How to Build a Golang Web Scraper - The Ultimate Guide
Tutorials

Justas Vitaitis
A Golang web scraper is the perfect combination of simple syntax and high performance.
Golang, or Go, is a programming language known for its simple syntax and excellent performance. And the truth is it can outperform well-established “go-to” web-scraping languages such as Python, JavaScript (node), and Ruby.
In this guide, we’ll explore how you can create a Golang web scraper in simple steps without getting blocked. To do it, we use well-known tools, such as Golang Playwright and IPRoyal’s residential proxies service.
Let’s get started!
What Is a Web Scraper Used For?
You can use a web scraper to gather data at scale. You can monitor prices, gather news, set up job alerts, check stock levels, monitor customer reviews, and more.
In general, web scrapers allow you to automate any real-human action, so you can do anything you would manually do. You can get data, process it, or even interact with a site, click on links, fill in forms, and take screenshots.
What Is Web Scraping in Golang?
Web scraping in Golang is the action of automatically extracting data from websites that don’t make it readily available. Therefore, you can use Golang to read data from sites like any person would do, but at scale.
Is Golang Good for Web Scraping?
Golang is a great option for web scraping. Some tests show that Golang can outperform Python and Ruby. And it’s very easy to get started with Golang in general.
In the end, there are many great options in terms of programming languages for web scraping. It’s mostly a matter of picking the best tool given what you know and what you are comfortable with.
How Do You Make a Web Scraper in Golang?
You can make a web scraper in Golang with libraries that allow you to connect to websites, download their code, and extract data from pages.
You can use a library such as Playwright to connect to sites using a headless browser. These are regular browsers controlled by code, so you can load pages just like a regular visitor would, but you can extract data from them using code commands.
What Is Gocolly?
Gocolly is a popular web scraping framework for Golang. With it, you can create crawlers, spiders, and scrapers. It’s fast and easy to use, but it can only be used for static content.
Therefore, if your target site has dynamic content, you’d need to manually inspect the JS requests and scrape contents from them.
What Is Golang Playwright?
Golang Playwright is a browser automation library for Go. It is a community-supported project based on Playwright, a cross-language automation library created by Microsoft.
It allows you to programmatically interact with any browser you want using code. Therefore, you can extract data from any site that a real visitor can see.
It’s a flexible approach that allows you to scrape contents without getting blocked. It is harder to detect web scraping with a headless browser since it is essentially a real user visit.
How Do I Avoid Being Blocked From Web Scraping?
You can avoid being blocked from web scraping by using a headless browser and a residential proxy.
Although web scraping is legal, website owners try to block it. Therefore, they try to detect any requests that don’t look like real visitors.
Usually, they check if the connection request looks like a real human request, with metadata that browsers usually include and that render pages in a way that real browsers do. Then, they check if these users are visiting many pages or if they visit pages at the same time over many days.
You can use a headless browser, such as Golang Playwright, to create your Golang web scraper and don’t raise any suspicions. The requests really come from a real browser. Therefore, website owners can’t really tell that this is an automated request. This is different from other scraping libraries that might not include metadata or might not render pages properly.
In addition, you can use IPRoyal’s residential proxies service. With it you can load pages using a different IP address each time. Therefore, website owners can’t really tell if you are loading one page or a thousand. And they don’t really know if you are loading them in a fixed schedule since each request comes from a different address.
Golang Web Scraper - Step by Step Guide
Let’s explore how you can create your Golang web scraper in detail.
Here are the main steps you need to take:
- Install Go and an IDE
- Create a new go.mod file
- Install Golang Playwright
- Create your main.go file
- Take a screenshot
- How to use a playwright proxy
- Extract data
- Click on buttons
- Fill in forms
How Do I Install Golang?
You can install Golang on MacOS using Homebrew:
brew install go
And you can install Golang on Windows using Chocolatey:
choco install golang
If you want to install Go on Linux or another OS, you can use their install package.
In general, after you install Go, you can run this command to make sure everything is working:
go version
Then, if you want to run one of your files, you can run this command:
go run [filename]
Replace [filename] with your file. For example, go run main.go.
Then, you need to install an IDE to write code. You can use any IDE you want. In this tutorial, we are using VS Code. Go to the Extensions section and install the Go extension:

Let’s start building!
