'/%3e%3cellipse%20opacity='0.34'%20cx='327.5'%20cy='339'%20rx='264.5'%20ry='264'%20fill='url(%23paint1_linear_12724_35442)'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_12724_35442'%20x1='327'%20y1='-2.524e-06'%20x2='327'%20y2='389.286'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%2327D9E5'/%3e%3cstop%20offset='0.927406'%20stop-color='%23004047'%20stop-opacity='0'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_12724_35442'%20x1='328.02'%20y1='74.7771'%20x2='328.02'%20y2='395.312'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%2327D9E5'/%3e%3cstop%20offset='0.927406'%20stop-color='%23004047'%20stop-opacity='0'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)
Java Web Scraping Without Getting Blocked: 2026 Guide
Tutorials

Marijus Narbutas
Key Takeaways
-
Modern websites require headless browsers like Playwright to handle JavaScript. Traditional parsers or regex are often outdated and easily blocked.
-
Use rotating residential proxies to hide your scrapers. They mimic real user behavior, bypass IP-rate limits, and hide your scraper's footprint.
-
Use Java to mimic real interactions, such as clicking buttons and filling forms, to access data hidden behind dynamic elements.
Web scraping with Java is an excellent choice for modern businesses. With it, you can collect data at scale, automate actions, monitor market changes, and more. Information is power, and web scraping is a reliable source of endless information. But it can be difficult.
Each target site requires a specific code. You can also get blocked. It might be hard to extract data from HTML. Most importantly, most Java web scraping tutorials are completely outdated: old parsers, unsupported libraries, regular expressions, and more.
In this Java web scraping tutorial, you’ll learn a simple way to scrape any website with Java. In addition, you will learn how to avoid getting blocked and how to take screenshots and extract data with your web scraper in Java.
Java Web Scraping: How It Works?
There are a few ways to scrape pages in general. In the past, a common way to do it was to get the HTML code from your target website. Then you would use regular expressions to extract data.
This method can work for basic sites, but it is quite challenging to set up. Also, these rules are extremely brittle: even a minor update to a website’s HTML structure will cause your scraper to fail instantly.
Sometime after that, HTML parsers appeared. They were libraries designed to navigate the site’s structure, but unlike modern tools, they couldn’t execute JavaScript or mimic a real browser.
The Best Java Web Scraping Libraries
Choosing the right Java library makes all the difference for your web scraping projects. We’ll talk in more detail about three tools: Jsoup, Selenium, and Playwright.
Jsoup
In the past, people used Jsoup for simple tasks. Jsoup is great for static pages because it’s fast and easy to learn. However, the Java library can’t handle a target website that uses lots of JavaScript – Jsoup lacks a JavaScript engine, so it cannot handle Client-Side Rendering (CSR).
If a site dynamically fetches data after the initial load, Jsoup will only see the empty HTML skeleton provided by the server.
Selenium
Selenium is another famous Java web scraping framework that many people know. It can open a real browser and click on things just like a person. This Java library makes it a solid choice for web scraping in Java, but it can be slow.
Selenium’s reliance on the older WebDriver protocol introduces significant latency. Because it communicates via HTTP requests for every action, it’s slower and more resource-heavy compared to modern, event-driven frameworks.
Playwright
The best way to perform web scraping in Java is by using a headless browser. Headless browsers let you control browser actions using the Java programming language . There are many good options out there, such as Puppeteer . However, there’s no official Puppeteer Java library. But there’s something even better called Playwright .
Playwright is the evolution of Puppeteer. It has the same actions and more, and it’s just as easy to use. With it, you can launch a single browser instance and create multiple isolated “Browser Contexts”. These act like separate, lightweight incognito sessions, allowing you to scale your web scraping with Java without the memory overhead of opening multiple full browser windows.
It allows you to target elements using resilient Locators, such as ARIA roles (button, link), text content, or test IDs. While it supports layout-based selection, modern best practices favor “User-First” selectors that don’t break when the UI layout changes.
You can also target them by text contents, or even by combining CSS and text selectors. For example, if you are building a price monitor, you can target an element with “Price” in it, as well as inside the main container.
Furthermore, Playwright excels at Network Interception. Instead of scraping the visual UI, you can intercept the site’s own internal API responses (XHR/Fetch), allowing you to extract structured JSON data directly from the source.
