
Web scraping is a powerful tool for collecting data from websites, whether it’s tracking stock prices in real-time, monitoring product availability, or gathering news articles. It involves using automated tools or code to efficiently extract information. If you decide to customize your own web scraper, you will need to learn how to code.
We recommend Python for web scraping because of its clean, readable syntax. This programming language offers several key libraries for sending HTTP requests: aiohttp, httpx, and requests. For more information about their specific use cases and strengths, read our blog on httpx vs aiohttp vs requests.
Today’s article will focus on aiohttp—a non-blocking library that offers asynchronous HTTP client and server functionality, enabling you to send multiple requests concurrently. To fully leverage its capabilities without interruptions, you should integrate aiohttp with a proxy server. Doing so helps avoid IP blocks when you repeatedly send data scraping requests to a particular website.
You’ll learn:
- How aiohttp works
- How to install aiohttp on your device
- How to integrate aiohttp proxy servers
- Best practices when using an aiohttp proxy server address
And more.
What Is Aiohttp?
Imagine building a program to gather live data from the internet, say live stock prices from various exchanges. You’ll probably be interacting with multiple APIs at the same time. If you use traditional blocking clients like the Requests library, the program will slow down because each request will wait for a response before moving on to the next one, making the process inefficient.
This is where aiohttp comes in—it’s a Python networking library that allows you to perform HTTP operations without blocking your program’s execution. In this case, aiohttp can send multiple requests to different stock market APIs simultaneously, enabling other tasks to proceed without waiting for responses.
How to Set up Aiohttp with Proxies?
By now, you understand why aiohttp is preferred for sending concurrent data scraping requests to websites. But even with this powerful asynchronous HTTP tool, websites can still flag your IP address if it sends multiple simultaneous requests. Servers may respond by throttling requests, enforcing rate limits, or even blocking your IP altogether.
To avoid this, add proxy connection functionality to your web scraping code. Regular proxy IP addresses may not be sufficient for these tasks. Instead, use rotating residential proxies, which have IP addresses associated with real users. These servers offer proxy rotation, preventing any single address from sending too many requests and triggering server defenses.
So, how does all this look in code? Let’s find out.
Prerequisites for Setting up Aiohttp
Before we get started, make sure you have the following
- Python 3.6 or later installed on your system.
- Rotating proxy servers to use with aiohttp. We recommend rotating residential proxies.
Ready? Let’s dive in.
Installing Aiohttp
Installing the aiohttp library is straightforward and works the same way across all operating systems. To install it, open your command prompt and enter the following command:
pip install aiohttp
To confirm that aiohttp is installed correctly, run the following code:
python -m pip show aiohttp
It should respond with the aiohttp library version that has been installed using the command “pip install aiohttp.”
Writing a Simple Script to Use Aiohttp with a Proxy Server
Up to this point, you should have all the prerequisites to start using aiohttp to collect data from websites and APIs. Now, let’s get to the crux of our discussion: we’ll write a simple Python script that uses aiohttp to extract book titles from the first page of “Books to Scrape,” routing the requests through a proxy server.
Step 1: Import the Necessary Libraries
The first step is to import the aiohttp library into our code. We’ll also use async with session.get to efficiently manage requests. Here’s how it looks in code:
import aiohttp
import asyncio
Step 2: Set up Your Proxy Endpoints
Next, define the address and port number of the proxy server that will reroute the requests. If the proxy requires authentication, be sure to include those details. We’ll cover proxy authentication in more detail later. For now, use the following code:
# Proxy details
proxy = "http://168.158.98.150:44444"
proxy_auth = aiohttp.BasicAuth('14af5e35fdd9a', '006ae513dd')
Step 3: Write the Asynchronous Function to Fetch the Book Titles
Now, let’s write the code to send the book title requests concurrently. Here’s the code, along with an explanation:
# Asynchronous function to fetch book titles from the first page
async def fetch_book_titles(session):
url = "http://books.toscrape.com/catalogue/page-1.html"
async with session.get(url, proxy=proxy, proxy_auth=proxy_auth) as response:
html = await response.text()
# Extract and print raw HTML lines containing <h3>
titles = [line for line in html.splitlines() if "<h3>" in line]
return titles
- async def fetch_book_titles(session): Defines an asynchronous function. The async keyword allows this function to run without blocking the program.
