'/%3e%3cellipse%20opacity='0.34'%20cx='327.5'%20cy='339'%20rx='264.5'%20ry='264'%20fill='url(%23paint1_linear_12724_35442)'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_12724_35442'%20x1='327'%20y1='-2.524e-06'%20x2='327'%20y2='389.286'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%2327D9E5'/%3e%3cstop%20offset='0.927406'%20stop-color='%23004047'%20stop-opacity='0'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_12724_35442'%20x1='328.02'%20y1='74.7771'%20x2='328.02'%20y2='395.312'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%2327D9E5'/%3e%3cstop%20offset='0.927406'%20stop-color='%23004047'%20stop-opacity='0'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)
How to Scrape Data from a Website to Excel: A Comprehensive Guide
News

Justas Palekas
Getting data directly from websites has become an easier task over time. Plenty of no-code and ready-made scraping solutions exist, and all they require you to do is input a URL. Some of them, however, are quite expensive, so for smaller projects it may be wiser to create a web scraping tool for yourself.
One of the hardest parts about web scraping is not procuring data, but making it understandable and readable. Websites are written in HTML so when you scrape data from them, you get a garbled mess of information.
Even if you can parse the information into a readable format, you’ll still need to move data to a format that’s better for analysis. It would be best, of course, if you could scrape data from a website to Excel in one fell swoop.
Is It Legal to Scrape Data?
Whether it’s legal to scrape data depends on the type of data and the procurement process. In general, publicly available (not hidden under a login or any other type of authorization) data is legal to scrape.
At least two caveats exist – copyrighted works and personal information. In both cases, even if they are publicly available, they are protected through a different set of legislation and scraping such data could cause issues.
Other parts of the scraping process (such as whether you scrape data from a website to Excel directly) play no part in legality. So, it’s almost always a question of availability and whether it’s protected under copyright or personal data law.
In any case, it’s highly recommended to speak to a legal professional before you scrape data from the web. While it’s unlikely that you’ll run into issues if you follow the above guidelines, it shouldn’t be taken as legal advice or a substitute for such.
Scraping Web Data into Excel
To scrape data from a website to Excel in one go, you have a few good options. Some no-code solutions may work if you’re willing to invest some money (or if a free web scraping trial is enough), but it’s almost always better to build data extraction tools yourself – as long as it’s not business-grade usage.
Using No-Code Tools
There are plenty of third-party solutions like DataScraper or Octoparse that allow you to perform data collection with just a few mouse clicks and settings. No Visual Basic Editor (or any other IDE) or programming language required.
While all of the solutions differ slightly, most will be paid at some point and restrict you on either the amount of clicks, amount of data collected, or other web scraping features. On the other hand, Excel is a well-known and highly popular data analysis tool, so almost every web scraping tool on the market will have exporting capabilities.
All of the no-code tools will slightly differ in how you export data to Excel, but for most, you can find direct guides on their website as the process is extremely popular.
Using Excel Power Query
If you want to scrape a website to Excel directly, Excel Power Query is a great option, as it exists directly in the software. No third party tools required, all you have to do is learn how to send Excel web queries.
We’ll run through a short Power Query tutorial so you can perform web scraping just by using Excel web queries, but be assured that the language and software is much more powerful than outlined here.
To start sending Excel web queries, open up a new sheet and click on the Data (1) tab.
