'/%3e%3cellipse%20opacity='0.34'%20cx='327.5'%20cy='339'%20rx='264.5'%20ry='264'%20fill='url(%23paint1_linear_12724_35442)'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_12724_35442'%20x1='327'%20y1='-2.524e-06'%20x2='327'%20y2='389.286'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%2327D9E5'/%3e%3cstop%20offset='0.927406'%20stop-color='%23004047'%20stop-opacity='0'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_12724_35442'%20x1='328.02'%20y1='74.7771'%20x2='328.02'%20y2='395.312'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%2327D9E5'/%3e%3cstop%20offset='0.927406'%20stop-color='%23004047'%20stop-opacity='0'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)
How to Scrape Redfin Data: A Step-by-Step Guide for 2026
Python

Justas Vitaitis
Key Takeaways
-
Redfin is a popular source of accurate property listing data, reviewed by professional real estate agents.
-
Scraping Redfin for property data is technically legal, as it is public data, but against the site's terms of use.
-
Redfin does not have an official API. While there are unofficial ones, a Redfin scraper can work without them.
-
With some modifications, a Python scraper using Selenium, BeautifulSoup, and Pandas libraries can work effectively.
For quite some time now, the real estate market has shifted towards digital transactions. While it eases the process of selling, buying, or renting, early movers with timely access to real estate data have a significant advantage.
Collecting data manually is no longer an option if you’re managing properties, building a real estate data aggregator website , or want market insights. One of the most popular places to scrape data on real estate properties is Redfin.
What Is Redfin and Why Scrape It?
Redfin is one of the leading real estate platforms, operating in over a hundred markets in the United States and Canada. It stands out as not only a place for buying and selling homes but also as featuring thousands of its own real estate agents.
Because of such a business model, Redfin is a great place to find detailed and up-to-date insights on property listings.
- Current and historical listing prices
- Listing status
- Property specifications (type, size, year built, etc.)
- Neighborhood quality indicators (amenities, schools, transit points, etc.)
- Expected fees and policies
- Similar property listings
- Real estate market forecasts
While platforms like Zillow and Realtor are often considered more popular, Redfin provides better data quality in certain areas, particularly in places where Redfin has lots of its own real estate agents that curate datasets.
When you scrape property data from Redfin, you can be sure to get detailed and real-time data that is widely useful for various cases. Data collection for real estate market analysis, investment decisions, and professional services will benefit from a Redfin scraper.
Is It Legal to Scrape Redfin?
As with most websites, it is legal to scrape data that is publicly available on Redfin. Unless, of course, it’s personal data within property listings that may be subject to privacy laws like GDPR or CCPA.
So, using a Redfin scraper to collect property listing prices, sizes, built years, and similar information is generally within the law. Targeting the seller’s name, contact, and others is out of bounds.
Yet, scraping property data from Redfin still falls into a legally grey area due to the terms of use. Redfin explicitly prohibits web scraping or other automated means of data collection.
There is, however, a long discussion about browsewrap and clickwrap agreements and the legal consensus is that browsewrap (you implicitly agree to the terms of use by simply visiting the website) is unenforceable. So, as long as you don’t need to explicitly agree to terms (such as when logging in), you should be in the clear.
Generally, if you follow ethical scraping practices, such as following robots.txt and limiting request rates, you should be fine. If you are planning to collect real estate data, we always recommend consulting with a professional lawyer.
Does Redfin Have an API?
Redfin does not offer a public API to collect real estate data. Instead, they publish some real estate market data reports officially on their data center page . Compared to a Redfin scraper or API, these data reports lack comprehensiveness.
Developers working with web scraping have reverse-engineered some internal API endpoints that the Redfin website uses. A Redfin data scraper could potentially leverage them, but such APIs are frequently modified, and there is no official documentation or support.
Some companies offer unofficial APIs they have developed to scrape data from Redfin. Such solutions are quite expensive, as you need to pay for each request you make or data set you download. Often, you still need proxy servers to change your IP address and avoid blocks.
This is largely because Redfin’s terms of use explicitly prohibit reverse engineering their APIs, so you are likely to face restrictions when using unofficial APIs. Since you’ll still need to use proxies, the expenses might be lower when using your own Redfin web scraper instead of an unofficial API.