- url: Specifies the target webpage (the first page of “Books to Scrape”) where we want to fetch book titles.
- session.get(): Sends a GET request to the URL using the provided proxy and proxy_auth. The session object is used to maintain and reuse the connection settings, making it more efficient.
- await response.text(): The await keyword allows the program to wait for the response to come back without blocking other parts of the program. Once the response is received, it converts the HTML content to text.
- Extracting titles: The code uses a simple method to search through each line of the HTML content and looks for lines containing <h3>. These lines likely include book titles, so they are added to the titles list.
Step 4: Write the Main Asynchronous Function
Here is the main function that manages the scraping process, along with its explanation:
# Main function to run the scraper
async def main():
async with aiohttp.ClientSession() as session:
titles = await fetch_book_titles(session)
for title in titles:
print(title)
- async def main(): The main function that manages the scraping process. It is marked as async so it can call other asynchronous functions.
- aiohttp.ClientSession(): Creates a session object that manages HTTP requests. The session is passed to the fetch_book_titles function, allowing it to send requests using the proxy settings.
- await fetch_book_titles(session): Calls the fetch_book_titles function to fetch the book titles. The await keyword ensures that the program waits for the function to finish before continuing.
- Print Results: After receiving the list of titles, the program loops through them and prints each one to the console.
Step 5: Run the Asynchronous Code
Use the following code to run the main function:
# Run the main function
asyncio.run(main())
Step 6: Bringing It All Together
Here is the complete Python code:
import aiohttp
import asyncio
# Proxy details
proxy = "http://168.158.98.150:44444"
proxy_auth = aiohttp.BasicAuth('14af5e35fdd9a', '006ae513dd')
# Asynchronous function to fetch book titles from the first page
async def fetch_book_titles(session):
url = "http://books.toscrape.com/catalogue/page-1.html"
async with session.get(url, proxy=proxy, proxy_auth=proxy_auth) as response:
html = await response.text()
# Extract and print raw HTML lines containing <h3>
titles = [line for line in html.splitlines() if "<h3>" in line]
return titles
# Main function to run the scraper
async def main():
async with aiohttp.ClientSession() as session:
titles = await fetch_book_titles(session)
for title in titles:
print(title)
# Run the main function
asyncio.run(main())
If you followed our steps correctly, the script should now display the elements from the first page of “Books to Scrape” that contain the book titles:
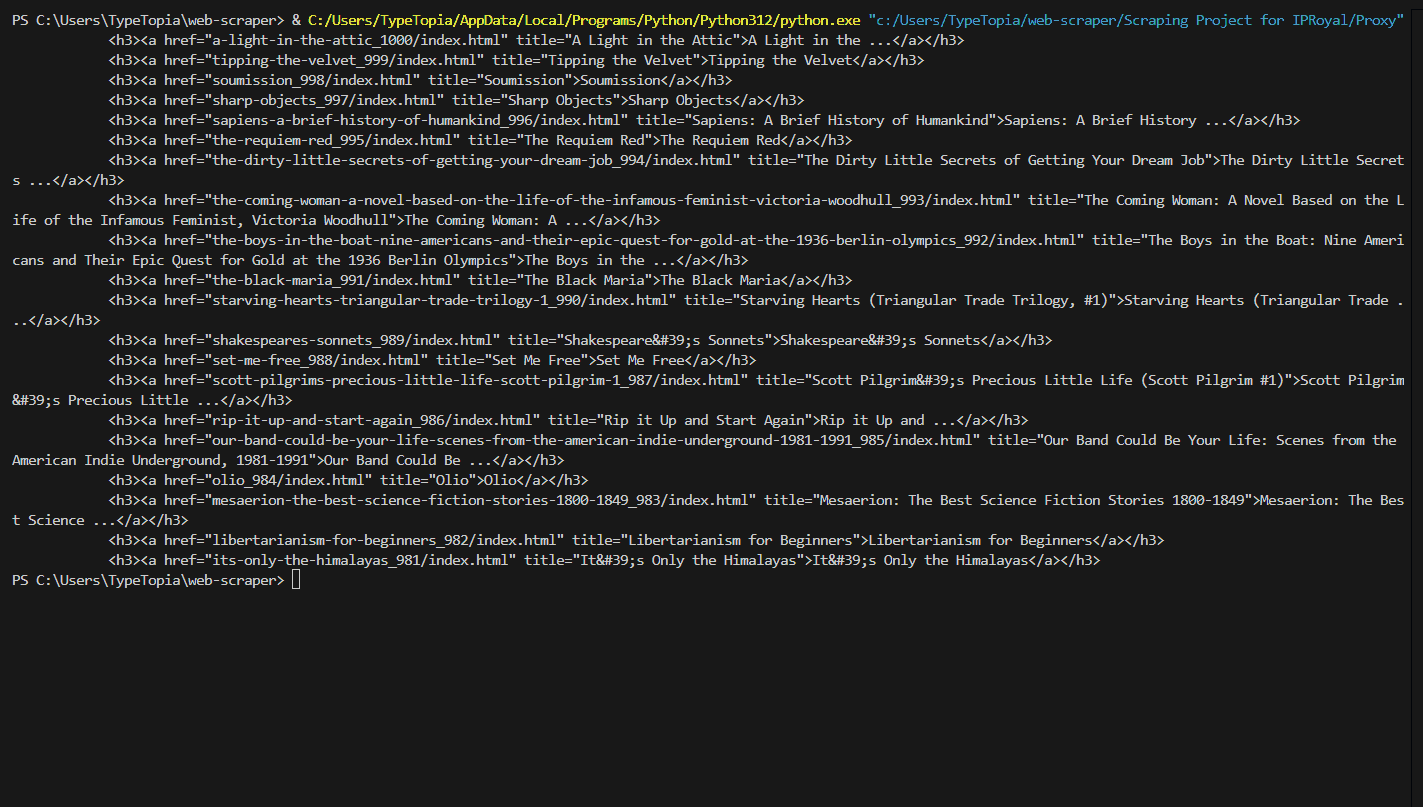