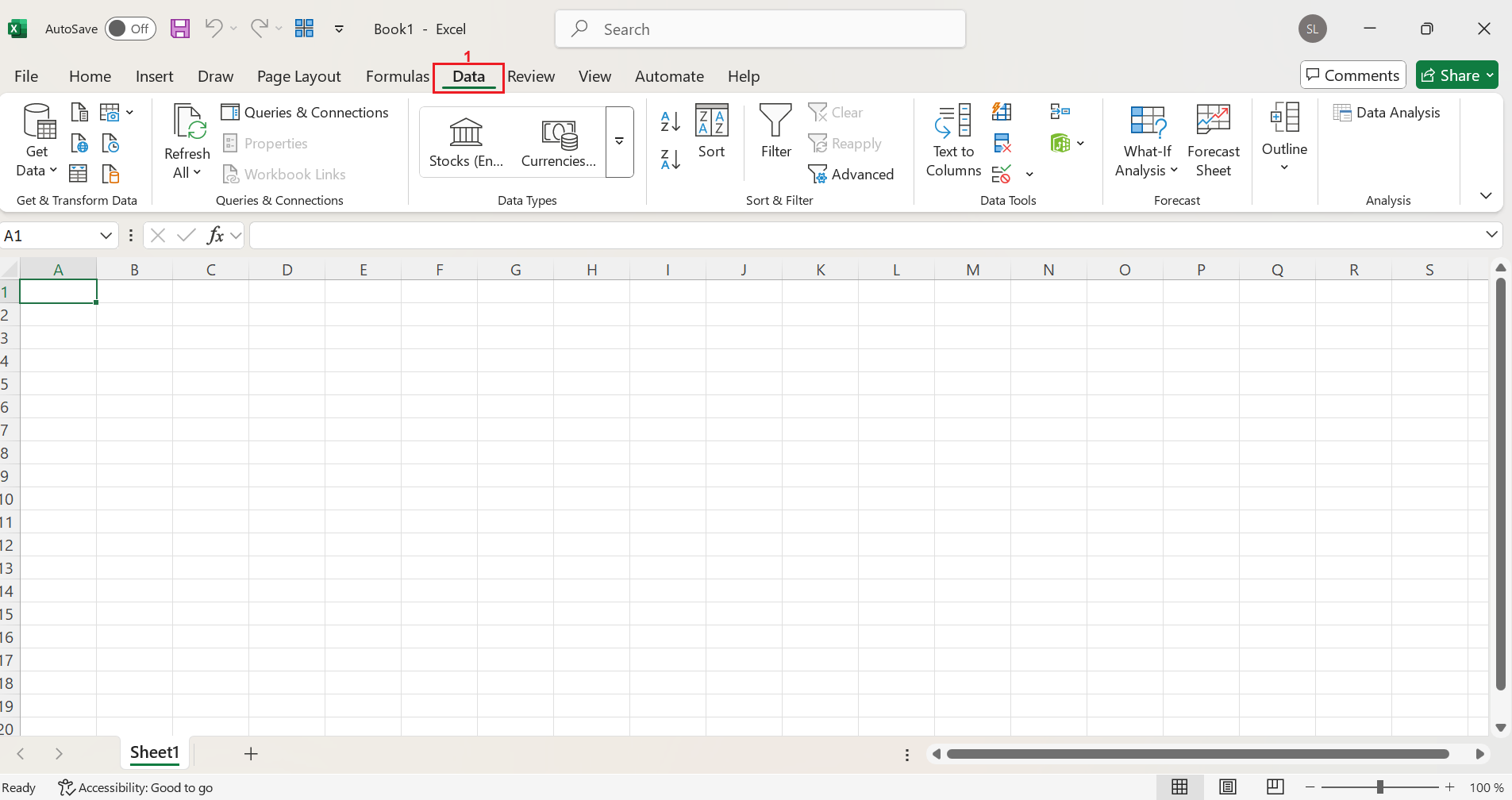
After that, there should be a Get Data (2) button at the left-hand side of the screen. Click on it, then select From Other Sources (3) and click on From Web (4) .
