How To Scrape Product Hunt
Tutorials

Milena Popova
Product Hunt is a platform for discovering and sharing new and innovative products, services, and technologies. It hosts a community of creators and entrepreneurs who showcase their latest projects and startups. Product Hunt users can browse a wide range of categories, upvote their favorite products, and engage in discussions with the makers.
By scraping the website, you can access valuable information about trending projects. In this tutorial, you’ll learn how to scrape the top products of a category in Product Hunt using tools like Python, Playwright, and Beautiful Soup.
What Are the Benefits of Scraping Data From Product Hunt for Market Research and Product Analysis?
Product Hunt provides real-time insights into what is trending at the moment. You can use this information to gain knowledge about the current state of the startup market, gather some cool ideas for your next startup, or learn what to do to rank highly on the platform yourself.
How Can Python Libraries Like Beautiful Soup Assist in Scraping Data From Product Hunt?
Python libraries like Beautiful Soup and Playwright can be extremely helpful in scraping data from Product Hunt and other similar websites.
Beautiful Soup is a powerful parsing library that can be used for finding data that you need. When used in combination with other libraries that fetch data from the webpage, it can provide a custom web scraping solution.
For scraping interactive websites like Product Hunt, you can combine Beautiful Soup with a browser automation tool like Playwright . This enables you to interact with the JavaScript elements in the user interface while still making use of the powerful parsing capabilities of Beautiful Soup.
In the tutorial below, you’ll learn how to combine these libraries to create a web scraper for Product Hunt.
How to Scrape Product Hunt With Playwright and Beautiful Soup
In this tutorial, you’ll learn how to scrape the best products of a category in Product Hunt. As an example, the tutorial will scrape the products off the Engineering & Development category, but the code can be used for any other category with minimal adjustments.
Setup
To follow the tutorial, you’ll need to have Python installed on your computer. If you don’t already have it, you can use the official instructions to download and install it.
You’ll also need to install Playwright and Beautiful Soup. Use the following commands to install the libraries and the browser engines that Playwright needs.
pip install playwright
pip install bs4
playwright install
Opening a Page With Playwright
To start scraping a page with Beautiful Soup, you first need to download it using Playwright.
First, create a new Python file and import the necessary libraries:
from playwright.sync_api import sync_playwright
from bs4 import BeautifulSoup
import time
Then paste in the following boilerplate for opening a website:
with sync_playwright() as pw:
browser = pw.chromium.launch(
headless=False,
)
url = 'https://www.producthunt.com/categories/engineering-development'
page = browser.new_page()
page.goto(url)
This will open the Engineering & Development section of Product Hunt products.

Currently, the page only contains 10 products. To get access to more products, you can use the interactivity functionality available in Playwright to click the “Show More” button a couple of times.
Here’s the code that can do that:
for n in range(0, 5):
show_more = page.get_by_text('Show more')
show_more.click()
time.sleep(1)
It will click the Show More button five times, waiting one second between each click for the products to load.
Scraping the Page With Beautiful Soup
Now that the page is loaded and prepared, you can parse its HTML with Beautiful Soup. Even though Playwright has built-in parsing capabilities, using Beautiful Soup is more handy and intuitive for web scraping projects.
First, run the website’s HTML through the HTML parser. This will create an object that you can later query for elements you need.
soup = BeautifulSoup(page.content(), 'html.parser')
After that, you want to select all the individual product cards on the page.
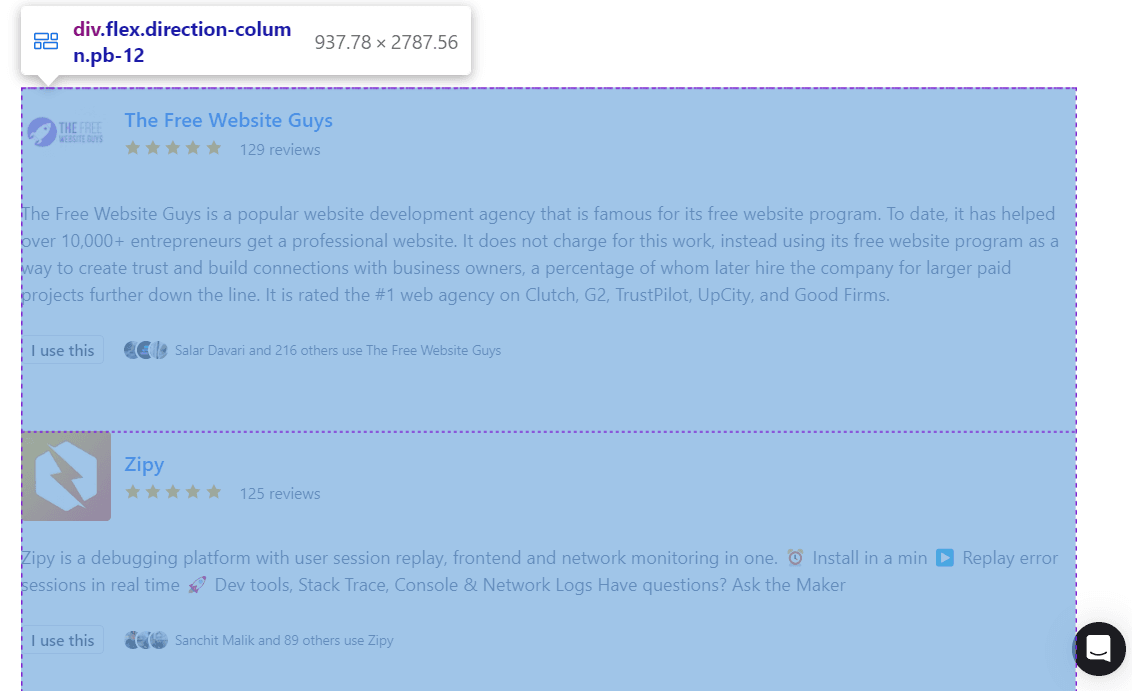
One of the ways to do that is to select the element containing all the information and then find all its first-level children.