And there you have it—a simple Python script that uses the aiohttp library to extract book titles from the first page of ‘Books to Scrape.’ In the next sections, we’ll fine-tune this code.
Advanced Aiohttp Proxy Configurations
In the following section, we will make some modifications to our code to boost the performance and reliability of the aiohttp scraper.
Handling Multiple Proxies and Rotating Them
First, we’ll adjust the code to facilitate proxy rotation across a pool of five IPs, using a different address for each concurrent request. This will require modifications to several parts of the code. Here’s how to proceed:
Step 1: Import Your Libraries
You’ll now need additional libraries to rotate the proxies. Here they are:
import aiohttp
import asyncio
import random
import re
You’ll notice we have two new libraries:
- random: This library provides us with functions that will help us select the proxy server address randomly.
- re: This library will give us the functions we need to extract the book titles from the HTML elements from the code.
Step 2: Store Your Proxies in a List
We’ll use US datacenter proxies for rotation. You can modify the code to add your own proxies—just ensure they’re stored in a list using the correct format (hostname:port:username:password), as shown below:
# List of proxies
proxies = [
"http://191.96.211.218:12323:14a5c1d1a93a5:f71948b45b",
"http://85.209.221.182:12323:14a5c1d1a93a5:f71948b45b",
"http://64.40.155.202:12323:14a5c1d1a93a5:f71948b45b",
"http://185.244.107.186:12323:14a5c1d1a93a5:f71948b45b",
"http://72.14.139.70:12323:14a5c1d1a93a5:f71948b45b"
]
Step 3: Modify Your Asynchronous Function
Remember the asynchronous function we defined earlier? Now, you’ll need to modify it so the code can randomly select a proxy server IP from the list, extract the authentication details, and use these credentials to send a GET request to ‘Books to Scrape.’We want to scrape the first five pages, using a different IP address each time. As before, we’ll use the await keyword to ensure the process runs concurrently. Here’s the code:
# Asynchronous function to fetch book titles from a specified page
async def fetch_book_titles(session, proxy, page_number):
url = f"http://books.toscrape.com/catalogue/page-{page_number}.html"
ip, port, user, password = proxy.split(":", 3)
proxy_url = f"http://{ip}:{port}"
proxy_auth = aiohttp.BasicAuth(user, password)
print(f"Using proxy: {ip}:{port} for page {page_number}")
try:
async with session.get(url, proxy=proxy_url, proxy_auth=proxy_auth) as response:
html = await response.text()
titles = re.findall(r'title="([^"]+)"', html)
return titles
except aiohttp.ClientProxyConnectionError:
print(f"Failed to connect using proxy: {ip}:{port}")
return None
- async def fetch_book_titles(session): This line defines an asynchronous function named fetch_book_titles. The async keyword allows the function to handle operations without blocking the program.