Create a New go.mod File
This step might seem confusing if you are just getting started with Golang. But in short, in Go you create modules to build code. And in order to start a module you need a go.mod file.
This file contains the module description, the Go version, and the packages required.
Navigate to the Go folder (usually your user’s folder /go) and create a new folder there named scraper. Then, navigate to this folder in your terminal and run this command:
go mod init iproyal.com/golang-web-scraper
This command creates a new /scraper/go.mod file. Feel free to replace the module name with anything you want (instead of iproyal.com/golang-web-scraper).
How to Install Go Playwright
Now you need to install Playwright and some dependencies. You can do it with this command:
go get github.com/playwright-community/playwright-go
Then run this command as well:
go run github.com/playwright-community/playwright-go/cmd/playwright install --with-deps
If you are planning on using other libraries, feel free to do so now.
Take Screenshots of a Website
Now it’s time to start playing with your Golang web scraper. Create a new main.go file in your scraper folder.
Then add this code in it:
package main
import (
"log"
"github.com/playwright-community/playwright-go"
)
func main() {
pw, err := playwright.Run()
if err != nil {
log.Fatalf("could not launch playwright: %v", err)
}
browser, err := pw.Chromium.Launch()
if err != nil {
log.Fatalf("could not launch Chromium: %v", err)
}
page, err := browser.NewPage()
if err != nil {
log.Fatalf("could not create page: %v", err)
}
if _, err = page.Goto("https://ipv4.icanhazip.com/", playwright.PageGotoOptions{
WaitUntil: playwright.WaitUntilStateNetworkidle,
}); err != nil {
log.Fatalf("could not goto: %v", err)
}
if _, err = page.Screenshot(playwright.PageScreenshotOptions{
Path: playwright.String("screenshot.png"),
}); err != nil {
log.Fatalf("could not create screenshot: %v", err)
}
if err = browser.Close(); err != nil {
log.Fatalf("could not close browser: %v", err)
}
if err = pw.Stop(); err != nil {
log.Fatalf("could not stop Playwright: %v", err)
}
}
Here is a breakdown of what each code section does:
- Package main - declaring the main package.
- Import {} - loading the dependencies.
- Func main() - this is the main function that Go runs when you run it from the terminal.
- pw, err := playwright.Run() - this creates a new playwright instance in the pw variable. The := operator is used to create a new variable. Go allows functions to return more than one value, so if there’s an error the playwright functions return an error that is saved in the err variable.
- if err != nil {} - You’ll notice this test repeated in all blocks. It’s there for better error handling. Each block tests if there was an error in the previous function and tells you where the error is.
- browser, err := pw.Chromium.Launch() - This launches the Chromium browser. You could use other browsers here, such as Firefox.
- page, err := browser.NewPage() - Open a new browser tab and saves it in the page variable.
- page.Goto(
https://ipv4.icanhazip.com/, playwright.PageGotoOptions{}) - This is equivalent to typing an address in the URL bar. - page.Screenshot(playwright.PageScreenshotOptions{}) - Take a screenshot and save it as “screenshot.png”.
- browser.Close(); - Close the browser along with all tabs
- pw.Stop(); - Stop Playwright.
You can run your Golang web scraper with this command:
go run main.go
If you don’t see any error messages, the screenshot worked fine. You should see something like this:
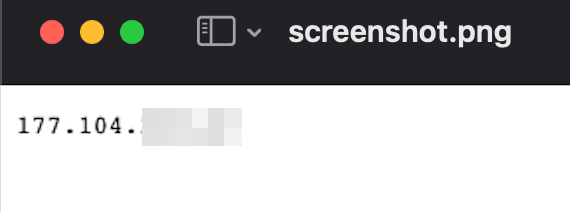
How Do You Use a Playwright Proxy?
You can use a Playwright proxy with the launch options for your browser.