If you want to avoid coding at all costs, using a no-code web scraper might be an option. However, depending on the type of Redfin data you need, building a web scraper for that might not be that complicated.
What Data Can You Scrape from Redfin?
We can highlight three main categories of data that a Redfin web scraper should be able to collect. Each category can be evaluated in terms of how difficult it is to build a web scraping project around it.
- Basic property data includes listing type, price, full address, number of beds, baths, and lot size of property listings. Web scraping projects for collecting such data are popular for many use cases and are relatively easy to build. All data is consistently structured in the search results, but you’ll need to handle pagination.
- Individual property listings comprise the most data: prices, status, lot size, year built, parking spaces, fees, surrounding amenities, and other property details. A web scraper collecting such data will need to handle dynamic content (interactive maps, tabs, click and scroll-triggered content) as well as advanced parsing techniques.
- Neighborhood and market data used for large-scale market analysis consists of median prices, size, parking spaces, and other trends in an area. Collecting such data is challenging as it’s spread across multiple components and pages. It would also require advanced parsing techniques to transform the raw data into the needed format.
How to Scrape Redfin (Step-by-Step)
The steps here will lead you to building the basis for scraping property data on Redfin search results. We’ll use the top five New York homes for sale and collect their addresses and prices.
Setup and Libraries
Start by installing Python from the official website if you haven’t already. Also, install an IDE, such as PyCharm or Visual Studio Basic, for easier coding. Then, open the terminal and run the following command:
pip install selenium selenium-wire beautifulsoup4 pandas webdriver-manager blinker==1.4.0
If you're using a macOS device, use the pip3 command instead of pip. This will install the needed Python libraries for our web scraping project:
- Selenium is a browser automation tool for navigating and interacting with the Redfin website.
- Selenium-wire extends Selenium to inspect and modify HTTP requests and responses.
- BeautifulSoup4 is a Python library for parsing HTML and extracting elements.