Playwright, Java, and Some Examples
We’ll cover everything from the very basics of installing an IDE to processing your data.
Here are our primary goals:
- Install a Java IDE
- Install Playwright
- Fix common issues
- Connect to a site
- Take a screenshot
- Connect to a site using authenticated proxies
- Collect data
Web Scraping With Java - The First Steps
One of the benefits of Java is its cross-platform nature. We highly recommend using Java 21 or later, as its Virtual Threads allow you to scale your web scraping operations significantly with minimal memory overhead. Once you compile the code, you can run it on any OS you want. This is handy in case you have multiple computers, and you need to jump around between them.
For this reason, you need a code editor and compiler. So if you haven’t already, install an IDE. We recommend using IntelliJ IDEA (Community Edition is free) or VS Code, as they offer superior support for modern Java features and integrated terminal management for Playwright.
Then you need Maven . If you are using Eclipse, you don’t need to install it, but depending on your IDE, you will need it. With Maven, you can easily build projects with external dependencies without manually downloading them.
In Eclipse, go to ‘File’ > ‘New’ > ‘Other (Command + N)’. Search for Maven and select ‘Maven Project’:
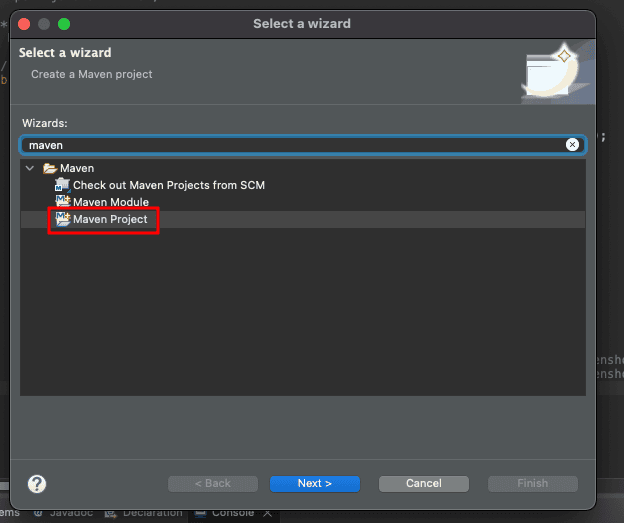
Click on ‘Next’. Select the maven-archetype-quickstart archetype. It ensures your project follows the standard Maven directory structure (src/main/java), which prevents “Class Not Found” errors later on. Add your ‘Group ID’, ‘Artifact ID’, and further details about your project. Finally, click on ‘Finish’.
You should see a new project in your ‘Package Explorer’. Wait a few seconds, and you’ll see the files and dependencies being created.
Moving on, open the pom.xml file. This is the file that tells Maven what this project is, what kind of dependencies it has, and so on. Here’s the original file:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.iproyal</groupId>
<artifactId>com.iproyal.webscraper</artifactId>
<version>0.0.1-SNAPSHOT</version>
</project>
After adding the dependency, Playwright needs to download the browser binaries. You can do this by running this in your terminal:
mvn exec:java -e -D exec.mainClass=com.microsoft.playwright.CLI -D exec.args="install"
Alternatively, Playwright will attempt to download them automatically the first time you run your code.
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.iproyal</groupId>
<artifactId>com.iproyal.webscraper</artifactId>
<version>0.0.1-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>com.microsoft.playwright</groupId>
<artifactId>playwright</artifactId>
<version>1.57.0</version>
</dependency>
</dependencies>
</project>
Now, let's create your package and your main class.
Right click the 'src/main/java' folder, and select 'New package'. Make sure you keep the 'Create package-info.java' option unchecked.

And inside the package, we need to create a class. Right click the package and click on 'New class'. Check the option to create a 'public static void main', to save you a bit of typing:
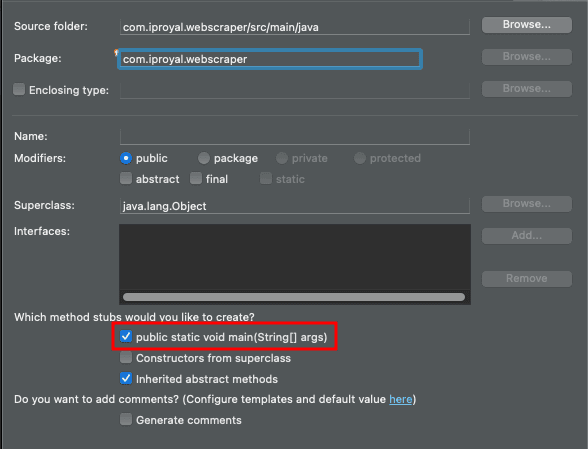
Java Screen Scraping
Now you just need to add your scraper code there, compile it, and you'll see the results in the console. If there are any errors, your IDE should highlight them to you.