First, sign up for the IPRoyal’s residential proxies service. Then you get access to your client area, where you can see your connection credentials:
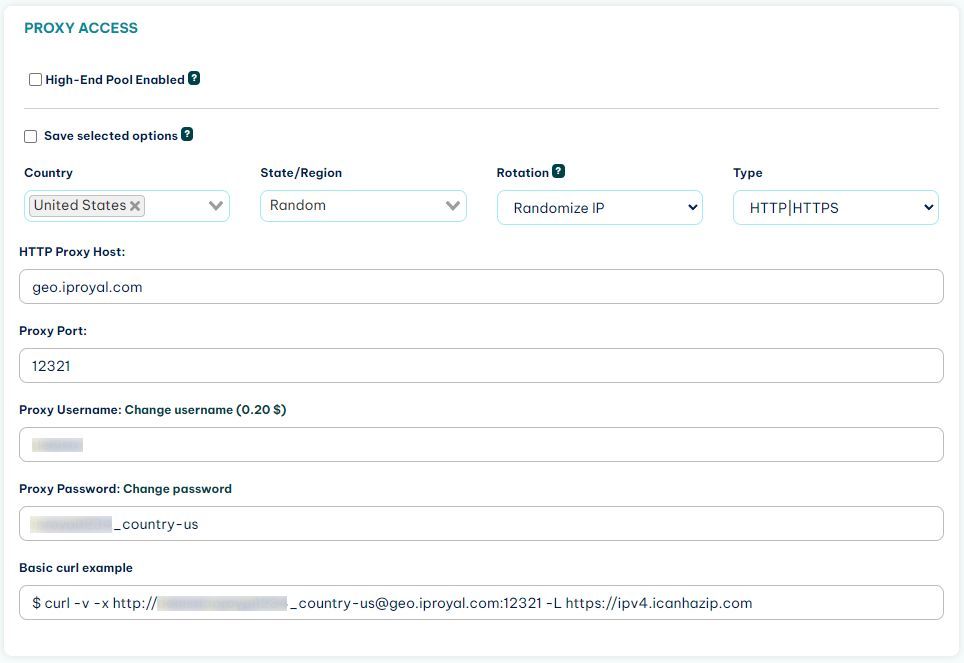
In this case, the connection is set to randomize the IP address, so you get a new IP address in each of your connections. Now you can use this data in your Golang web scraper.
Replace this code:
browser, err := pw.Chromium.Launch()
With this one:
proxyOptions := playwright.BrowserTypeLaunchOptionsProxy{
Server: playwright.String("geo.iproyal.com:12321"),
Username: playwright.String("username"),
Password: playwright.String("password"),
}
browser, err := pw.Chromium.Launch(playwright.BrowserTypeLaunchOptions{
Proxy: &proxyOptions,
})
Notice that you are using two new components. The proxyOptions variable stores the proxy details. Don’t forget to replace the username and password with your real credentials.
Then, you can use these options in the BrowserTypeLaunchOptions.
Run your code again, and you should see a screenshot with a different IP address.
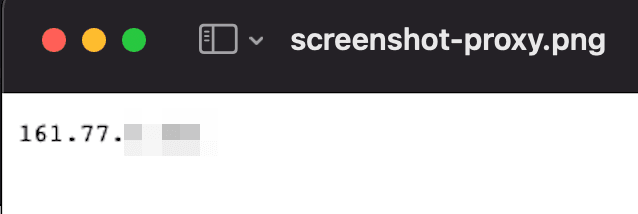
There are many other launch options that you can explore. You can use different user agents, different locations, timeout options and more.
In addition, there are many options for your screenshots as well. You can take full screen screenshots, change the browser size, take screenshots of a specific element.
How to Extract Data From Elements
You can extract data from elements by selecting them, then saving their text contents in a variable.
You can use the QuerySelectorAll or the QuerySelector methods to select elements using CSS code.
Here is an example, use this block instead of the previous GoTo line:
if _, err = page.Goto("https://playwright.dev/", playwright.PageGotoOptions{
WaitUntil: playwright.WaitUntilStateNetworkidle,
}); err != nil {
log.Fatalf("could not goto: %v", err)
}
herotitle, err := page.QuerySelector(".hero__title")
text, err := herotitle.TextContent()
fmt.Print(text)
This code loads the playwright site, then selects the element ".hero__title" and outputs its contents:

You can save this text in a database or use it for further interactions.
How to Click on Buttons and Fill In Forms
You can interact with pages using Playwright in any way a real visitor would. So you can click on buttons, fill in forms, scroll pages, use the keyboard, right-click, and even use the browser developer tools.
Similar to extracting text contents, you can query an element using CSS code, then click on it, or fill in form fields.