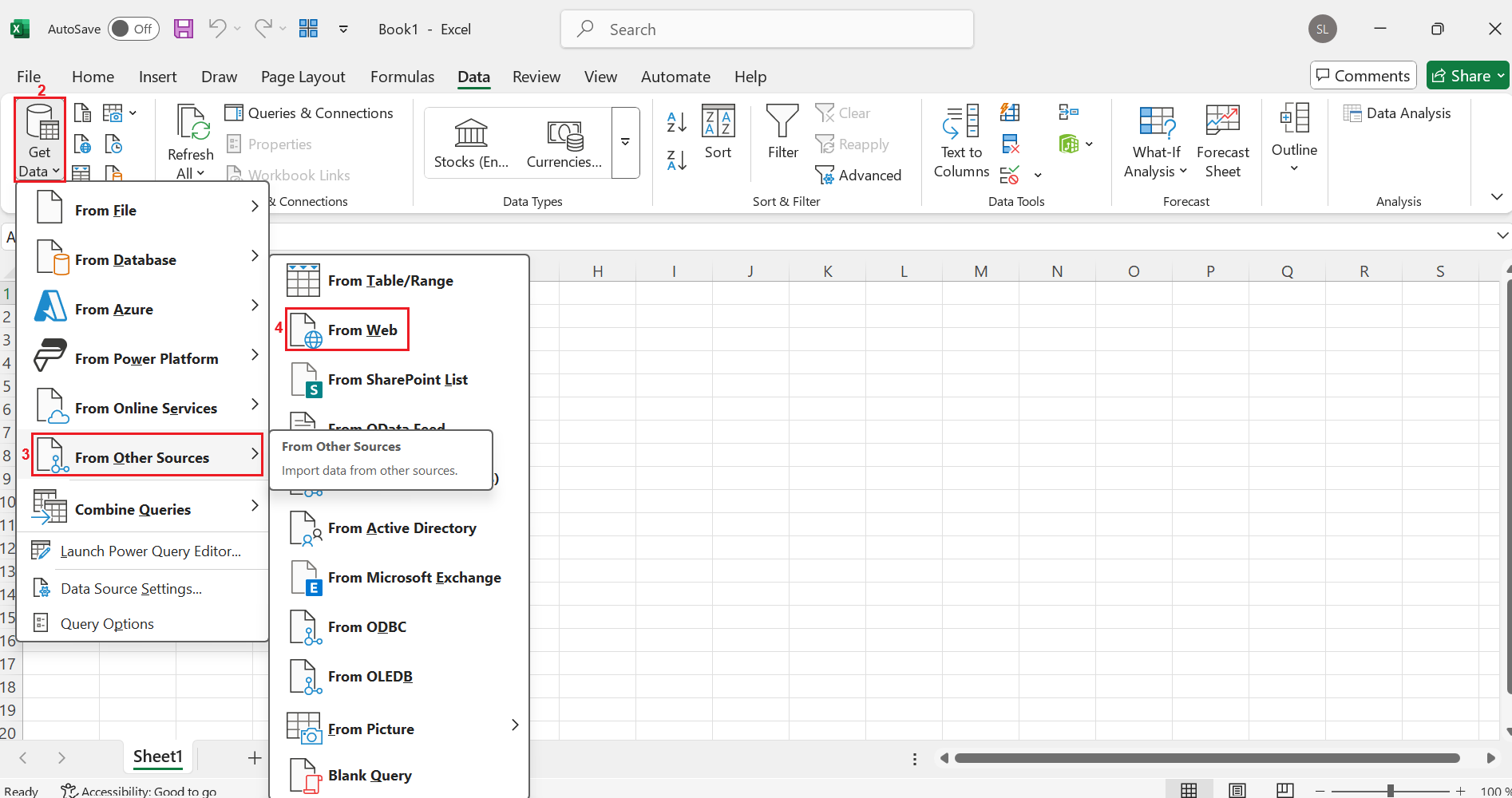
Then enter a URL such as “ https://en.wikipedia.org/wiki/Spreadsheet” (5) and click on OK (6) . Excel will send a web query and attempt to automatically load all possible tables.
