How to Bypass Cloudflare Protection? Tutorial for 2026
Tutorials

Vilius Dumcius
Cloudflare is a major US-based internet technologies company focused on website security and content delivery optimization. W3Techs, a technology statistics website, states that over 19% of all websites use Cloudflare reverse proxy services to protect web pages from external threats, such as malicious bots, unauthorized access, and hacking.
Website owners greatly benefit from Cloudflare protection, but it also hinders unrestricted information access requests, which are not necessarily harmful. For example, Cloudflare can mark legitimate web scraping operations as malicious bots. Web scraping is widely used for price monitoring, financial data collection, and machine learning dataset enrichment, so Cloudflare protection can sometimes hinder other business development.
In this case, bypassing Cloudflare protection is essential for getting the required data. It’s a challenging task, as Cloudflare regularly updates its anti-bot detection algorithms, which are now powered by AI. In this article, we will explain the ins and outs of this powerful cybersecurity system and how to bypass Cloudflare protection responsibly to enhance web scraping.
Prefer a visual explanation? Watch this video:
What Is Cloudflare?
Cloudflare officially launched in 2009 as a continuation, expanse, and improvement of Project Honey Pot. At that time, Project Honey Pot tracked email harvesting methods to combat spam, including various email fraud scams. However, the worsening cybersecurity landscape demanded a more hands-on approach to stopping malicious threats instead of just tracking them.
Cloudflare took notice and started developing a reverse proxy network, which proved to be just as efficient a data routing optimization tool later on. Below is a detailed description of the three major Cloudflare services: reverse proxies, content delivery networks (CDNs), and a web application firewall (WAF).
Reverse Proxy DDoS Protection
At the time of Cloudflare’s launch, Distributed Denial of Service (DDoS) was a popular cyberattack to target web pages with fake traffic, typically using a bot network. Bots overloaded servers with fraudulent requests, slowing them or taking them down entirely. This cyberattack is still widely deployed today. In the global DDoS trends for 2024 second-quarter report, Cloudflare outlines a 20% DDoS increase compared to the same period in 2023.
To combat this cybercrime, Cloudflare established a reverse proxy network. Reverse proxies stand in front of origin servers that host websites. They accept incoming traffic before routing it to the target destination. Reverse proxies can also perform data caching, traffic inspection, and encryption, saving backend server resources to improve website performance.
This way, the fake DDoS traffic hits the reverse proxy first, which then analyzes the traffic for malicious elements and, if something doesn’t add up, denies access to the origin server. We will explain the exact bot detection methods later on.
As valuable as reverse proxies are, they also tend not to differentiate legitimate traffic from scraping bots. For example, Cloudflare proxies allow Google crawler bots but may deny access to proprietary web scraping bots used for market research. That’s why bypassing Cloudflare blocks is sometimes mandatory in specific business branches.
Content Delivery Network
Cybersecurity was not the only issue in the earlier stages of the World Wide Web. Slow data transfers were just as disruptive. On average, it took more than three seconds to load a standard 50-kilobyte image using dial-up networks in the early 2000s, and that also prevented people from using a phone line at the same time.
Cloudflare noticed the rapidly increasing demand for a fast internet connection and speedy data exchange. They took an innovative approach to optimizing online data transfers using Content Delivery Networks. Essentially, a CDN is a network of strategically placed proxy servers that serve multiple purposes.
Firstly, a CDN prevents server overload caused by a spike of organic website visitors or malicious DDoS attacks discussed in a previous chapter. Instead of allowing all traffic to the origin server, it is distributed across multiple reverse proxies. A DDoS bot network targeting protected by Cloudflare website gets blocked by a reverse proxy cybersecurity system.
This way, each server handles fewer visitors to maintain the best possible performance. If the network is experiencing a DDoS attack, it can only take down reverse proxies while leaving the origin server and website operational. Take a look at the picture below for Cloudflare CDN routing optimization, which is called Anycast Network.
