efforts. So, a dataset is the end result, while data collection is the process.
Technically, data collection can be performed manually, but most data analytics processes, or the training of machine learning models, require too much data to gather without automation. As such, online data collection is often associated with web scraping .
It's the process of using automated bots, called scrapers, to visit websites and collect publicly available data. Simply put, the bot first makes an index of what's available and extracts the raw data. Then, the unstructured data is converted (parsed) into one of the common formats, such as JSON.
Often, the data needs to be cleaned from redundancies and standardized further to analyze trends or find insights. For example, a web scraper might collect pricing data that will need to be further cleaned from other unnecessary elements and prepared in multiple formats to start working with it.
How to Create a Dataset?
Creating a dataset isn't that difficult. As long as it has different elements with attributes and can be processed as a unit, it is a dataset. You can simply list items on your desk separated by a comma, and it will be a Comma-Separated Values (CSV) dataset. Here's an example.
The process of making complex types of datasets, such as ones with multivariate data or lots of information, requires more steps. Depending on the data type, each of them can take different lengths or have varied completion order. The steps below should give you a general picture.
Steps for Creating a Dataset
1. Objective Start by defining where the collected data will be used. It's crucial for keeping the purpose and scope of your database in place.
2. Data sources Identify the relevant data sources and determine the best ways to collect it.
3. Data collection process Collect the data that is needed. Be sure to have all the required permissions beforehand.
4. Data cleaning Raw data requires some preparation - remove errors and duplicates, standardize notations, and replace or mark missing values.
5. Organizing data Transform cleaned data into the needed data format suitable for your analysis.
6. Integration Include data from other datasets and ensure that everything is in the same format and without any data conflicts.
7. Validation Run various statistical analyses and cross-check with other similar datasets to confirm data accuracy.
8. Documentation Include metadata. Needed definitions or usage instructions.
9. Storage and access Ensure that the dataset is saved and backed up on a reliable database so that it can be accessed without any errors.
10. Maintenance Keep your dataset up to date, and users can track version changes.
Use Cases of Datasets
Datasets aren't used only by data scientists. They are a concept of almost any business and scientific field since it's the start of analyzing data. Here are some prominent examples.
- Training machine learning models rely on access to large datasets of data that can be organized in multiple formats.
- Scientists collect data and analyze it in datasets to research various social and natural phenomena.
- Social media algorithms need datasets about user activity to create content recommendations.
- Government institutions operate datasets to shape policy decisions.
- Companies use various datasets to perform customer behavior, feedback, sentiment, pricing, or other types of analyses.
Benefits of Using a Dataset
Those unfamiliar with the concept of datasets might think of it as complicated and avoid operating in datasets when analyzing data. It's a grave mistake since the truth is actually the opposite. The benefits of using datasets are all aimed at improving convenience when analyzing data.
- Simplifying processes
Structured datasets organize data into standardized units, which allows the process of finding information to be simplified or even automated. - Improving user experience
Finding data or analyzing it is difficult if it isn't in a dataset, especially if you weren't the one collecting data. - Saving time
In large organizations, creating and maintaining databases with various datasets saves employees time when completing tasks. - Aiding decision-making
Decisions based on accurate data are better. Most businesses and government institutions strive to collect such data and then operate it in datasets to make better decisions.
Conclusion
We covered here the basics of what the concept of dataset means and how it differs from other related terms. Data scientists have much more theory behind this concept, but it's enough for practice. The rest is collecting the data and analyzing it yourself.


