'/%3e%3cellipse%20opacity='0.34'%20cx='327.5'%20cy='339'%20rx='264.5'%20ry='264'%20fill='url(%23paint1_linear_12724_35442)'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_12724_35442'%20x1='327'%20y1='-2.524e-06'%20x2='327'%20y2='389.286'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%2327D9E5'/%3e%3cstop%20offset='0.927406'%20stop-color='%23004047'%20stop-opacity='0'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_12724_35442'%20x1='328.02'%20y1='74.7771'%20x2='328.02'%20y2='395.312'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%2327D9E5'/%3e%3cstop%20offset='0.927406'%20stop-color='%23004047'%20stop-opacity='0'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)
A Beginner’s Guide to Scraping Google Maps: Python Tutorial
Tutorials

Vilius Dumcius
Key takeaways:
- Various business use cases can benefit from Google Maps data.
- Scraping Google Maps is generally legal, but Google might still restrict your IP address or account.
- Google Maps API might be convenient, but it’s expensive and still includes request limitations.
- Using a custom Python scraper is better for customization and future scaling.
- A basic Google Maps scraper can be created in six steps with various further additions possible.
Google Maps hosts a wealth of the most recent data on local businesses. You’ll find customer reviews, prices, contacts, and all else for places around you. Companies use Google Maps data themselves, but cases like lead generation and competitor analysis require it on a much larger scale and possibly for varied locations.
The first steps for scraping Google Maps for such purposes might seem daunting for a beginner. There are some coding, legal considerations, and other challenges to navigate. It won’t seem that difficult once you follow the steps on how to scrape Google Maps data we outlined below.
Why Scrape Google Maps?
As with all web scraping projects, it’s good to start by defining your goals. Google Maps data covers a lot about local businesses, but you might only need a few selected data points. Consider your use case to build a custom Google Maps scraper focusing on specific data you need.
- Sentiment analysis
Google Maps is a great way to see what customers of a particular brand or shop think about the business. You can collect reviews and ratings with different timestamps from varied locations to draw conclusions.
- Lead generation
Finding sales leads based on businesses in a particular location is much easier with Google Maps data. Contact information, business type, locations, social media profiles, and even visual data about a client will come in handy.
- Competitor analysis
Finding competitors and analyzing how they are doing is much easier with Google Maps data. Geographic distribution of competitors, their reviews and ratings, prices, and niches are some of the most relevant data points.
- Location analysis
Instead of focusing on businesses, Google Maps data can be useful for analyzing locations themselves. Look into traffic trends, population density, nearby services, and similar data to make better decisions.
- Supplementing other data sources
Google Maps is a great resource to add to your current datasets as it has some of the best real-time data on addresses, ratings, working hours, and much more.
Focusing on the data you need the most from Google Maps will save resources at every step of the process. You’ll collect data faster, will need fewer proxies, and have an easier time parsing the data later. It also helps when avoiding potential legal challenges.
Is Scraping Google Maps Legal?
Collecting publicly available data online is generally considered legal. Except for copyrighted or personal data, most information on Google Maps qualifies as such, but there are some caveats. Google’s terms of service explicitly prohibit automated collection of data, and they actively take measures to prevent it.
Even if your use case is completely legal, Google may still block your IP address or even terminate your account when you scrape Google Maps. Some of the limitations are quite reasonable, as a custom Python scraper might put too much strain on the servers, potentially making Google Maps slower for ordinary users.
Such ethical considerations don’t apply when you scrape Google Maps data at a reasonable pace while respecting robots.txt in general. If you have any doubts about the legality of Google maps scraping for your use case, it’s recommended to seek legal advice before proceeding.
Challenges in Scraping Google Maps
Some prefer to use the official Google Maps API to avoid the hurdles. It’s similar to other APIs that allow users to collect needed data, but the convenience incurs a high cost. The Google Maps API is priced for each request or map load over a modest free threshold.
The cost of Google Maps API may grow to thousands per month, and even when paying, you’ll face certain limits and restrictions. For example, Google Maps API is not available in all countries, and there are limits to how many requests you can send. Some of the restrictions can be mitigated by using a Google Maps API proxy .
You are likely to gain more freedom and reduce costs when you scrape Google Maps results with a custom Python tool. There are other reasons for choosing web scraping over APIs for data collection. It depends on your use, but in most cases, Google Maps API will be more costly and still with restrictions.
That’s not to say that web scraping with a headless browser is without any challenges. If you send too many automated requests, Google might suspect you are using a bot and ask you to solve CAPTCHAs. Most scrapers stop data collection under such circumstances.
Even when avoiding CAPTCHAs, you might still raise suspicions by collecting too much data from Google Maps, which leads to your IP address getting banned. A custom Python scraper is great for overcoming such challenges.
You can easily implement proxies or change other settings to continue collecting the needed data. Even if the interface of Google Maps changes or some new anti-scraping measures are implemented, a Python scraper can be customized to overcome them.
Step-by-Step Guide: How to Scrape Google Maps Using Python
The below steps will show you how to scrape Google Maps data for the ‘best kebab in Berlin’ from the very beginning. Our Google Maps scraper will use Selenium to control the Google Chrome headless browser with Python commands to find the needed data and extract it.