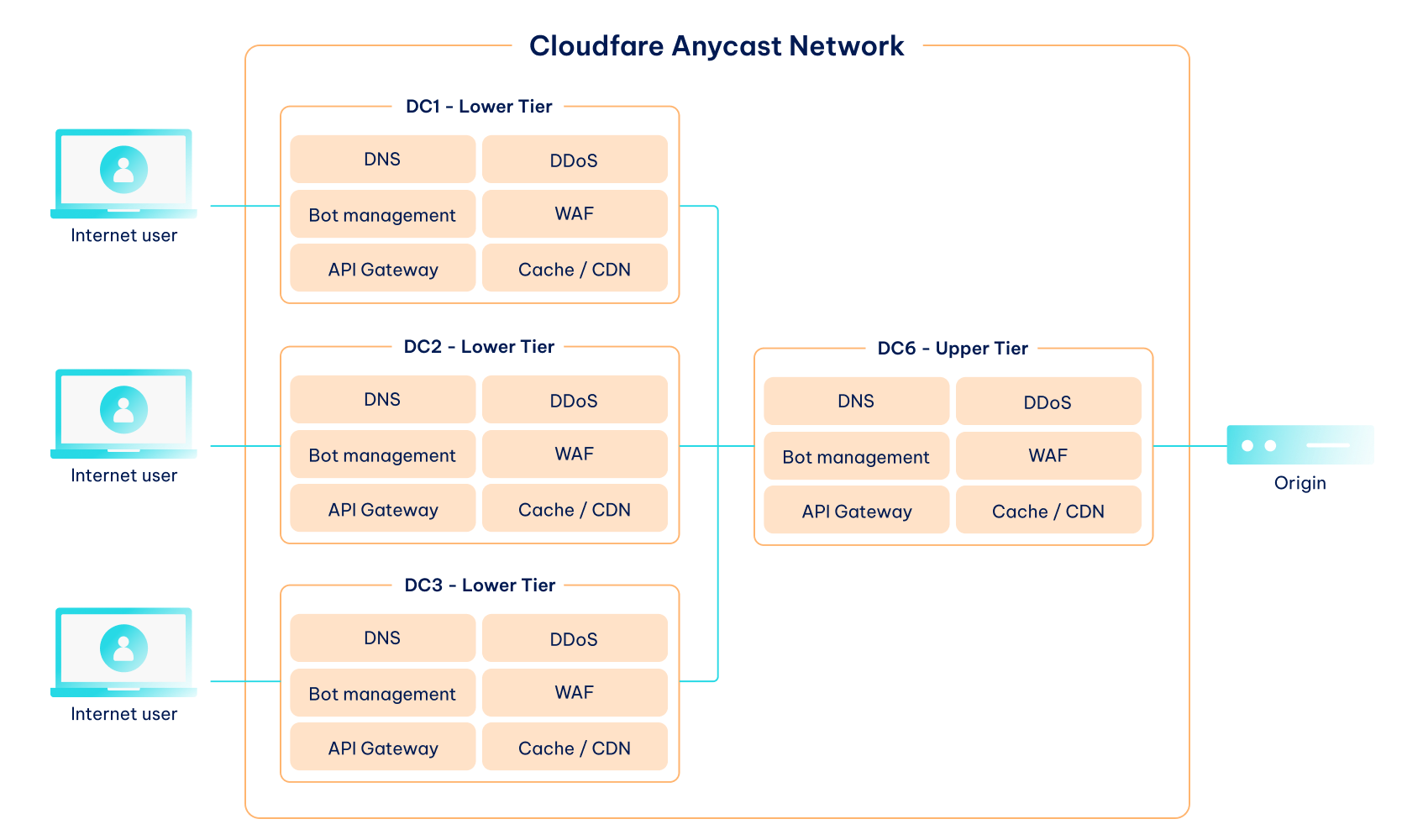
A CDN also optimizes network latency, which is the time it takes for data to reach its destination from the client (typically a user’s web browser). Without a CDN, a person browsing a German website from the US would experience a massive lag because the data would travel halfway across the globe.
Instead, Cloudflare smartly places its CDN proxy servers in over 335 locations worldwide. These servers store website assets closer to the client so that the data travels a shorter distance, improving session latency. Here’s a concise list of major CDN benefits.
Data Routing Optimization
Proxy servers placed in proximity to the original user reduce the data travel path and connection latency. Minimal latency is especially important for online multiplayer games, but it also greatly affects website loading speed, which is mandatory to maintain steady traffic.