- Pandas is a data analysis tool used here to export data into CSV files.
- WebDriverManager helps download and manage ChromeDriver.
- Blinker is a Signaling library required for internal communication.
Proxy Integration
Rotating residential proxies from IPRoyal are your best bet for scraping data undetected and with minimal restrictions. Depending on your use cases, other proxy types might work as well. Here's a quick start guide on how to set them up.
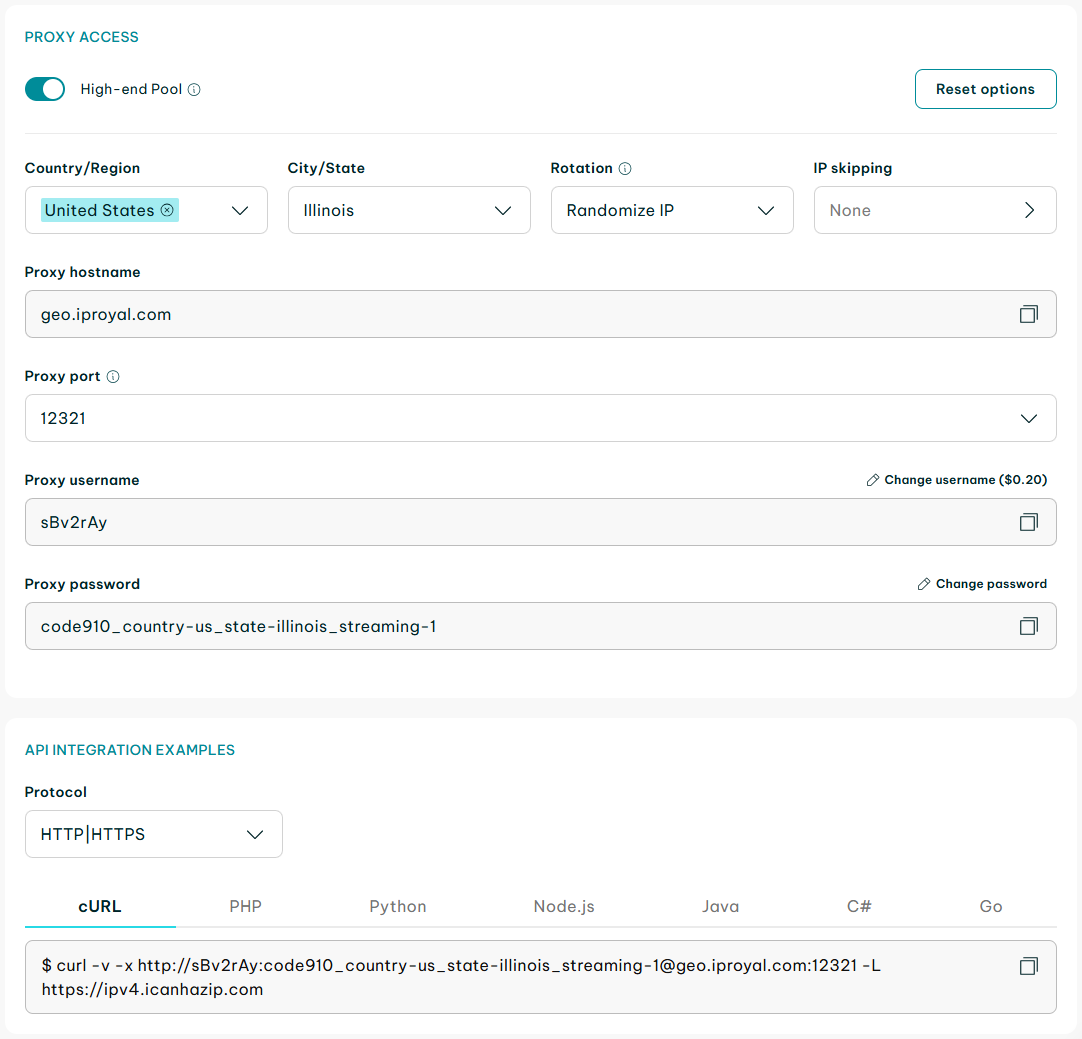
Essentially, you only need to add the client URL (cURL) access link in your code. Replace http://username:[email protected]:12321 with your cURL link, add it to the code below, and save it for later use.
proxy_options = {
'proxy': {
'http': 'http://username:[email protected]:12321',
'https': 'http://username:[email protected]:12321',
}
}
Import Libraries and Launch the Browser
Now we can start writing the script itself. The first thing to do is import the libraries we installed earlier. We'll also add the proxy credentials we prepared earlier.
from seleniumwire import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from webdriver_manager.chrome import ChromeDriverManager
from bs4 import BeautifulSoup
import pandas as pd
import time
# Proxy configuration (replace with your proxy details)
proxy_options = {
'proxy': {
'http': 'http://username:password@proxy-server:port',
'https': 'https://username:password@proxy-server:port',
'no_proxy': 'localhost,127.0.0.1' # Addresses to bypass proxy
}
}
The next step is to set up a headless Chrome browser and launch it.
# Initialize driver with selenium-wire and proxy
driver = webdriver.Chrome(
service=Service(ChromeDriverManager().install()),
options=options,
seleniumwire_options=proxy_options
)
At this point, we can test whether the code is working. We only need to add driver.quit() to end the session and remove the options.add_argument('--headless'). If a Chrome window opens and closes, the script is working properly.
Search Results for 'New York'
The next step is to go to https://www.redfin.com , locate the search box, and enter 'New York' there.
try:
# Navigate to Redfin
print("Navigating to Redfin...")
driver.get("https://www.redfin.com")
time.sleep(3) # Give page time to load
# Find the search box using the exact attributes from the HTML
print("Finding search box...")