To minimize possible restrictions and improve access, we’ll also use proxies. Selenium-Wire and a few Python libraries will be used to extend the functionalities of Selenium to better fit Google Maps. The tutorial will introduce all the tools step by step.
1. Setup
Start by installing Python by following the installation steps from the official website and get an IDE such as Pycharm or Visual Studio Basic for easier development. Then, open the Terminal and run the below command line.
pip install selenium selenium-wire beautifulsoup4 pandas webdriver-manager blinker==1.4.0
If you are using a macOS device, replace the pip command with pip3. Once everything is done, you'll have Selenium and all the needed Python libraries ready to be used in your script.
2. Proxy Integration
We'll use residential proxies from IPRoyal as they rotate your IP address with every request automatically. Other types of proxies might also work with a Google Maps scraper. You'll need to choose a required location and note your client URL (cURL) for later use in the code.
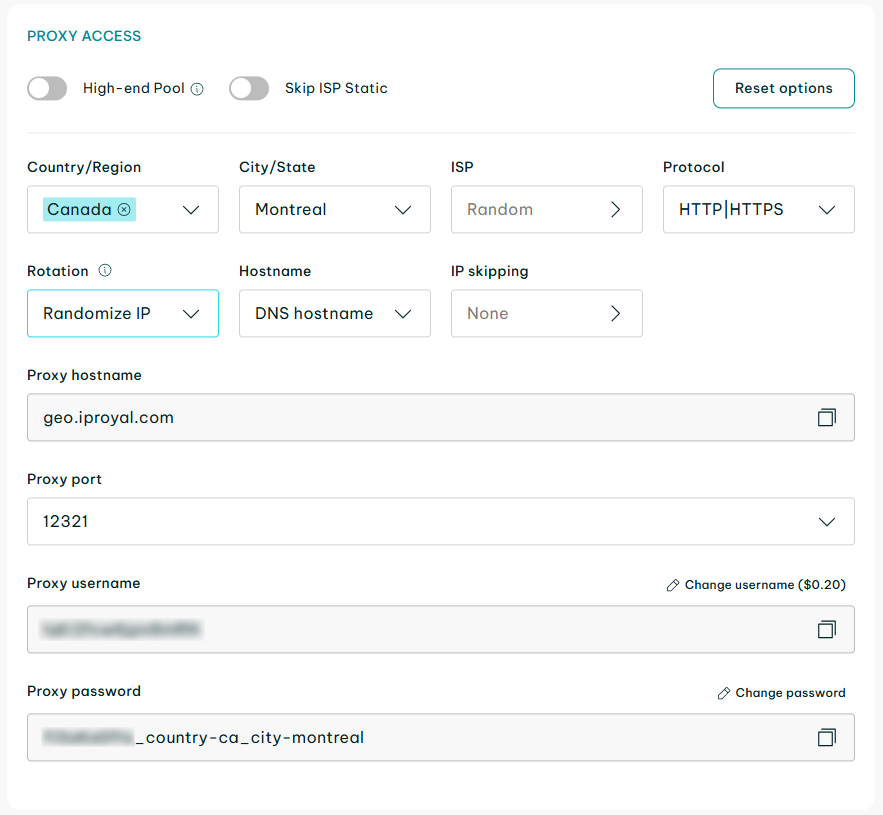
cURL will act as an access link to your proxies, so be sure to keep it secret and don't share it outside your Google Maps scraper. There's a residential proxies quick start guide if you need more detailed instructions.
3. Writing The Script
Create a new Python file and name it maps_scraper.py, for example. Most code editors will let you do it by simply saving the file. Then, import the required libraries there by pasting the lines below.
from seleniumwire import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
from bs4 import BeautifulSoup
import pandas as pd
Now, we can add proxies to our script. Simply replace
http://username:password@geo.iproyal.com:12321
with your cURL link and add it in the code.
proxy_options = {
'proxy': {
'http': 'http://username:[email protected]:12321',
'https': 'http://username:[email protected]:12321',
}
}
At this step, we can instruct the scraper to initialize Chrome WebDriver with our proxy settings and navigate to Google Maps.
options = Options()
service = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service, options=options, seleniumwire_options=proxy_options)
driver.get("https://www.google.com/maps")
driver.quit()
You can save the file and try to run the code. If all is well, our Google Maps scraper will open the Chrome browser with a window that asks to accept cookies and instantly close the browser. Our next step will be accepting them.
Be sure to move the driver.quit() command to the end after adding further code, as it closes all the windows and ends the session.
4. Accepting Cookies
The easiest way to accept cookies on Google Maps or most other websites is by using the query language Xpath, which allows us to select a button with Accept all text. Then, we can press it with a click() function. We'll also add a short wait time for the script to wait for the pop-up.
try:
cookie_button = WebDriverWait(driver, 20).until(
EC.element_to_be_clickable((By.XPATH, '//button[contains(., "Accept all")]'))
)
cookie_button.click()
except Exception as e:
print("Cookie acceptance failed:", e)
Note that Google Maps might change the layout of the pop-up later or adjust it according to the language you use. You might also be required to scroll down the page, which can be done by adding a line similar to this.
driver.execute_script("arguments[0].scrollIntoView(true);", accept)
After some adjustments, your Google Maps scraper should be able to accept the cookies. The next step is finding the needed information.