Content Caching
Directly related to data routing optimization, content caching ensures that users can get specific data without communicating with the origin server. Such content typically includes images (photos, banners, etc.), downloadable assets (documents, PDFs), fonts, JavaScript elements, style sheets, and similar website elements. Less frequently, they can also store complete HTML files and video content, but keep in mind that reverse proxies are not designed for large file storage.
Bandwidth & Server Load Optimization
CDN networks prevent too many users from contacting the origin server at the same time to reduce its bandwidth consumption. Its resources are reserved for functions like dynamic content updates, handling user interactions, and non-cacheable content like highly personalized website elements display.
Simultaneously, CDNs redistribute incoming traffic across multiple edge servers that have the purpose of storing and offloading frequently requested data. Although edge servers and reverse proxies have numerous similarities, they should not be used interchangeably. While reverse proxies are typically placed in front of the origin servers, edge servers function on the edges of the network that are in proximity to clients.
Cybersecurity
CDN proxies typically have some integrated cybersecurity features. As we’ve discussed previously, they are essential for DDoS protection and the prevention of other fraudulent bot activities. CDNs also often handle encryption and decryption, which demands significant server resources. Lastly, due to placement in front of origin servers, they are excellent for hosting web application firewalls (WAFs) to expand cybersecurity capabilities further.
Firewalls are also essential for modern internet security. Alongside CDN services, Cloudflare also offers a strong web application firewall, which can also interfere with web scraping, so let’s overview it separately.
Cloudflare Web Application Firewall
A firewall is a software application that sits between trusted and untrusted networks to safeguard communication between the two. It protects origin servers from possible external threats, like unauthorized access or discussed DDoS attempts, as well as more sophisticated cyberattacks like cross-site scripting (XSS) and SQL injections.
There are several types of firewalls, like network or stateful inspection firewalls. In this article, we analyze Cloudflare’s web application firewall as it has the most significant impact on web scraping.
A WAF is a type of reverse proxy configured to perform cybersecurity tasks. It uses a set of defined rules, which are called policies. WAFs are placed in front of web applications and protect them with specific policies. For example, rate limiting is a rule that defines how many requests are allowed from a single IP address to fight DDoS.
It is easy to understand Cloudflare WAF by outlining its three essential functions.
1. Whenever a user attempts to access a web application protected by Cloudflare firewall, it intercepts the request (acting as a reverse proxy) and routes it through the server that hosts the firewall first.
2. The firewall analyzes the request according to its policies. It inspects HTTP headers, IP addresses, and target URLs, performs TLS fingerprinting and canvas fingerprinting, and assesses the likelihood of bot requests.
3. Then, it performs actions according to outlined policies, which can involve issuing CAPTCHAs, rate limiting, blocking or allowing the request through, and logging its information for further analysis.
Although the purpose of these steps is to protect the origin web server from malicious threats, you may already see how it interferes with web scraping. Because scraper bots often issue more simultaneous requests than human visitors, the firewall flags them as suspicious and may implement restrictions. Now, let’s overview the exact Cloudflare bot detection methods.
How Does Cloudflare Detect Web Scrapers?
Web scrapers inevitably employ bots that go through a long list of URLs on a website. Most active bot protection techniques do not attempt to differentiate between benign and malicious bots due to how complex and difficult it might be to do so. Cloudflare’s anti-bot techniques are no different, and they’ll often ban web scrapers.
Anti-bot protection is an extremely complicated and nuanced topic. There are numerous methods to detect bots . Here are some of the most common ones.
Number of Requests per Minute
Regular users will send significantly fewer requests than any bot as they will have to take time to read and process the content on the page. Bots have no such limitations.
User Behavior
Most internet users have a somewhat predictable pattern of navigation. They may visit the homepage, go to one of the many pages from there and continually browse until they click out of the page. Bots will be much more methodical in their approach.
Honeypots
Some websites will implement hidden URLs that are only visible through HTML code. Bots will try to visit these URLs, which will get them banned. Working around honeypots is important for bypassing Cloudflare anti-bot protection. Remember that this company branched from Project Honey Pot, which uses embedded “traps” on protected web pages. In turn, Cloudflare uses data collected by Project Honey Pot to improve its own bot detection algorithms.