# Wait for the search container to be present
search_container = WebDriverWait(driver, 20).until(
EC.presence_of_element_located((By.CSS_SELECTOR, "[data-rf-test-name='search-box']"))
)
# Find the search input using multiple strategies
search_input = None
search_selectors = [
"[data-rf-test-name='search-box-input']",
"#search-box-input",
"input[name='searchInputBox']",
"input.search-input-box"
]
for selector in search_selectors:
try:
search_input = driver.find_element(By.CSS_SELECTOR, selector)
if search_input:
print(f"Found search input with selector: {selector}")
break
except:
continue
if not search_input:
raise Exception("Could not find search input")
# Click on the search input to focus it
print("Clicking and focusing search input...")
actions = ActionChains(driver)
actions.move_to_element(search_input).click().perform()
time.sleep(1)
# Clear any existing text and type the search query
print("Entering search query...")
search_input.clear()
time.sleep(0.5)
# Type slowly to mimic human behavior
for char in "New York, NY":
search_input.send_keys(char)
time.sleep(0.1)
time.sleep(2) # Wait for suggestions to appear
# Press Enter to search
print("Submitting search...")
search_input.send_keys(Keys.RETURN)
# Alternative: Click the search button if Enter doesn't work
try:
search_button = driver.find_element(By.CSS_SELECTOR, "[data-rf-test-name='searchButton']")
search_button.click()
except:
pass
# Wait for the page to load and results to appear
print("Waiting for results page to load...")
time.sleep(5)
# Check if we're on a search results page
current_url = driver.current_url
print(f"Current URL: {current_url}")
If needed, this code can also be tested just as previously. This time, the script should open the Chrome browser, navigate to Redfin, and enter 'New York' in the search box.
Parsing and Saving
After the property listings in New York have loaded, our scraper can get to work. We'll instruct it to parse the page source with Beautifulsoup, scrape data on the top five property cards, and save everything to a CSV file using Pandas.
First, we’ll define a few functions so the code is cleaner. Note that the functions should go directly after imports.
from seleniumwire import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.action_chains import ActionChains
from bs4 import BeautifulSoup
import pandas as pd
import time
def extract_address_from_soup(card_soup):
"""Extract address from a BeautifulSoup parsed card"""
# Try multiple methods to find the address
# Method 1: Look for elements with Homecard__Address class
address_elem = card_soup.find(class_=lambda x: x and 'Homecard__Address' in x)
if address_elem:
return address_elem.get_text(strip=True)
# Method 2: Look for specific div with address-like classes
address_elem = card_soup.find(['div', 'span'], class_=['address', 'homeAddressV2'])
if address_elem:
return address_elem.get_text(strip=True)
# Method 3: Look for data attributes
address_elem = card_soup.find(attrs={'data-rf-test-id': 'abp-address'})
if address_elem:
return address_elem.get_text(strip=True)
# Method 4: Search for address pattern in text
# Look for text that contains street patterns
all_text = card_soup.find_all(text=True)
for text in all_text:
text = text.strip()
if text and any(pattern in text.lower() for pattern in ['ave', 'st', 'rd', 'blvd', 'dr', 'ln']):
# Check if it looks like an address (has numbers and isn't too long)
if any(char.isdigit() for char in text) and len(text) < 100:
return text
return None
def extract_price_from_soup(card_soup):
"""Extract price from a BeautifulSoup parsed card"""
# Try multiple methods to find the price
# Method 1: Look for elements with Homecard__Price class
price_elem = card_soup.find(class_=lambda x: x and 'Homecard__Price--value' in x)
if price_elem:
return price_elem.get_text(strip=True)
# Method 2: Look for any element with price-related class
price_elem = card_soup.find(class_=lambda x: x and 'price' in x.lower())
if price_elem:
text = price_elem.get_text(strip=True)
if '$' in text:
return text
# Method 3: Look for spans containing dollar signs
for span in card_soup.find_all('span'):
text = span.get_text(strip=True)
if text.startswith('$') and ',' in text:
return text
# Method 4: Search for price pattern in all text
all_text = card_soup.find_all(text=True)
for text in all_text:
text = text.strip()
if text.startswith('$') and ',' in text and len(text) < 20:
return text
return None
# Parsing page source with BeautifulSoup
soup = BeautifulSoup(driver.page_source, 'html.parser')
# Extracting property information
properties = []
for i in range(5):
card_xpath = f"//div[contains(@class, 'HomeCardContainer')][{i+1}]"
try:
card = driver.find_element(By.XPATH, card_xpath)
# Extract address and price using the generic class names
address = card.find_element(By.CSS_SELECTOR, ".homeAddressV2 span:nth-of-type(1)").text
price = card.find_element(By.CSS_SELECTOR, ".homecardV2Price").text
properties.append({"address": address, "price": price})
except Exception as e:
print(f"Error parsing card {i}: {e}")
continue
Note that for simplicity's sake, we used default class names to find elements that contain the information we need. The names of elements HomeCardContainer, homeAddressV2, and homecardV2Price will need to be found manually first.