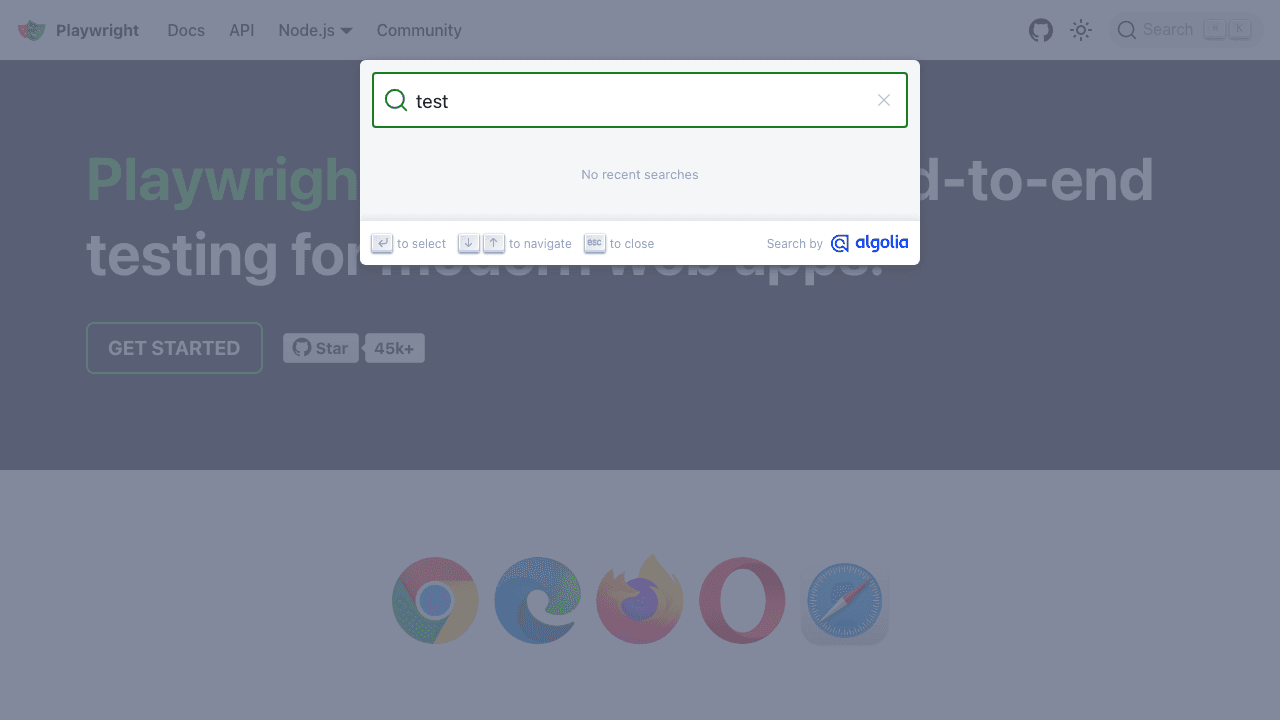
Here is an example on how to do both:
button, err := page.QuerySelector(".DocSearch-Button")
button.Click()
input, err := page.QuerySelector("#docsearch-input")
input.Fill("test")
Notice that you need to assign an error variable, even if you aren’t using it.
This is the result:
Conclusion
Today you learned how you can use Playwright to create a Golang web scraper. You can use it to automate data collection and actions. This is just a start, though. You can perform complex actions, such as video screen recording, load data from multiple pages, save PDFs, execute JS code on pages, and more.
We hope you’ve enjoyed it, and see you again next time!
FAQ
Module found, but does not contain package
$GOPATH/go.mod exists but should not
This usually happens when you try to create the go.mod file on the main /go folder. Make sure you have created it in a sub-folder and if there is any go.mod file there, delete it.
cannot use "text" (untyped string constant) as *string value in struct literal
You might get this and similar errors in your Golang code. You need to wrap strings in playwright options with playwright.String() and other similar methods to make sure they are processed correctly. Read more about strings in Go. The same goes for passing an object, like the proxy options. You need to prepend it with &, so instead of:
browser, err := pw.Chromium.Launch(playwright.BrowserTypeLaunchOptions{
Proxy: proxyOptions,
})
Use this:
browser, err := pw.Chromium.Launch(playwright.BrowserTypeLaunchOptions{
Proxy: &proxyOptions,
})