- url = f"http://books.toscrape.com/catalogue/page-{page_number": The URL now dynamically inserts page_number, which allows the script to target different pages.
- ip, port, user, password = proxy.split(“:”, 3): This line splits the proxy string into four components: the IP address of the proxy server, the port number for the proxy connection, the username, and the password for authentication.
- proxy_url and proxy_auth: These lines set up the proxy URL for authentication. More on that later.
- print(f"Using proxy: {ip}:{port} for page {page_number}"): This libne prints the proxy being used for the current request.
- async with session.get(url, proxy=proxy_url, proxy_auth=proxy_auth) as response: This line sends an asynchronous HTTP GET request to the specified URL using aiohttp. It applies the proxy_url and proxy_auth for routing the request through the proxy. The async with statement ensures that the connection is properly managed and closed after use.
- html = await response.text(): Asynchronously retrieves the HTML content of the response and stores it in the html variable. The await keyword allows the function to pause until the response is fully received without blocking other tasks
- titles = re.findall(r’title=“([^”]+)"', html): This line uses a regular expression (re.findall) to find all occurrences of book titles within the HTML.
- return titles: Returns the list of book titles extracted from the page.
- except aiohttp.ClientProxyConnectionError: This block catches aiohttp.ClientProxyConnectionError, which occurs if the connection to the proxy server fails. If this happens, it prints an error message and returns None to indicate the failure.
Step 4: Modify Your Main Function
You’ll also need to modify the main function to keep track of the used IPs, ensuring each request is sent through a different aiohttp proxy. Since we have a list of five proxies, we’ll send five requests, each using a randomly selected IP from the list. Additionally, update the function to iterate over different page numbers. Here’s the modified code:
async def main():
used_proxies = set()
async with aiohttp.ClientSession() as session:
responses = []
# Scrape the first five pages
for page_number in range(1, 6):
available_proxies = [p for p in proxies if p not in used_proxies]
if not available_proxies:
print("No more proxies left to try.")
break
selected_proxy = random.choice(available_proxies)
used_proxies.add(selected_proxy)
# Fetch book titles using the selected proxy and page number
titles = await fetch_book_titles(session, selected_proxy, page_number)
if titles:
responses.append((selected_proxy.split(":")[0], page_number, titles))
# Print the titles along with the proxy IP and page number used
for ip, page, titles in responses:
print(f"\nProxy IP: {ip} | Page: {page}")
for title in titles:
print(title)
- used_proxies = set(): A set is used to keep track of which proxies have already been used, ensuring that each request comes from a different IP.
- for page_number in range(1, 6): This loop runs for pages 1 through 5, ensuring that the script will try to scrape these five different pages.
- print(f"Using proxy: {proxy_url}"): This line prints the IP of the proxy being used for each request.
- selected_proxy = random.choice(available_proxies): The proxy rotation function. It allows our script to pick a random proxy from our list that has not been used to send the request.
- After gathering five responses, the script prints the IP address used for each request along with the book titles fetched using that IP.
Step 5: Run the Main Function
Use the following code to run the main function as before:
# Run the main function
asyncio.run(main())
Step 6: Bringing It All Together
Here is the complete Python code:
import aiohttp
import asyncio
import random
import re
# List of proxies
proxies = [
"191.96.211.218:12323:14a5c1d1a93a5:f71948b45b",
"85.209.221.182:12323:14a5c1d1a93a5:f71948b45b",
"64.40.155.202:12323:14a5c1d1a93a5:f71948b45b",
"185.244.107.186:12323:14a5c1d1a93a5:f71948b45b",
"72.14.139.70:12323:14a5c1d1a93a5:f71948b45b"
]
# Asynchronous function to fetch book titles from a specified page
async def fetch_book_titles(session, proxy, page_number):
url = f"http://books.toscrape.com/catalogue/page-{page_number}.html"
ip, port, user, password = proxy.split(":", 3)
proxy_url = f"http://{ip}:{port}"
proxy_auth = aiohttp.BasicAuth(user, password)
print(f"Using proxy: {ip}:{port} for page {page_number}")
try:
async with session.get(url, proxy=proxy_url, proxy_auth=proxy_auth) as response:
html = await response.text()
titles = re.findall(r'title="([^"]+)"', html)
return titles
except aiohttp.ClientProxyConnectionError:
print(f"Failed to connect using proxy: {ip}:{port}")
return None
# Main function to run the scraper
async def main():
used_proxies = set()
async with aiohttp.ClientSession() as session:
responses = []
# Scrape the first five pages
for page_number in range(1, 6):
available_proxies = [p for p in proxies if p not in used_proxies]
if not available_proxies:
print("No more proxies left to try.")