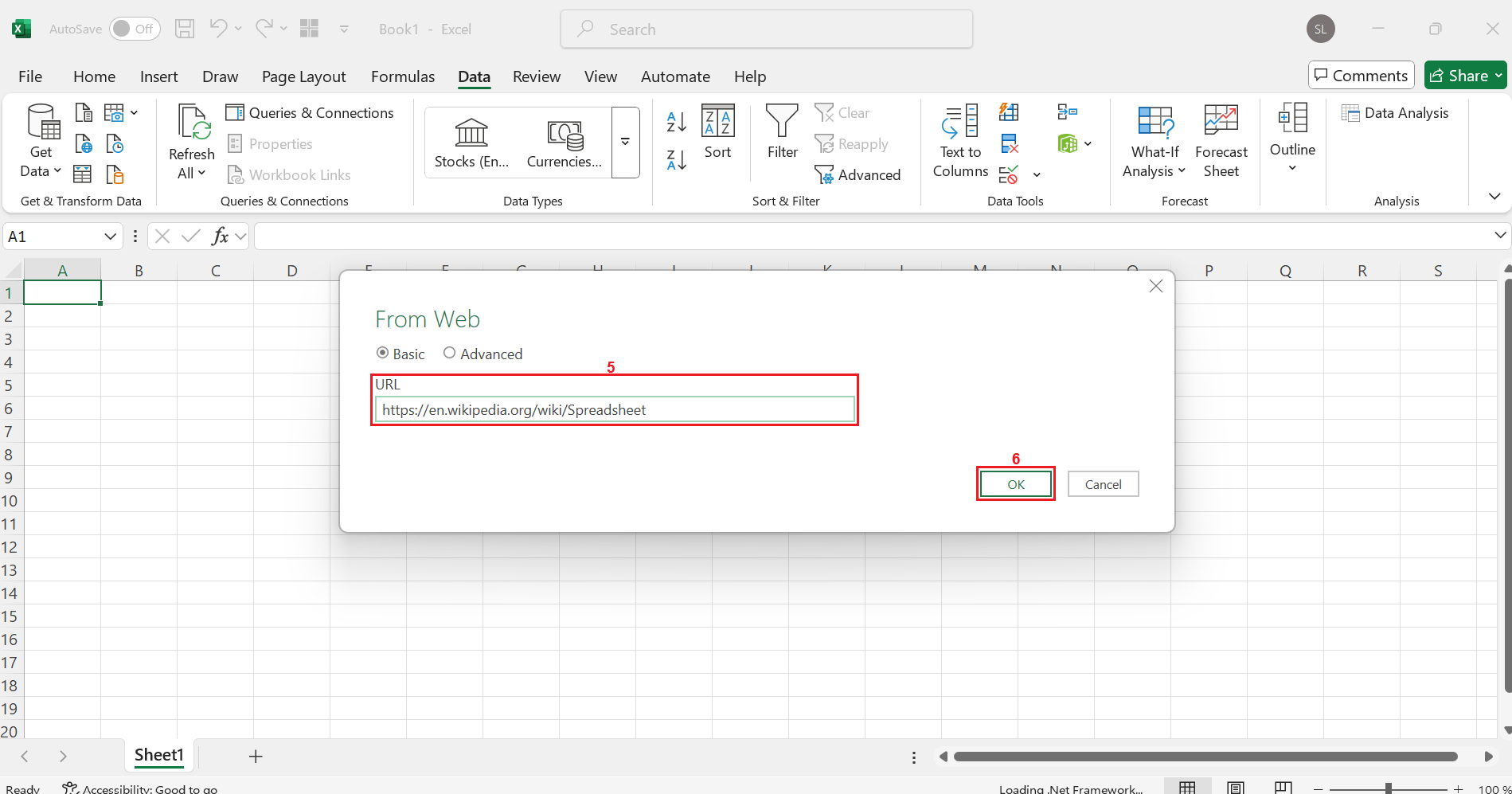
In many cases, some of the tables will be almost useless or contain irrelevant information. If the page does have a well-formatted table, you’ll be able to import it directly into your spreadsheet.
Run through the options and select the table you want inserted and click on Load .