User Agent and IP Address Evaluation
Both the Cloudflare and origin server will often evaluate the request metadata they receive to assess whether it could be coming from a bot. Some basic bots will actually send user agents that tell web servers that they are bots. Additionally, some IP addresses may be flagged or banned due to previous botting actions.
Listed above are only some of the anti-bot protection techniques. Cloudflare’s anti-bot protection likely uses a combination of those above and possibly some more advanced implementations such as machine learning.
Some of the techniques used by Cloudflare’s anti-bot protection are relatively clear-cut. It is highly likely that they measure the number of requests per minute (as they also protect from DDoS attacks), evaluate user agents and IP addresses, and, potentially, a few other metrics.
Detecting the number of requests is especially vital to Cloudflare’s anti-bot protection, as most web scrapers run a large number of them per second or minute. As such, it’s extremely easy for web scrapers to trip up the bot protection algorithm.
If you run into issues with a Cloudflare-protected site, you’ll likely receive one of the following errors.
Cloudflare Error 1020: Access Denied
While this error is not very descriptive, it’s highly likely that the Cloudflare-protected site considers you a bot and prevents you from accessing data. You’ll need to apply one of the many methods outlined below.
Cloudflare Error 1010: Access Denied
Another frequent error, which is issued if your headless browsers leak fingerprint information. You’ll need to switch up the user agent and overall fingerprint.
Cloudflare Error 1015: You Are Being Rate Limited
Cloudflare Error 1015 means your web scraping tool has been blocked for sending too many requests. You’ll need to either reduce the amount of requests or separate them through an IP address pool.
Cloudflare Error 1009: Your Country Is Blocked
Another simple Cloudflare challenge that has nothing to do with bots. Your IP address is simply blocked by Cloudflare as the server intends to only serve people from a specific location. Switching your proxy IP address usually resolves the issue. Simply choose an IP in a country whose visitors are allowed, and you will be able to access the content blocked by Cloudflare site protection.
Advanced Cloudflare Bot Detection Techniques
These are the simplest and most common Cloudflare bot detection methods, but it doesn’t stop there. More advanced detection techniques include behavioral tracking, TLS fingerprinting, Cloudflare JavaScript challenge, and device fingerprinting. Bypassing Cloudflare is much easier if you understand how these work.
Behavioral Tracking
Behavioral tracking, officially called User and Entity Behavior Analytics (UEBA) is a cybersecurity method used to separate bot activity from a genuine human user. Machine learning and AI significantly improved UEBA as it can now collect, analyze, and make accurate assessments, differentiating humans from bots.
What makes Cloudflare so efficient (and bypassing Cloudflare challenging) is that it can use machine learning to analyze data from the millions of websites it protects. That gives Cloudflare a unique capability to craft sophisticated human online behavior models.
For this purpose, Cloudflare monitors user navigation patterns, such as the time spent browsing a specific page, clicking interactions, filling out forms, etc. It follows mouse movements, which is significantly different when using bot simulations.
Behavioral tracking is a real-time process during which Cloudflare compares the website’s visitors to its models. Any deviation from expected behavior is marked and contributes to the bot score, which Cloudflare assigns. If there are too many deviations, the visitor is identified as a bot, which may prompt a CAPTCHA or a Cloudflare error 1020.
Keep in mind that UEBA is typically combined with other protection methods, like device fingerprinting and IP analysis. Even if you configure a headless browser to simulate a real person, you may fail to bypass Cloudflare CDN if it leaks user-agent data.
TLS Fingerprinting
Transport Layer Security fingerprinting is a sophisticated method that utilizes an essential step in client-server communication. Similarly to behavioral tracking, it also compares client data with models in Cloudflare’s database. However, instead of searching for human-like patterns, it focuses on the communication initiated by the client’s browser.
It is necessary to explain what a TLS ‘handshake’ is to understand TLS fingerprinting. In computer networking, a TLS ‘handshake’ establishes a client (typically a web browser) and server communication by sending a ‘Client Hello’ message.
This message includes the TLS version, cipher suites (cryptographic algorithms that define data encryption and secure connection protocols), and various extensions supported by the client. At this point, Cloudflare’s reverse proxy intercepts the ‘handshake’ and fingerprints it. It creates the JA3, or more recent and elaborate, JA4 fingerprint, which stores client-specific information.