data = soup.select_one('.flex.direction-column.pb-12')
cards = data.findChildren('div', recursive=False)
After you have selected all the product cards, iterate over them to find the name, link, and description of the product.
products = []
for card in cards:
title_element = card.select_one('a > div').parent
title = title_element.text
link = title_element['href']
description = card.select_one('div.mb-6').text
product = {'title': title, 'link': link, 'description': description}
products.append(product)
Finally, print the products to the console and close the browser.
print(products)
browser.close()
Here’s the full code for convenience:
from playwright.sync_api import sync_playwright
from bs4 import BeautifulSoup
import time
with sync_playwright() as pw:
browser = pw.chromium.launch(
headless=False,
)
url = 'https://www.producthunt.com/categories/engineering-development'
page = browser.new_page()
page.goto(url)
for n in range(0, 5):
show_more = page.get_by_text('Show more')
show_more.click()
time.sleep(1)
soup = BeautifulSoup(page.content(), 'html.parser')
data = soup.select_one('.flex.direction-column.pb-12')
cards = data.findChildren('div', recursive=False)
products = []
for card in cards:
title_element = card.select_one('a > div').parent
title = title_element.text
link = title_element['href']
description = card.select_one('div.mb-6').text
product = {'title': title, 'link': link, 'description': description}
products.append(product)
print(products)
browser.close()
Running the code should return a result like this:
[{'title': '', 'link': '/products/the-free-website-guys', 'description': 'The Free Website Guys is a popular website development agency that is famous for its free website program. To date, it has helped over 10,000+ entrepreneurs get a professional website. It does not charge for this work, instead using its free website program as a way to create trust and build connections with business owners, a percentage of whom later hire the company for larger paid projects further down the line.\n\nIt is rated the #1 web agency on Clutch, G2, TrustPilot, UpCity, and Good Firms.'}, …]
Are There Any Challenges or Limitations When Scraping Data From Product Hunt?
Product Hunt is a very simple website, so scraping data from Product Hunt isn’t as challenging as scraping services like Amazon that have powerful anti-scraping solutions in place or very JavaScript-heavy pages like Glassdoor.
Still, Product Hunt receives a lot of clicks every day, some of which are definitely by automated computer programs trying to scrape enough data to analyze the state of the startup market. For this reason, Product Hunt definitely has measures for users who try to scrape large-scale datasets such as user comments on individual products.
Additionally, any computer program that will access the web in an automated fashion and forget to add the appropriate amount of pauses between requests is very likely to get flagged and suspended, if only for a brief time.
To avoid this, it’s important to use proxies while scraping the web. Proxies act as middlemen between you and the server you’re accessing. They take your request and forward it, making it seem like it originated from the proxy provider and not your own IP address.
A quality proxy provider like IPRoyal residential proxies will provide a pool of ethically sourced IPs from around the world, enabling you to have a different IP address with every web request you make to help you hide your web scraping activities.
Using Proxies to Prevent IP Bans & Suspensions
Here’s how you can use proxies to prevent Product Hunt from suspending your IP address for accessing its website with an automated scraping program.
First, you need the server, username, and password information of your proxy server.
If you’re using IPRoyal proxies, you can find it in your dashboard. To get the server variable, concatenate the host and port fields.