Let's start with taking screenshots. To make it easier, use this code at the beginning of your file for all examples. You'll see some warnings sometimes that the package isn't used, but you can ignore them.
package com.iproyal.scraper;
// import playwright and the proxy packages
import com.microsoft.playwright.*;
import com.microsoft.playwright.options.Proxy;
// import some useful packages
import java.nio.file.Paths;
import java.util.Arrays;
import java.util.List;
Next, use this code as your public static void main class:
public static void main(String[] args) {
try (Playwright playwright = Playwright.create()) {
BrowserType.LaunchOptions launchOptions = new BrowserType.LaunchOptions();
try (Browser browser = playwright.chromium().launch(launchOptions);
BrowserContext context = browser.newContext()) {
Page page = context.newPage();
Page page = context.newPage();
page.navigate("https://ipv4.icanhazip.com/");
page.screenshot(new Page.ScreenshotOptions().setPath(Paths.get("screenshot-" + playwright.chromium().name() + ".png")));
System.out.println("Screenshot taken");
}
}
}
}
This code tries to open Playwright with Playwright.create(). Then it saves the LaunchOptions, but more on that later. Next, the code snippet opens a Chromium browser instance with:
playwright.chromium().launch(launchOptions).
Then it is quite similar to Puppeteer. Open a new page with newPage(), and navigate with page.navigate(" https://ipv4.icanhazip.com/ ). You can take a screenshot with:
page.screenshot(new Page.ScreenshotOptions().setPath(Paths.get("screenshot-" + playwright.chromium().name() + ".png")));
Each of these methods has customizing options. For example, if you want to specify a browser window size, you can do it. And you can add a specific file name for your screenshot as we did here.
Run this code, and if you didn't change anything else in your Eclipse settings you should see an error:
<span style="font-weight: 400;">Exception in thread "main" java.lang.Error: Unresolved compilation problem:</span>
<span style="font-weight: 400;"> References to interface static methods are allowed only at source level 1.8 or above</span>
But it's an easy fix. Right-click on your project, select 'Properties'. Then go to the 'Libraries' tab and click on your 'JRE version' > 'Edit'.
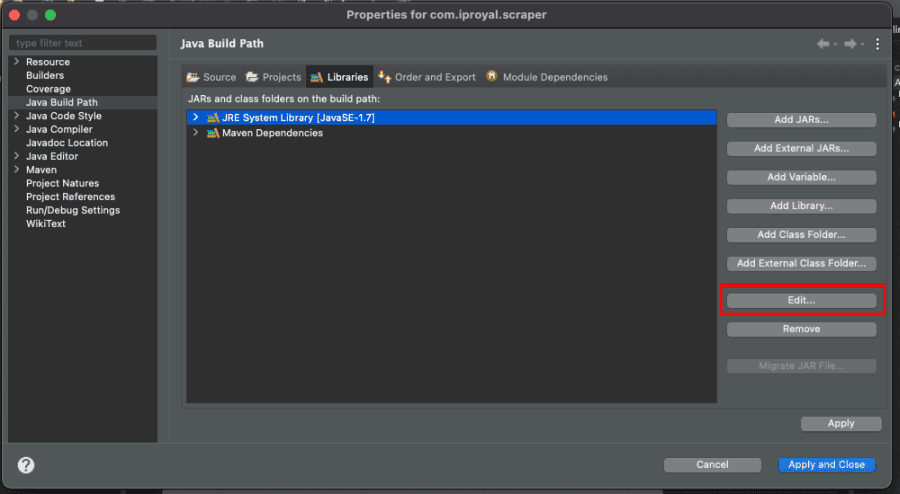
Select Java 21 or higher. While Playwright technically supports older versions, Java 21 offers the performance and virtual thread support necessary for high-scale scraping. Click on 'Apply and Close'.