5. Finding Search Results
Our target query - 'best kebab in Berlin' can be completed by instructing our headless browser to perform a search using it.
try:
search_box = driver.find_element(By.XPATH, '//input[@id="searchboxinput"]')
search_box.clear()
search_box.send_keys("best kebab in Berlin")
search_box.send_keys(Keys.RETURN)
time.sleep(5)
Note: For the code block to work, you need to paste everything up until the end of the “except” block.
Then, we need to locate the first restaurant in the Google Maps search results. Just as with cookies, the interface and language vary, so you might need to find the correct XPath that corresponds to the name of the first restaurant.
Google Maps is structured in div elements. You can use the inspect function on the Chrome browser to find the class names. In our case, the title of the first search result class is named hfpxzc.
html_source = driver.page_source
soup = BeautifulSoup(html_source, "html.parser")
first_restaurant = driver.find_element(By.XPATH, '(//a[@class="hfpxzc"])[1]')
Once we locate the top search result from Google Maps, we can get the code to be displayed on our screen using the Print function. This will allow us to verify whether the code is functioning as intended and let us search for errors if any occur.
restaurant_name = first_restaurant.get_attribute("aria-label")
print("The first restaurant in the search results is:", restaurant_name)
except Exception as e:
print("Error:", e)
If at this point your code displays the needed Google Maps data, the last step remaining is to extract it.
6. Parsing and saving to a CSV file
We'll use BeautifulSoup to get the full Google Maps page source for parsing. In case there are any issues, we'll ask the script to display the full structure of the page.
html_source = driver.page_source
soup = BeautifulSoup(html_source, "html.parser")
print(soup.prettify())
The last line below can be changed or supplemented by other elements. So, if you scrape Google Maps for more data, find its class name and insert it into the code accordingly. Here, we stick to the name so as not to complicate the code.
first_result_bs = soup.find("a", class_="hfpxzc")
if first_result_bs:
name_bs = first_result_bs.get("aria-label").strip()
Note: For the current step to work, you have to paste everything in the box below to include the else: statement as well.
Next, we instruct the Google Maps scraper to display the information, store it in a dictionary, and save it into a CSV file. In case there are more data points to extract, they must be defined here similarly or if you want to extract a large number of data points, use a *for *loop.
print("Restaurant Name (BeautifulSoup):", name_bs)
restaurant_data = {"Name": name_bs}
else:
print("No results found")
restaurant_data = {"Name": None}
df = pd.DataFrame([restaurant_data])
df.to_csv("top_kebab_berlin.csv", index=False)
print("Data saved to top_kebab_berlin.csv")
7. Final Code and Further Additions
from seleniumwire import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
from bs4 import BeautifulSoup
import pandas as pd
options = Options()
service = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service, options=options)
driver.get("https://www.google.com/maps")
try:
cookie_button = WebDriverWait(driver, 20).until(
EC.element_to_be_clickable((By.XPATH, '//button[contains(., "Priimti viską")]'))
)
cookie_button.click()
except Exception as e:
print("Cookie acceptance failed:", e)
try:
search_box = driver.find_element(By.XPATH, '//input[@id="searchboxinput"]')
search_box.clear()
search_box.send_keys("best kebab in Berlin")
search_box.send_keys(Keys.RETURN)
time.sleep(5)
html_source = driver.page_source
soup = BeautifulSoup(html_source, "html.parser")
first_restaurant = driver.find_element(By.XPATH, '(//a[@class="hfpxzc"])[1]')
restaurant_name = first_restaurant.get_attribute("aria-label")
print("The first restaurant in the search results is:", restaurant_name)
except Exception as e:
print("Error:", e)
html_source = driver.page_source
soup = BeautifulSoup(html_source, "html.parser")
print(soup.prettify())
first_result_bs = soup.find("a", class_="hfpxzc")
if first_result_bs:
name_bs = first_result_bs.get("aria-label").strip()
print("Restaurant Name (BeautifulSoup):", name_bs)
restaurant_data = {"Name": name_bs}
else:
print("No results found")
restaurant_data = {"Name": None}
df = pd.DataFrame([restaurant_data])
df.to_csv("top_kebab_berlin.csv", index=False)
print("Data saved to top_kebab_berlin.csv")
driver.quit()
The code can now scrape Google Maps for data on the best kebab places in Berlin and extract it to a CSV file. You can tweak it to add further Google Maps data for extraction, such as ratings, reviews, and addresses.
Additionally, you can implement various wait times to ensure that all the data has time to be fully loaded.
However, if you start scraping more Google Maps data, you might need extra security measures. More proxies or different user agents might be helpful to avoid CAPTCHAs or other restrictions.
Conclusion
The key thing to remember is that you'll need to adjust the way you scrape Google Maps for the data you need. The guide here gives you a head start on how to scrape Google Maps. Later additions will require more advanced knowledge, but even a beginner can start to scrape Google Maps.