break
selected_proxy = random.choice(available_proxies)
used_proxies.add(selected_proxy)
# Fetch book titles using the selected proxy and page number
titles = await fetch_book_titles(session, selected_proxy, page_number)
if titles:
responses.append((selected_proxy.split(":")[0], page_number, titles))
# Print the titles along with the proxy IP and page number used
for ip, page, titles in responses:
print(f"\nProxy IP: {ip} | Page: {page}")
for title in titles:
print(title)
# Run the main function
asyncio.run(main())
This is the output you should get after running the code:
Using proxy: 185.244.107.186:12323 for page 1
Using proxy: 191.96.211.218:12323 for page 2
Using proxy: 85.209.221.182:12323 for page 3
Using proxy: 64.40.155.202:12323 for page 4
Using proxy: 72.14.139.70:12323 for page 5
Proxy IP: 185.244.107.186 | Page: 1
A Light in the Attic
Tipping the Velvet
Soumission
Sharp Objects
Sapiens: A Brief History of Humankind
The Requiem Red
The Dirty Little Secrets of Getting Your Dream Job
The Coming Woman: A Novel Based on the Life of the Infamous Feminist, Victoria Woodhull
The Boys in the Boat: Nine Americans and Their Epic Quest for Gold at the 1936 Berlin Olympics
The Black Maria
Starving Hearts (Triangular Trade Trilogy, #1)
Shakespeare's Sonnets
Set Me Free
Scott Pilgrim's Precious Little Life (Scott Pilgrim #1)
Rip it Up and Start Again
Our Band Could Be Your Life: Scenes from the American Indie Underground, 1981-1991
Olio
Mesaerion: The Best Science Fiction Stories 1800-1849
Libertarianism for Beginners
It's Only the Himalayas
Proxy IP: 191.96.211.218 | Page: 2
In Her Wake
How Music Works
Foolproof Preserving: A Guide to Small Batch Jams, Jellies, Pickles, Condiments, and More: A Foolproof Guide to Making Small Batch Jams, Jellies, Pickles, Condiments, and More
Chase Me (Paris Nights #2)
Black Dust
Birdsong: A Story in Pictures
America's Cradle of Quarterbacks: Western Pennsylvania's Football Factory from Johnny Unitas to Joe Montana
Aladdin and His Wonderful Lamp
Worlds Elsewhere: Journeys Around Shakespeare’s Globe
Wall and Piece
The Four Agreements: A Practical Guide to Personal Freedom
The Five Love Languages: How to Express Heartfelt Commitment to Your Mate
The Elephant Tree
The Bear and the Piano
Sophie's World
Penny Maybe
Maude (1883-1993):She Grew Up with the country
In a Dark, Dark Wood
Behind Closed Doors
You can't bury them all: Poems
Proxy IP: 85.209.221.182 | Page: 3
Slow States of Collapse: Poems
Reasons to Stay Alive
Private Paris (Private #10)
#HigherSelfie: Wake Up Your Life. Free Your Soul. Find Your Tribe.
Without Borders (Wanderlove #1)
When We Collided
We Love You, Charlie Freeman
Untitled Collection: Sabbath Poems 2014
Unseen City: The Majesty of Pigeons, the Discreet Charm of Snails & Other Wonders of the Urban Wilderness
Unicorn Tracks
Unbound: How Eight Technologies Made Us Human, Transformed Society, and Brought Our World to the Brink
Tsubasa: WoRLD CHRoNiCLE 2 (Tsubasa WoRLD CHRoNiCLE #2)
Throwing Rocks at the Google Bus: How Growth Became the Enemy of Prosperity
This One Summer
Thirst
The Torch Is Passed: A Harding Family Story
The Secret of Dreadwillow Carse
The Pioneer Woman Cooks: Dinnertime: Comfort Classics, Freezer Food, 16-Minute Meals, and Other Delicious Ways to Solve Supper!