Now rerun it, and you should see this message:

Go to your home folder /eclipse-workspace/[project]/ and you'll see your screenshot there. It should be titled screenshot-chromium.png.
You can also target specific branded browsers like Google Chrome or Microsoft Edge by setting the setChannel option in your LaunchOptions, or switch engines entirely using playwright.firefox() or playwright.webkit().
Common Challenges and How to Solve Them
Building a web scraper isn't always easy because websites try to stop you. You'll run into several walls while doing web scraping in Java. Here are the biggest ones and how to fix them.
Anti-bot Mechanisms & Captchas
Modern Web Application Firewalls (WAFs) analyze technical signals, like the consistency of your browser's hardware reports, to detect headless automation.
Beyond just proxies, you must ensure your Java scraper mimics a consistent User-Agent and hardware profile. It’s possible that a website might detect automation if those settings aren’t well configured. If it sees you're a bot, it may show a CAPTCHA.
These are puzzles that are hard for a Java scraper to solve. To counter it, you should use Stealth Extensions to patch browser fingerprints and integrate API-based CAPTCHA solvers.
These services intercept the puzzle and return a valid token to your Java code, allowing the web scraper to proceed automatically.
Rate Limiting & IP Bans
If you send too many requests too fast, the site will block you. It’s called rate limiting. They'll see that one IP is asking for too much data. The best fix is using rotating residential proxies.
Instead of managing the rotation in Java, you connect to a single entry gateway provided by your proxy service, which automatically assigns a new, organic IP address to every request or session.
Parsing Errors & Bad HTML
Sometimes a target website has spaghetti code. While modern browsers are great at fixing broken HTML, your web scraper will break if it tries to interact with elements that failed to load.
Use Locators with built-in auto-waiting and wrap your extraction logic in Optional types or try-catch blocks to handle missing data gracefully.
You should always use try-catch blocks in your code to handle these errors. It keeps your web scraping projects running even when things get messy.
Java Scraping Without Getting Blocked: Playwright Authenticated Proxies
Web scraping publicly available data is generally considered legal. However, as of 2026, regulations like the GDPR (Europe) and various state laws in the US have made it much stricter to scrape personal information or data protected by terms of service.
Also, companies don't like giving away information. For this reason, it's quite common for a website to block you when you are just starting your web scraping efforts. And in order to avoid getting blocked, you need to understand how websites block web scrapers in the first place.
There are a few things that can tell them right away. For example, a request without any user metadata (browser, OS, and other information) is likely coming from a software. Unless you manually add headers, many coding libraries won't add them for you.
While Playwright uses a real browser engine, a default headless instance still leaves digital footprints, like the navigator.webdriver flag, which anti-bot systems can detect. To make your request look truly human, you should use a stealth plugin or manually mask your browser's fingerprint.
Then they look at other points, such as your IP. If you request a lot of pages, leave quickly, and come around the same time, it's a sign that you are a bot. But the main way they do it is by checking your IP address.
So, the solution is to use IPRoyal's residential proxies service. With it, you can use rotating IP addresses from real residential users. This allows you to hide your real address, so the website owners just can't connect the dots.
Sign up for the service, and you'll get access to the client area. In it you can see the proxy URL and set up your credentials:
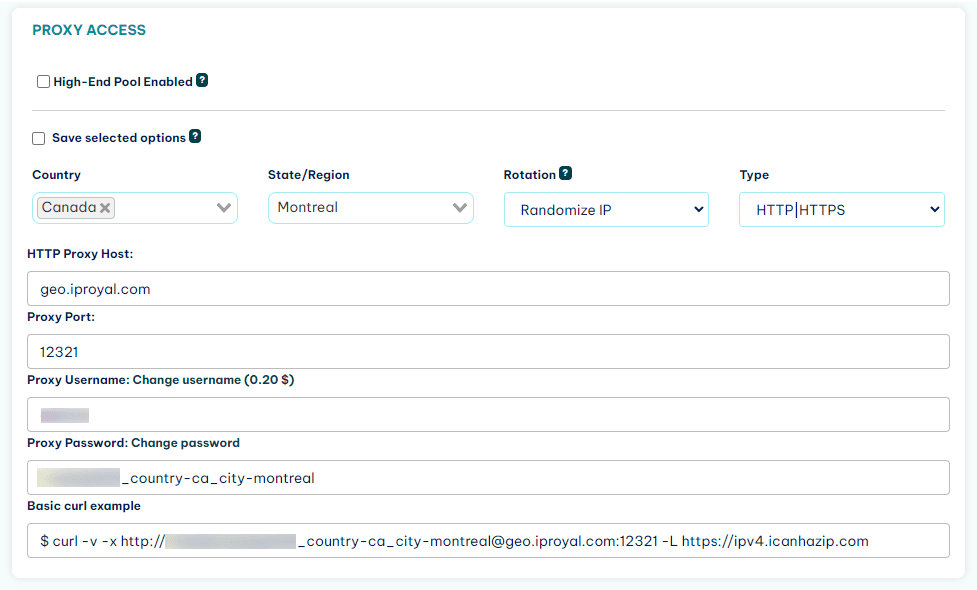
Now you just need to use this information in your Java web scraper, and you are good to go.