Finding element names
- Head to the Redfin website on your browser.
- Use the search bar to get a list of properties.
- Right-click on any of them.
- Select ‘Inspect’.
- Hover over different parts of the HTML code to find the parts relating to the needed data.
- Note their class or ID attributes.
In our case, the address header class is named 'address' and the price is named 'stat-block price-section' class. The elements containing the data are named MapHomeCard, followed by respective numbers, indicating their place in the list, like this MapHomeCard_0. We can update our code using this information.
try:
WebDriverWait(driver, 20).until(
EC.presence_of_element_located((By.CSS_SELECTOR, "[data-rf-test-id='property-card']"))
)
except:
# Try alternative selectors
try:
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, "div[id^='MapHomeCard']"))
)
except:
print("Warning: Could not find property cards with expected selectors")
time.sleep(3) # Additional wait for all elements to render
# Get the page source and parse with BeautifulSoup
print("Parsing page with BeautifulSoup...")
page_source = driver.page_source
soup = BeautifulSoup(page_source, 'html.parser')
# Extract property information using BeautifulSoup
properties = []
# Find property cards using BeautifulSoup
property_cards = []
# Try multiple strategies with BeautifulSoup
# Method 1: Find by class
property_cards = soup.find_all('a', class_='bp-Homecard')
# Method 2: If not found, try finding by data attribute
if not property_cards:
property_cards = soup.find_all(attrs={'data-rf-test-name': 'basicNode-homeCard'})
# Method 3: Find divs with IDs starting with MapHomeCard
if not property_cards:
property_cards = soup.find_all('div', id=lambda x: x and x.startswith('MapHomeCard'))
print(f"Found {len(property_cards)} property cards using BeautifulSoup")
# If still no cards found, try using Selenium as fallback
if not property_cards:
print("BeautifulSoup couldn't find cards, trying Selenium...")
selenium_cards = driver.find_elements(By.CSS_SELECTOR,
"a.bp-Homecard, [data-rf-test-name='basicNode-homeCard']")
if selenium_cards:
print(f"Found {len(selenium_cards)} cards with Selenium")
# Process with Selenium method
for i, card in enumerate(selenium_cards[:5]):
try:
# Get the HTML of this specific card
card_html = card.get_attribute('outerHTML')
card_soup = BeautifulSoup(card_html, 'html.parser')
# Extract data from the parsed HTML
address = extract_address_from_soup(card_soup)
price = extract_price_from_soup(card_soup)
if address and price:
properties.append({
"address": address,
"price": price
})
print(f"Property {i + 1}: {address} - {price}")
else:
print(f"Property {i + 1}: Partial data (Address: {address}, Price: {price})")
except Exception as e:
print(f"Error parsing card {i}: {str(e)}")
continue
else:
# Process cards found by BeautifulSoup
for i, card in enumerate(property_cards[:5]):
try:
address = extract_address_from_soup(card)
price = extract_price_from_soup(card)
if address and price:
properties.append({
"address": address,
"price": price
})
print(f"Property {i + 1}: {address} - {price}")
else:
print(f"Property {i + 1}: Partial data (Address: {address}, Price: {price})")
except Exception as e:
print(f"Error parsing card {i}: {str(e)}")
Continue
Saving as a CSV File
Finally, we need to save the scraped data to a CSV file for further use and quit the driver.