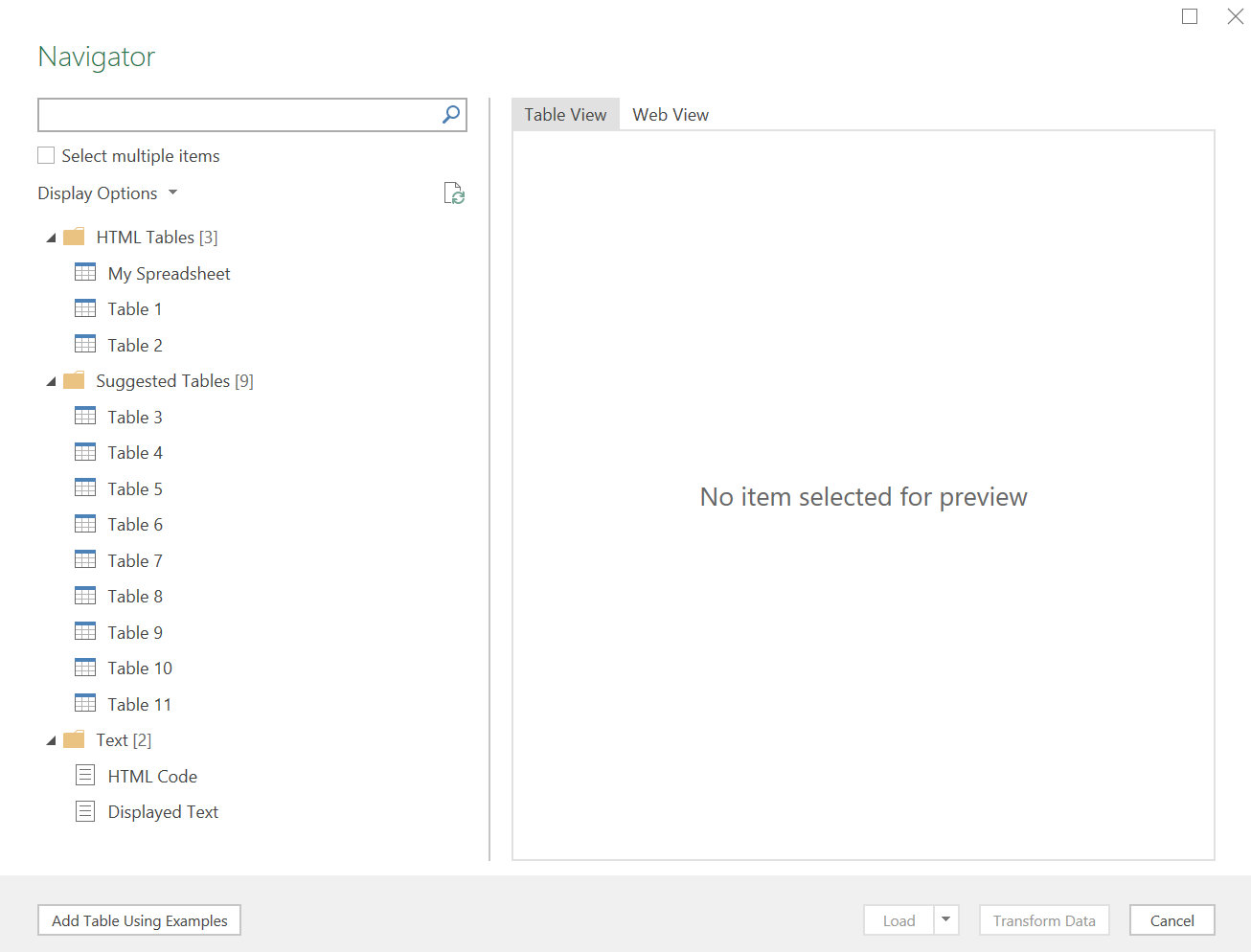
In a few seconds, the table will appear in your spreadsheet – directly from website to Excel in almost a single click.