Cloudflare also fingerprints ‘handshakes’ initiated by bots or malware and stores them in its databases. It then compares the TLS fingerprint of a client to the ones it has stored to notice any similarities to bots or malware. Once again, ‘handshakes’ that demonstrate a bot-like behavior are flagged as suspicious, and the connection may be terminated.
JavaScript Challenges
Cloudflare JavaScript Challenge Script is another method Cloudflare uses to identify bots. This time, it injects JavaScript code into the client’s browser, which performs several checks and gathers information when executed. You have likely seen this challenge, as illustrated in the picture below.
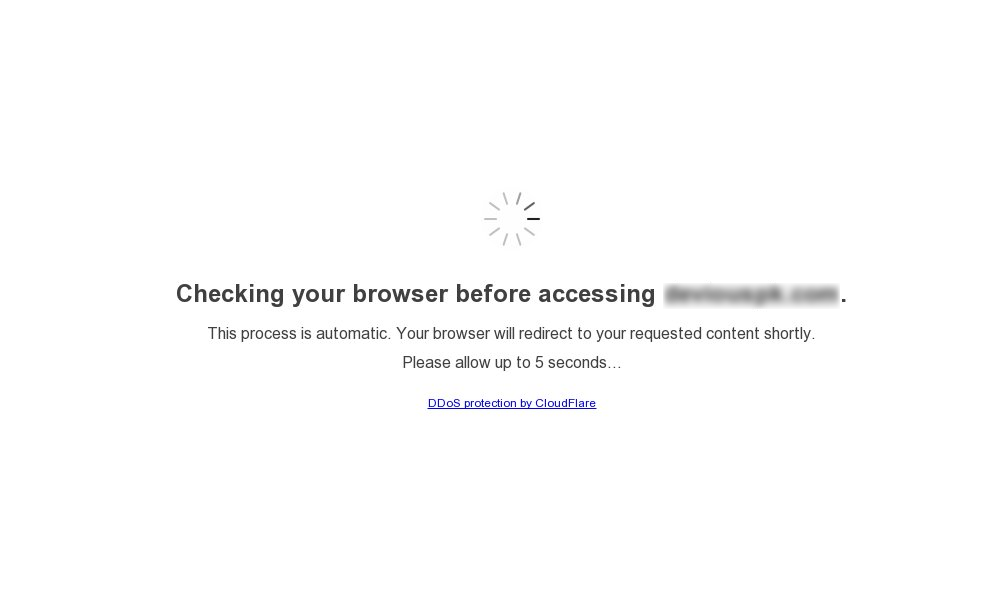
The trick is that automated browsers and headless browsers often execute JavaScript code differently, or have limited capabilities to do so. This challenge examines the client’s response and checks the following elements: user-agent, JavaScript execution timeframe, canvas rendering, timezone and language, cookies like cf_clearance, and the navigator.webdriver JavaScript property (indication of frameworks like Puppeteer and Selenium), and more.
As you can see, the majority of Cloudflare tests compare the client’s browser actions against its database of known bot behavior. That’s why bypassing Cloudflare to enhance web scraping is a challenging task that requires modifying multiple settings from user-agents to proxies to JavaScript properties.
Device Fingerprinting
Cloudflare uses device fingerprinting to identify malicious actors, including bots, and prevent fraud, like account takeovers. It also protects from account abuse, like using multiple accounts on social networks that do not allow it.
Device fingerprinting collects a lot of user data, so, in the wrong hands, it can violate online privacy rights. This method checks the version and type of the browser, its user-agent, installed extensions, screen resolution, color settings, etc.
It also checks operating system type and version and limited hardware information (CPU and GPU details, fonts, RAM amount, device model, and even battery status.) Like most Cloudflare protection methods, it often works alongside other cybersecurity processes, like TLS and canvas fingerprinting.
Regarding web scraping, it causes issues as Cloudflare can identify scraper bots running on the same machine. What’s more, device fingerprinting can bypass obfuscation methods like proxy servers or user-agent spoofing. In this case, take a look at virtual machines and anti-detect browsers developed to overcome such challenges.
How to Bypass Cloudflare Bot Protection
While we can’t know for certain what methods are used to detect web scrapers, you can bypass Cloudflare bot protection with a few tried and tested techniques. Using several of them in conjunction or one after another may bring even better results, allowing you to bypass Cloudflare more frequently.