Final Code
from seleniumwire import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.action_chains import ActionChains
from bs4 import BeautifulSoup
import pandas as pd
import time
def extract_address_from_soup(card_soup):
"""Extract address from a BeautifulSoup parsed card"""
# Try multiple methods to find the address
# Method 1: Look for elements with Homecard__Address class
address_elem = card_soup.find(class_=lambda x: x and 'Homecard__Address' in x)
if address_elem:
return address_elem.get_text(strip=True)
# Method 2: Look for specific div with address-like classes
address_elem = card_soup.find(['div', 'span'], class_=['address', 'homeAddressV2'])
if address_elem:
return address_elem.get_text(strip=True)
# Method 3: Look for data attributes
address_elem = card_soup.find(attrs={'data-rf-test-id': 'abp-address'})
if address_elem:
return address_elem.get_text(strip=True)
# Method 4: Search for address pattern in text
# Look for text that contains street patterns
all_text = card_soup.find_all(text=True)
for text in all_text:
text = text.strip()
if text and any(pattern in text.lower() for pattern in ['ave', 'st', 'rd', 'blvd', 'dr', 'ln']):
# Check if it looks like an address (has numbers and isn't too long)
if any(char.isdigit() for char in text) and len(text) < 100:
return text
return None
def extract_price_from_soup(card_soup):
"""Extract price from a BeautifulSoup parsed card"""
# Try multiple methods to find the price
# Method 1: Look for elements with Homecard__Price class
price_elem = card_soup.find(class_=lambda x: x and 'Homecard__Price--value' in x)
if price_elem:
return price_elem.get_text(strip=True)
# Method 2: Look for any element with price-related class
price_elem = card_soup.find(class_=lambda x: x and 'price' in x.lower())
if price_elem:
text = price_elem.get_text(strip=True)
if '$' in text:
return text
# Method 3: Look for spans containing dollar signs
for span in card_soup.find_all('span'):
text = span.get_text(strip=True)
if text.startswith('$') and ',' in text:
return text
# Method 4: Search for price pattern in all text
all_text = card_soup.find_all(text=True)
for text in all_text:
text = text.strip()
if text.startswith('$') and ',' in text and len(text) < 20:
return text
return None
# Proxy configuration (replace with your proxy details)
proxy_options = {
'proxy': {
'http': 'http://username:password@proxy-server:port',
'https': 'https://username:password@proxy-server:port',
'no_proxy': 'localhost,127.0.0.1' # Addresses to bypass proxy
}
}
# Setup Chrome options
options = webdriver.ChromeOptions()
options.add_argument('--disable-blink-features=AutomationControlled')
options.add_experimental_option("excludeSwitches", ["enable-automation"])
options.add_experimental_option('useAutomationExtension', False)
options.add_argument(
'user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36')
# Initialize driver with selenium-wire and proxy
driver = webdriver.Chrome(
service=Service(ChromeDriverManager().install()),
options=options,
#Wseleniumwire_options=proxy_options
)
try:
# Navigate to Redfin
print("Navigating to Redfin...")
driver.get("https://www.redfin.com")
time.sleep(3) # Give page time to load
# Find the search box using the exact attributes from the HTML
print("Finding search box...")
# Wait for the search container to be present
search_container = WebDriverWait(driver, 20).until(
EC.presence_of_element_located((By.CSS_SELECTOR, "[data-rf-test-name='search-box']"))
)
# Find the search input using multiple strategies
search_input = None
search_selectors = [
"[data-rf-test-name='search-box-input']",
"#search-box-input",
"input[name='searchInputBox']",
"input.search-input-box"
]
for selector in search_selectors:
try:
search_input = driver.find_element(By.CSS_SELECTOR, selector)
if search_input:
print(f"Found search input with selector: {selector}")
break
except:
continue
if not search_input:
raise Exception("Could not find search input")
# Click on the search input to focus it
print("Clicking and focusing search input...")
actions = ActionChains(driver)
actions.move_to_element(search_input).click().perform()
time.sleep(1)
# Clear any existing text and type the search query
print("Entering search query...")
search_input.clear()
time.sleep(0.5)
# Type slowly to mimic human behavior
for char in "New York, NY":
search_input.send_keys(char)
time.sleep(0.1)
time.sleep(2) # Wait for suggestions to appear
# Press Enter to search
print("Submitting search...")
search_input.send_keys(Keys.RETURN)
# Alternative: Click the search button if Enter doesn't work
try:
search_button = driver.find_element(By.CSS_SELECTOR, "[data-rf-test-name='searchButton']")
search_button.click()
except:
pass
# Wait for the page to load and results to appear
print("Waiting for results page to load...")