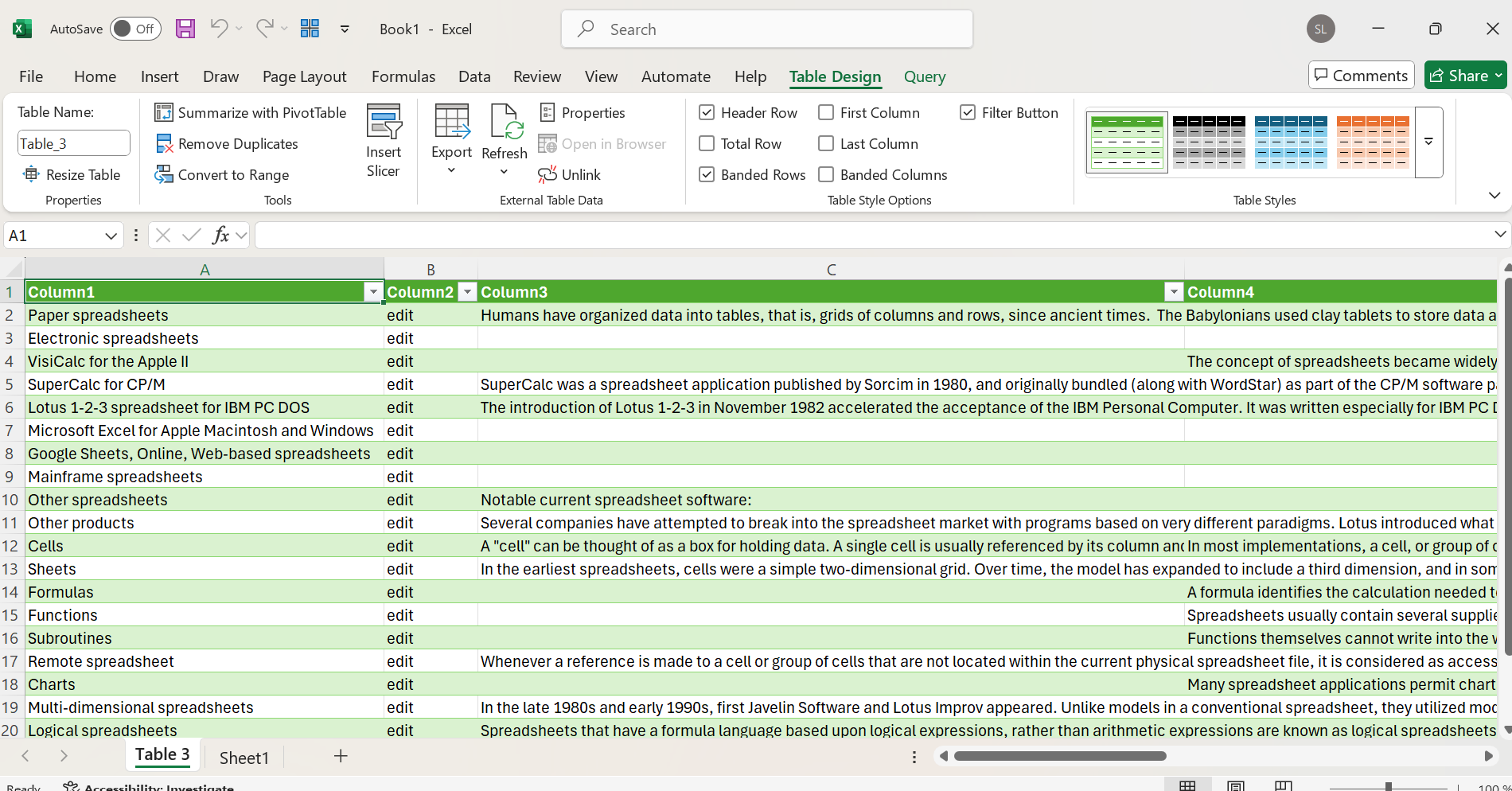
Using Excel VBA
While Power Query is a relatively simple tool that can be helpful when websites are formatted well, Visual Basic for Applications gives you full control over the way actions are performed, making it perfect for web scraping.
The VBA module is a little more hidden than Power Query. To open the menu, you’ll have to use the ALT + F11 keyboard combination. Doing so will bring up an entirely new screen.