1. Send Requests Directly to the Origin IP Address
Sometimes, the Cloudflare bypass method is as simple as sending requests to IP addresses instead of the website domain. Cloudflare relies on users attempting to access the website through regular routes and putting a server in between.
If you know the IP address of the origin server, you can always try to connect to it directly. In some cases, that’ll completely circumvent the Cloudflare challenge. It often won’t be as easy, however, as you have to first find the IP address.
Using lookup services or various commands available through the terminal might not provide you with the results. You’ll have to snoop around and look in various databases (such as Censys or Shodan) or use dedicated software (such as CloudFlair ). If you find the IP address of the origin server, you can send requests to it directly, completely bypassing Cloudflare.
This method, however, relies on the fact that someone has left the IP address of the origin server publicly available. Generally, that could be considered a mistake, so while it’s the most effective Cloudflare bypass method, it’s also one that you’ll rarely be able to utilize.
2. Scrape Google’s Cache
For quite some time, scraping Google cache was straightforward. Google maintained its webcache domain , which stored website caches. You could use it to access and scrape the cached version using the following link:
https://webcache.googleusercontent.com/search?q=cache:[YOUR_WEBSITE_URL]
Alternatively, you could search for specific web pages on Google's search engine and click the three vertical dots next to them. Up until early 2024, Google offered to access cached website versions in the options menu. Both options are no longer viable, as Google has discontinued straightforward access to website caches.
It's worth noting that scraping Google's cache also has some significant drawbacks. Firstly, cached web pages do not include dynamic elements, limiting useful information. Second, website cache updates are not frequent, so web scraping outdated data is a real risk.
Having this in mind, you can still access website caches through services like https://web.archive.org/ , the so-called Wayback Machine. Keep in mind that you also risk grabbing outdated data there, so make sure you know your exact requirements before proceeding.
3. Use Headless Browsers With Plugins
Most headless browsers were intended to test website functionality and automate actions. As such, they have several weaknesses that make bypassing Cloudflare anti-bot protection a little difficult.
There are, however, versions of headless browsers that attempt to fix all the leaks that trip up Cloudflare's active bot protection techniques. Such headless browsers usually have a stealth plugin (such as Puppeteer or Playwright) or have optimized webdrivers (such as Selenium).
While it can be extremely effective in bypassing Cloudflare, this method runs into the problem of a cat-and-mouse game. As soon as someone discovers a way to bypass Cloudflare using these plugins, the developers of the Cloudflare network are also made aware and attempt to create a patch for it. However, a headless browser customized to bypass online restrictions is still one of the most powerful Cloudflare anti-scraping bypass tools.
As such, these tools usually bypass Cloudflare effectively for a short while and completely stop working afterward. Cloudflare bypass developers then attempt to find a new way while the company creates a patch for any method that's found.
So, it's a good method to have in your toolbox and keep an eye on any updates to Cloudflare bypass methods through headless browsers, but it can't be the only way, as you'll sometimes be stuck without a way to access data.
4. Use Proxies and IP Address Rotation
One of the ways Cloudflare detects bots is by checking how many requests an IP address attempts to send to the server. If the origin server Cloudflare protection is set up properly, it'll quickly block any web scrapers that send too many requests.
IP address rotation is a simple fix to that issue, as it'll completely reset the number of requests sent. Additionally, while there are no dedicated Cloudflare bypass proxy providers, most residential proxies work fairly well at evading active bot detection techniques.
Global Pool, Precise Targeting, Zero Contracts
Premium Residential Proxies
With a large enough IP address pool, you can keep switching them as soon as your web scrapers get detected. That'll usually resolve most Cloudflare active bot detection methods.
One of the exceptions to the above Cloudflare challenge script is user-agent detection and JavaScript leaks from headless browsers. These need to be optimized separately, as changing your IP address will do nothing if your user-agent is detected as coming from a bot.
The CloudFlare JavaScript challenge is a little more complicated as headless browsers leak their fingerprints through JS. You can either use a headful browser or a headless browser with a stealth plugin, as outlined above.