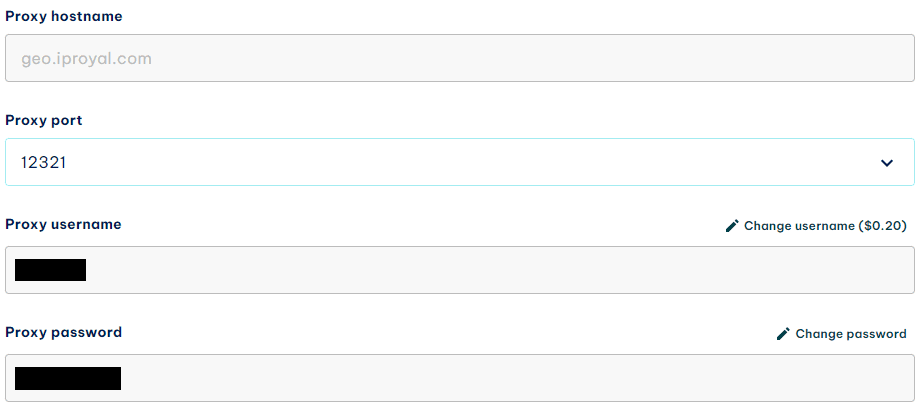
Then, update the chromium.launch() function in your code:
browser = pw.chromium.launch(
headless=False,
proxy={
'server':'host:port',
'username':'username',
'password': 'password123',
}
)
Now, all the requests will be ported through the proxy of your choice and you won’t have to worry about the website detecting your scraping.
What Types of Data Can Be Scraped From Product Hunt?
Product Hunt provides many different kinds of data about the products uploaded on the website.
Product information: You can scrape details about the products listed on Product Hunt, including their names, descriptions, URLs, and categories.
Ratings and reviews: You can scrape ratings and reviews made by the users of the products.
Product images and videos: You can scrape product images, screenshots, and videos that are associated with the listed products.
User profiles: Information about Product Hunt users, such as their usernames, profiles, and the products they've submitted or upvoted.
Comments and discussions: You can scrape comments and discussions related to products, including user comments, replies, and any discussions that occur on the platform.
Trending and featured products: You can scrape information on what products are currently trending or being featured on the platform.
How Can Scraped Data From Product Hunt Be Used to Gain Insights Into Trending Products?
Scraped data from Product Hunt can be valuable for gaining insights into trending products, helping individuals and businesses make informed decisions. Here's how you can use this data to gain insights into trending products:
Identify popular product categories: Analyze the categories or tags associated with trending products to understand which product categories are currently popular. This can help you identify industry trends and consumer preferences.
Track user engagement: Monitor user engagement metrics like upvotes, comments, and shares to gauge the popularity of your or your competitors’ products.
Analyze product descriptions: Analyze the descriptions and features of trending products to understand what makes them appealing to users. This can provide insights into the key selling points and trends in product development that can be useful for developing your own products.
Analyze product success: Analyze user reviews and ratings to gauge user satisfaction with the product. High ratings and positive reviews are indicators of a successful product.
Analyze product growth: Track how a product's popularity changes over time. This will enable you to discern products that provide lasting value to the users in contrast to products that are a flash in the pan.
Find influential users: Identify influential users who consistently post or upvote trending products. This can help you discover early adopters and trendsetters in your industry.
Competitive analysis: Study the competition by analyzing trending products from competitors. This can help you assess your strengths and weaknesses compared to similar products.
Predict future trends: By understanding the current trends and factors driving their popularity, you can make predictions about future trends and adjust your product development or marketing strategies accordingly.
Gather data for content creation: Use the information to create content such as blog posts, social media updates, or videos about trending products. This can attract an audience interested in the latest trends.
Conclusion
By using common web scraping tools like Beautiful Soup and Playwright, you can easily scrape many kinds of data from Product Hunt for market and competitor analysis and analyze the trending products globally and in each category.
Coupled with the use of proxies, these libraries provide a complete solution for scraping any kind of dataset from the website and websites like these.
To read more practical articles about web scraping, check out IPRoyal’s blog . It contains everything you need to both start out doing web scraping and advance your skills to pull off bigger projects.
FAQ
Is web scraping data from Product Hunt allowed according to their terms of service?
Web scraping is prohibited by the terms of service of Product Hunt. They expressly prohibit using services in a manner that “crawls,” “scrapes,” or “spiders” any page, data, or portion of or relating to the Services or Content (through use of manual or automated means);”
However, since product information is publicly accessible information, you probably can scrape this information without any legal repercussions. All you need to do is to not be logged in during scraping as that would amount to accepting the terms of service.
Can I scrape product names, descriptions, and upvote counts from Product Hunt?
Yes, that’s definitely possible. Check out our tutorial above to see an example of how it might be done using Python-based tools like Beautiful Soup and Playwright.
Are there any rate limits or IP blocking measures in place for scraping data from Product Hunt?
As with any large website, Produc tHunt employs rate limits to prevent large-scale scraping of the website. For this reason, it’s important to use proxies that hide the original IP address of the request and let you hide your web scraping activity.
Good quality services like IPRoyal residential proxies will provide a pool of rotating proxies that will enable you to make every request to the website with a different IP address.