Click on Insert and Module at the top of your screen. You’ll then have to create your own VBA code to perform web scraping:
Option Explicit
Sub ScrapeWikipediaTables()
Dim IE As Object
Dim HTMLDoc As Object
Dim tables As Object, table As Object
Dim rows As Object, row As Object
Dim cells As Object, cell As Object
Dim ws As Worksheet
Dim rowIndex As Long, colIndex As Long
' Create Internet Explorer object
Set IE = CreateObject("InternetExplorer.Application")
IE.Visible = False
' Navigate to the desired webpage
IE.Navigate "https://en.wikipedia.org/wiki/Help:Table"
Do While IE.Busy Or IE.ReadyState <> 4
DoEvents
Loop
' Get the HTML document
Set HTMLDoc = IE.Document
' Set your worksheet
Set ws = ThisWorkbook.Sheets(1)
rowIndex = 1
' Get all tables on the page
Set tables = HTMLDoc.getElementsByTagName("table")
For Each table In tables
' Get all rows in the table
Set rows = table.getElementsByTagName("tr")
For Each row In rows
colIndex = 1
' Get all cells in the row (both <td> and <th>)
Set cells = row.getElementsByTagName("th")
For Each cell In cells
ws.Cells(rowIndex, colIndex).Value = cell.innerText
colIndex = colIndex + 1
Next cell
Set cells = row.getElementsByTagName("td")
For Each cell In cells
ws.Cells(rowIndex, colIndex).Value = cell.innerText
colIndex = colIndex + 1
Next cell
rowIndex = rowIndex + 1
Next row
' Add a blank row between tables
rowIndex = rowIndex + 1
Next table
' Close IE and clean up
IE.Quit
Set IE = Nothing
MsgBox "Data Scraping Complete!"
End Sub
Above is a sample web scraping script which creates an Internet Explorer object that visits Wikipedia’s “Help:Table” section. Then the web scraping script downloads the HTML file of the site while setting your input worksheet as the first one on your list.
After that the script finds all elements tagged “table” and runs several “for” loops. The outermost is for all of the tables found, and the innermost go through each row and add it to the cell.
Finally, IE is closed and a message box is displayed.
Note that while it does capture a lot of data, lots of it is irrelevant. Pages like “Help:Table” are a great way to train your web scraping skills to only capture what’s necessary.
Using Python
Python is often the go-to programming language for web scraping as it combines efficiency, simplicity, and community support in one go. Many of the third-party web scraping solutions are written in Python, so learning the ropes can go a long way in helping you create your own script.
But you’ll have to move out of Excel and into an IDE (such as PyCharm). For a broader overview on Python web scraping , we have a more in-depth guide that should help even complete beginners begin web scraping.
In your IDE, create a Python file and install the most popular scraping and Excel-related libraries:
pip install requests beautifulsoup4 openpyxl
Requests will be used to access the website, Beautiful Soup 4 will help us search through the data, and openpyxl is used to output data to Excel.
Here’s the full code block:
import requests
from bs4 import BeautifulSoup
import openpyxl
import re
# Create Excel workbook
wb = openpyxl.Workbook()
sheet = wb.active
sheet.title = "Spreadsheet Software"
# Target URL
url = "https://en.wikipedia.org/wiki/List_of_spreadsheet_software"
response = requests.get(url)
soup = BeautifulSoup(response.content, "html.parser")
# Extract list of spreadsheet software
software_list = []
content_div = soup.find("div", {"id": "bodyContent"})
if content_div:
ul_elements = content_div.find_all("ul")
for ul in ul_elements:
li_elements = ul.find_all("li")
for li in li_elements:
# Extract text and remove junk with regex: sequence of capitalized words with spaces
match = re.match(r'([A-Z][a-zA-Z0-9]*(\s[A-Z][a-zA-Z0-9]*)*)', li.get_text(strip=True))
if match:
clean_name = match.group(0).strip()
if clean_name and clean_name not in software_list:
software_list.append(clean_name)
# Write to Excel
for idx, software in enumerate(software_list, start=1):
sheet.cell(row=idx, column=1, value=software)
# Save Excel file
wb.save("cleaned_spreadsheet_software.xlsx")
print("Spreadsheet software list successfully saved to cleaned_spreadsheet_software.xlsx")
We’ll start by creating an Excel workbook and sheet. Our web scraping script will then visit the Wikipedia page that lists all popular spreadsheet software.
It’ll then find the body content and every list (tagged “ul”) and list element (tagged “li”). Then comes the hardest part in web scraping – parsing the information in such a way that you only get what’s valuable. Otherwise you’d get not just the names but the long descriptions as well.
Regular expressions are often used for such complicated tasks and even the current iteration is not perfect, although it captures almost all list items correctly.
Finally, the list is created and the values appended wherein it is later exported to Excel.
Even if Python does look quite a bit more complicated, it’s definitely the most powerful option for scraping. Knowing and being able to use the other options also helps, but no one that’s deeply interested in scraping should be passing up on Python.