5. Use a CAPTCHA Solver
Finally, there's always the Cloudflare CAPTCHA bypass, which is useful when all other methods fail while no access denied error is produced. Cloudflare will often first test the waters by throwing out a CAPTCHA to an offending IP address without resorting to an instant ban. Web scrapers, in fact, will often run into such tests first. Here's how to solve Cloudflare CAPTCHA using automated software solutions instead of manual input.
With residential proxies, the Cloudflare CAPTCHA bypass method can be somewhat simple, such as changing your IP address, which should resolve the issue. Sometimes, however, you'll need a second way to bypass Cloudflare CAPTCHA.
In those cases, there are plenty of ways to circumvent CAPTCHA tests , one of which is using a dedicated service. There are many companies out there that will automatically help you bypass the CAPTCHA Cloudflare challenge for a small fee.
You simply add their API to your web scrapers, and whenever a CAPTCHA test is delivered, it will be sent to their endpoint, which will then be solved, allowing you to continue scraping. These solutions, however, can definitely build up costs for your projects.
Bypassing Cloudflare to scrape web pages typically involves a combination of the methods outlined above. For example, if you use a headless browser, you will often require proxies to ensure that separate browser profiles use different IP addresses. Having a scraper bot that has an in-built CAPTCHA solver also increases web scraping efficiency.
However, you can also try to grab information from the origin server, bypassing Cloudflare whatsoever, as outlined in the very first method. For this, you will need its IP address. Because most websites protect their origin server IPs, finding them is challenging. Here are two methods that can help you out.
How to Find Origin IP via Historical DNS Records
Before CDNs, web pages used the original IP address for communication. These IPs also regularly changed whenever websites switched hosting providers or made changes to the origin servers. However, the DNS records included the origin server IP addresses to maintain a communication channel with a specific website.
DNS stands for Domain Name System. You can understand it as the internet phone book. Whenever you type a specific website into your search bar, like www.iproyal.com , your browser must know its IP address because that's how clients communicate with servers in computer networks. For this, your browser communicates with a DNS server, which says that one of our IPv4 addresses is 172.67.69.28.
So, web pages store their IP addresses in DNS records. Although the majority of websites that use Cloudflare point to Cloudflare server IPs in the DNS records, there are historical DNS lookup services that store origin server IP addresses.
Even though bypassing Cloudflare using this method is often a hit-and-miss , it's worth trying, as grabbing data from the origin server lets you avoid using sophisticated software, like a headless browser. There are several historical DNS service providers, like SecurityTrails and CompleteDNS.
Keep in mind that these services are also paid, so calculate whether bypassing Cloudflare is more affordable this way than deploying a web scraper.
How to Extract Origin IP From Email Headers
You can also obtain the origin server IPs from email headers, although the chances are slim. Because most internet users utilize some kind of email client, like Gmail, you will likely get a Gmail server IP address. On the other hand, some emails are sent via proprietary services and could include the origin server IP address.
If you decide you want to try out this method, here's how to access Gmail email headers to find server IP addresses.
1. Select the email you want to inspect and open it.
2. Click on the three vertical dots right next to it.
3. Click on the 'Show Original' option.
4. Your browser will now launch a new window with the email header.
5. Search for the 'Received' keyword - there should be multiple of them.
6. Scroll down to the last 'Received' section. An IPv4 or IPv6 address should be right next to it, and it marks the first server that received this email.
In this case, it will be Gmail's server through which the email continues its journey to your inbox. However, if the email was sent via a proprietary email client, like a corporate email, it could point to the origin server.
Keep in mind that inspecting email headers requires good computer networking and data routing knowledge, so scraping web pages with a headless browser could be an easier way to go.
Final Thoughts
By now, you should have a good theoretical knowledge of how to unblock Cloudflare-protected websites and target them with a scraping bot. Bypassing Cloudflare is challenging, but once you master dedicated software, like a headless browser, you can target multiple websites simultaneously to save time, money, and human resources.
Remember, the answer to the question "How to skip Cloudflare verification?" involves using several methods most of the time. Alongside proxies to rotate IPs, you must also rotate user-agents so that each HTTP request looks like coming from a different user.
Lastly, we recommend reviewing ethical data collection guidelines . Bypassing Cloudflare for market research or price comparison is a tech-savvy way to enhance business operations. However, scraping personally identifiable data or going against website data-sharing rules poses legal risks, which you should avoid.