time.sleep(5)
# Check if we're on a search results page
current_url = driver.current_url
print(f"Current URL: {current_url}")
# Wait for property cards to load
try:
WebDriverWait(driver, 20).until(
EC.presence_of_element_located((By.CSS_SELECTOR, "[data-rf-test-id='property-card']"))
)
except:
# Try alternative selectors
try:
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, "div[id^='MapHomeCard']"))
)
except:
print("Warning: Could not find property cards with expected selectors")
time.sleep(3) # Additional wait for all elements to render
# Get the page source and parse with BeautifulSoup
print("Parsing page with BeautifulSoup...")
page_source = driver.page_source
soup = BeautifulSoup(page_source, 'html.parser')
# Extract property information using BeautifulSoup
properties = []
# Find property cards using BeautifulSoup
property_cards = []
# Try multiple strategies with BeautifulSoup
# Method 1: Find by class
property_cards = soup.find_all('a', class_='bp-Homecard')
# Method 2: If not found, try finding by data attribute
if not property_cards:
property_cards = soup.find_all(attrs={'data-rf-test-name': 'basicNode-homeCard'})
# Method 3: Find divs with IDs starting with MapHomeCard
if not property_cards:
property_cards = soup.find_all('div', id=lambda x: x and x.startswith('MapHomeCard'))
print(f"Found {len(property_cards)} property cards using BeautifulSoup")
# If still no cards found, try using Selenium as fallback
if not property_cards:
print("BeautifulSoup couldn't find cards, trying Selenium...")
selenium_cards = driver.find_elements(By.CSS_SELECTOR,
"a.bp-Homecard, [data-rf-test-name='basicNode-homeCard']")
if selenium_cards:
print(f"Found {len(selenium_cards)} cards with Selenium")
# Process with Selenium method
for i, card in enumerate(selenium_cards[:5]):
try:
# Get the HTML of this specific card
card_html = card.get_attribute('outerHTML')
card_soup = BeautifulSoup(card_html, 'html.parser')
# Extract data from the parsed HTML
address = extract_address_from_soup(card_soup)
price = extract_price_from_soup(card_soup)
if address and price:
properties.append({
"address": address,
"price": price
})
print(f"Property {i + 1}: {address} - {price}")
else:
print(f"Property {i + 1}: Partial data (Address: {address}, Price: {price})")
except Exception as e:
print(f"Error parsing card {i}: {str(e)}")
continue
else:
# Process cards found by BeautifulSoup
for i, card in enumerate(property_cards[:5]):
try:
address = extract_address_from_soup(card)
price = extract_price_from_soup(card)
if address and price:
properties.append({
"address": address,
"price": price
})
print(f"Property {i + 1}: {address} - {price}")
else:
print(f"Property {i + 1}: Partial data (Address: {address}, Price: {price})")
except Exception as e:
print(f"Error parsing card {i}: {str(e)}")
continue
# Save to CSV
if properties:
df = pd.DataFrame(properties)
df.to_csv("redfin_ny_top5.csv", index=False)
print(f"\nScraping complete. Saved {len(properties)} properties to redfin_ny_top5.csv")
else:
print("\nNo properties were successfully scraped.")
print("This might be due to:")
print("1. Redfin detecting automated browsing")
print("2. Changed page structure")
print("3. Location-based redirects")
# Save the HTML for debugging
with open("redfin_debug.html", "w", encoding="utf-8") as f:
f.write(soup.prettify())
print("Saved page HTML to redfin_debug.html for analysis")
except Exception as e:
print(f"An error occurred: {str(e)}")
print("Taking screenshot for debugging...")
driver.save_screenshot("redfin_error.png")
print("Screenshot saved as redfin_error.png")
finally:
# Always quit the driver
input("Press Enter to close the browser...") # This helps you see what happened
driver.quit()
Conclusion
The Python Redfin scraper we provided here gives the basis for automated data extraction of property listings in New York. Tweak it for your web scraping project with additional class names and different locations. Be mindful of ethical and legal implications.