In the first step, you saved a screenshot with your IP address. It's something like this:
You can use the LaunchOptions to connect to IPRoyal and use a proxy in your request. This is the main class to do it:
public static void main(String[] args) {
try (Playwright playwright = Playwright.create();
Browser browser = playwright.chromium().launch(new BrowserType.LaunchOptions()
.setProxy(new Proxy("http://geo.iproyal.com:12321")
.setUsername("your_username")
.setPassword("your_password")));
BrowserContext context = browser.newContext()) {
Page page = context.newPage();
page.navigate("https://ipv4.icanhazip.com/");
page.screenshot(new Page.ScreenshotOptions()
.setPath(Path.of("screenshot-" + System.currentTimeMillis() + ".png")));
System.out.println("Screenshot taken with proxy IP!");
} catch (Exception e) {
System.err.println("Scraping failed: " + e.getMessage());
}
}
The entire main class stays the same, but now you are using the setProxy method to use a proxy, then add a username and password. This is the screenshot using a proxy in your Java web scraper:

It's an entirely different IP address. So, as far as the website owner knows, these are two different users visiting their site. If you enable the IP rotation, this address also changes for every request, making it very hard to detect.
Data Scraping With Java Programming Language
In addition to screenshots, you can take custom screenshots (full page, specific elements), get data from page elements, and interact with pages.
To make things easier, the following examples all go inside this block:
try (Browser browser = playwright.chromium().launch(launchOptions)) {
}
If you want to select an element, you can do it with the .locator method. Then you can extract the text contents of it if you want. For example:
BrowserContext context = browser.newContext();
Page page = context.newPage();
page.navigate("https://playwright.dev/java/");
String title = page.locator(".hero__title").textContent();
System.out.println("Hero title: " + title);
context.close();
browser.close();
This code loads the Playwright site. Then it looks for the .hero__title CSS class and extracts its text. You can do anything you want with this variable. In our example, it's a simple print. However, you could manipulate it, save it to a DB, check it against other values, and so on.
You can click on elements using the.click() method after the locator, like this:
BrowserContext context = browser.newContext();
Page page = context.newPage();
page.navigate("https://playwright.dev/java/");
page.getByRole(AriaRole.BUTTON, new Page.GetByRoleOptions().setName("Search")).click();
page.screenshot(new Page.ScreenshotOptions().setPath(Path.of("screenshot-1.png")));
System.out.println("Screenshot taken");
context.close();
browser.close();
This code should save a screenshot with the search field highlighted:

Similarly, you can interact with form elements. Playwright’s Auto-waiting ensures the element is actionable before it attempts to type, making your web scraper much less likely to crash during UI transitions.