The Past Never Ends
The Natural History of Us (The Fine Art of Pretending #2)
Proxy IP: 64.40.155.202 | Page: 4
The Nameless City (The Nameless City #1)
The Murder That Never Was (Forensic Instincts #5)
The Most Perfect Thing: Inside (and Outside) a Bird's Egg
The Mindfulness and Acceptance Workbook for Anxiety: A Guide to Breaking Free from Anxiety, Phobias, and Worry Using Acceptance and Commitment Therapy
The Life-Changing Magic of Tidying Up: The Japanese Art of Decluttering and Organizing
The Inefficiency Assassin: Time Management Tactics for Working Smarter, Not Longer
The Gutsy Girl: Escapades for Your Life of Epic Adventure
The Electric Pencil: Drawings from Inside State Hospital No. 3
The Death of Humanity: and the Case for Life
The Bulletproof Diet: Lose up to a Pound a Day, Reclaim Energy and Focus, Upgrade Your Life
The Art Forger
The Age of Genius: The Seventeenth Century and the Birth of the Modern Mind
The Activist's Tao Te Ching: Ancient Advice for a Modern Revolution
Spark Joy: An Illustrated Master Class on the Art of Organizing and Tidying Up
Soul Reader
Security
Saga, Volume 6 (Saga (Collected Editions) #6)
Saga, Volume 5 (Saga (Collected Editions) #5)
Reskilling America: Learning to Labor in the Twenty-First Century
Rat Queens, Vol. 3: Demons (Rat Queens (Collected Editions) #11-15)
Proxy IP: 72.14.139.70 | Page: 5
Princess Jellyfish 2-in-1 Omnibus, Vol. 01 (Princess Jellyfish 2-in-1 Omnibus #1)
Princess Between Worlds (Wide-Awake Princess #5)
Pop Gun War, Volume 1: Gift
Political Suicide: Missteps, Peccadilloes, Bad Calls, Backroom Hijinx, Sordid Pasts, Rotten Breaks, and Just Plain Dumb Mistakes in the Annals of American Politics
Patience
Outcast, Vol. 1: A Darkness Surrounds Him (Outcast #1)
orange: The Complete Collection 1 (orange: The Complete Collection #1)
Online Marketing for Busy Authors: A Step-By-Step Guide
On a Midnight Clear
Obsidian (Lux #1)
My Paris Kitchen: Recipes and Stories
Masks and Shadows
Mama Tried: Traditional Italian Cooking for the Screwed, Crude, Vegan, and Tattooed
Lumberjanes, Vol. 2: Friendship to the Max (Lumberjanes #5-8)
Lumberjanes, Vol. 1: Beware the Kitten Holy (Lumberjanes #1-4)
Lumberjanes Vol. 3: A Terrible Plan (Lumberjanes #9-12)
Layered: Baking, Building, and Styling Spectacular Cakes
Judo: Seven Steps to Black Belt (an Introductory Guide for Beginners)
Join
In the Country We Love: My Family Divided
As you can see, the script used five different IPs to collect book titles from the first five pages of “Books to Scrape.” This strategy can be applied to gather data from other websites while avoiding rate limits, as each request appears to come from a different user.
Proxy Authentication (Username and Password)
Our code already handles proxy authentication effectively. Here is how the proxies are formatted:
IP:PORT:USERNAME:PASSWORD
This format includes the proxy server IP address, port, username, and password used to authenticate the proxy. Our asynchronous function extracts the authentication details from the proxy string:
ip, port, user, password = proxy.split(":", 3)
This command splits the proxy string into four parts:
- ip: The IP address of the proxy
- port: The port number used by the proxy
- user: The username for authentication
- password: The password for authentication
Next, this function creates an authentication object that stores the username and password:
proxy_auth = aiohttp.BasicAuth(user, password)
The code will now use the authentication in the request thanks to this line:
async with session.get(url, proxy=proxy_url, proxy_auth=proxy_auth) as response:
- proxy=proxy_url: Specifies the proxy IP and port.