BrowserContext context = browser.newContext();
Page page = context.newPage();
page.navigate("https://playwright.dev/java/");
page.locator(".DocSearch-Button").click();
page.locator("#docsearch-input").fill("test");
page.screenshot(new Page.ScreenshotOptions().setPath(Path.of("screenshot-1.png")));
System.out.println("Screenshot taken");
context.close();
browser.close();
Here is the result:
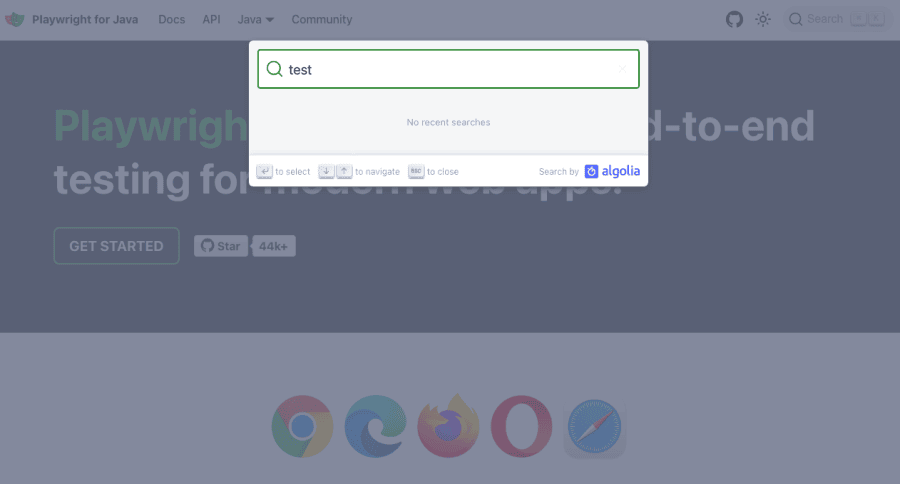
This is just a starting point. There are many other options in terms of locators, interactions, and mimicking user actions. You can do virtually anything a real user would do with Playwright Java.
Best Practices for Web Scraping in Java
To keep your web scraping in Java running smoothly, you should follow some rules. These help you stay out of trouble and get better data. Good habits make your web scraping more reliable over time.
- Respect robots.txt. Check for robots.txt, but also look for newer standards like ai.txt or llms.txt. Respecting these machine-readable files is a key signal of “good faith” for legal compliance under GDPR and CCPA.
- Throttle requests and use proxies. While you must avoid overwhelming a server, modern Java allows you to use Virtual Threads to manage hundreds of concurrent sessions efficiently. The key is to balance high throughput with a randomized human-like delay between actions.
- Logging and error handling. Keep track of what your web scraper is doing so you can fix it if it breaks.
- Structuring scraped data. Save your info in a clean format like JSON or CSV. It makes it easier to use in your other web scraping projects.
Common Java Errors
Here are some of the most common Java errors, and how you can fix them.
Must declare a named package eclipse because this compilation unit is associated to the named module.
Unless you are specifically building a modular Java application, the easiest fix is to delete the module-info.java file. It allows your Java project to use the “Classpath” instead of the “Modulepath”, ensuring Playwright and its dependencies are instantly visible to your code.
References to interface static methods are allowed only at source level 1.8 or above.
Like we've explored in the article, you can fix this under 'Project' (right click) > 'Properties' > 'Libraries' > Select the JRE of your Java project > 'Edit' > Select a different Java version (25 or 21 is good) > 'Finish' > 'Apply' and close.
If you don't see Java 21 as an option, you can download the latest JDK from vendors like Oracle or Adoptium.
import.">Playwright Proxy cannot be resolved to a type > import.
If you see this error in your project, make sure that you add this in the beginning of your file:
import com.microsoft.playwright.options.Proxy;
The error occurs because Java has its own built-in java.net.Proxy class. To avoid a name collision, you must explicitly import com.microsoft.playwright.options.Proxy at the top of your file to tell the compiler exactly which one to use.
Conclusion
You learned how to perform Java web scraping without getting blocked. We also explored many modern technologies you can use to get and process data for your business easily.
Playwright is a fantastic tool for scraping . There are many other options in terms of selectors, interactions, and data processing, but hopefully this was a good starting point.
FAQ
What are the alternatives for Java in web scraping?
Python is the go-to for data science and simple scripts due to libraries like BeautifulSoup. However, Node.js and Java are the leaders for high-concurrency scraping. Java specifically excels in enterprise environments where multi-threading and type safety are critical for long-running, large-scale operations.
Can Java scrape JavaScript-rendered content?
Yes, it can. You just need to use a Java library that can run a browser, like Playwright or Selenium. These tools create a Java object for the page after the JavaScript has finished loading. It’s the best way to do web scraping on modern sites.
Is web scraping with Java legal?
Web scraping publicly available data, like prices or stock levels, is generally legal. However, you must be careful with Personally Identifiable Information (PII). Under the EU's AI Act and GDPR, scraping public profiles or repurposing personal data without a clear legal basis can lead to heavy fines, even if the data isn't behind a login.