- proxy_auth=proxy_auth: Passes the authentication object containing the username and password.
Implementing SSL and Secure Connections
When collecting sensitive information, it’s crucial to take extra steps to secure your data, and implementing SSL encryption is one of the most effective strategies. Currently, our code does not explicitly use SSL encryption. Recall this line from the fetch_book_titles function:
http://books.toscrape.com
The URL uses HTTP, not HTTPS, which means no SSL/TLS encryption is applied when connecting to the site. To secure the connection, especially when accessing HTTPS websites, you should add the following lines to the code:
import ssl
ssl_context = ssl.create_default_context()
- import ssl: this line imports Python’s SSL module.
- ssl_context = ssl.create_default_context(): creates a default SSL context object (ssl_context) with pre-configured settings for secure connections. This object handles SSL/TLS encryption, ensuring that your data is encrypted when transmitted over HTTPS.
Best Practices for Using Proxies with Aiohttp
By now, you have a firm grasp of how to integrate proxies with aiohttp, and you can write code blocks to extract data from various websites efficiently. In this section, you’ll learn to fine-tune your scraping strategy to extract data with minimal chances of detection. Keep reading below.
Tips for Maintaining Anonymity
Here are some tips to remain anonymous and avoid detection when web scraping using aiohttp proxies:
- Use reliable proxies
You’re better off working with reliable residential or mobile proxies from reputable providers. These proxies are harder to detect when compared to datacenter IPs.
- Rotate your proxies regularly
Remember, standard proxies won’t work. Opt for a provider that offers rotating residential proxies and distribute your requests as explained in our code blocks.
- Use random request patterns
You also want to avoid patterns that would come off as automated behavior. To do that, implement random delays between requests as shown in the code below:
import random
import asyncio
async def fetch(session, url):
proxy = random.choice(proxies)
async with session.get(url, proxy=proxy) as response:
await asyncio.sleep(random.uniform(1, 5)) # Random delay between 1 to 5 seconds
return await response.text()
This way, your code will wait for anywhere between one to five seconds before sending the next request.
- Enable SSL for secure connections and prevent data interception
When collecting sensitive information, you should enable SSL by defining an SSL context, as we described above. Remember not to disable SSL, as this can compromise the security of your collected information.
- Use CAPTCHA-solving services
If you encounter CAPTCHAs, consider using services like Capsolver or Death by CAPTCHA to bypass them. These services work by solving the CAPTCHA image or challenge you send them and returning a token that lets you pass the test. For more information on these tools, see our article on the 6 best CAPTCHA solving tools.
Common Issues and Troubleshooting
It’s common to encounter issues that can impact the performance of the data collection process or lead to failed requests. Here are some typical errors and how to resolve them:
- aiohttp.ClientProxyConnectionError
This error means Python cannot establish a connection to the proxy. It implies the server is offline, you used an incorrect proxy URL, or some underlying issues between your client and the proxy. To resolve it, start by double-checking the proxy URL and ensuring the format is correct. Use cURL to test the proxy’s availability as well.
- aiohttp.ClientHttpProxyError
This means that the connection to the proxy was established, but it returned an error response, such as a 403 Forbidden or 407 Authentication Required. Most of the time, it’s because you either used incorrect authentication details or the proxy does not allow access to the requested URL. So check the authentication details or contact the provider to confirm whether the IPs restrict access to specific websites.
- aiohttp.ServerTimeoutError
It means the request to the proxy or destination server timed out either because of an overloaded server or your network is slow. To fix it, extend the connection timeout to give the proxy more time to respond using the code below:
timeout = aiohttp.ClientTimeout(total=30)
async with aiohttp.ClientSession(timeout=timeout) as session:
...
- aiohttp.ClientSSLError
This error simply alludes to verification issues with the target server’s SSL certificate. To fix it, create a custom SSL certificate as we described earlier.
Conclusion
It is our hope that you now understand how to integrate proxies with aiohttp and extract data safely from the internet. Aiohttp’s biggest strength is the fact that it is non-blocking, allowing you to fetch data concurrently. There are many other Python libraries you can use, each tuned to a specific task. For more information, read our blog on the best Python web scraping libraries in 2024.


