'/%3e%3cellipse%20opacity='0.34'%20cx='327.5'%20cy='339'%20rx='264.5'%20ry='264'%20fill='url(%23paint1_linear_12724_35442)'/%3e%3cdefs%3e%3clinearGradient%20id='paint0_linear_12724_35442'%20x1='327'%20y1='-2.524e-06'%20x2='327'%20y2='389.286'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%2327D9E5'/%3e%3cstop%20offset='0.927406'%20stop-color='%23004047'%20stop-opacity='0'/%3e%3c/linearGradient%3e%3clinearGradient%20id='paint1_linear_12724_35442'%20x1='328.02'%20y1='74.7771'%20x2='328.02'%20y2='395.312'%20gradientUnits='userSpaceOnUse'%3e%3cstop%20stop-color='%2327D9E5'/%3e%3cstop%20offset='0.927406'%20stop-color='%23004047'%20stop-opacity='0'/%3e%3c/linearGradient%3e%3c/defs%3e%3c/svg%3e)
How to Scrape TikTok Data: A Complete Guide
WebsitesLearn how to scrape TikTok videos and user profiles using a Python web scraper with Playwright while navigating legal pitfalls and common challenges in TikTok scraping.


Marijus Narbutas
Key Takeaways
-
TikTok hosts a wealth of publicly available data used for marketing, competitor, and influencer research.
-
Most basic TikTok scrapers can work with Beautiful Soup, Nodriver, and Requests.
-
Advanced TikTok scraping techniques include using quality proxies, Playwright, and various third-party CAPTCHA solvers and signature generators.
TikTok scraping projects are some of the most difficult due to layers of advanced, adaptive, and frequently changing anti-scraping measures. It’s a truly advanced web scraping target with most TikTok scrapers and guides getting outdated every few months or so.
If you’re up for the challenge, the best approach is to focus on the essential steps and tested strategies to scrape TikTok. Overcoming novel barriers, such as cryptographic headers, will require you first to get the fundamentals of scraping TikTok profile pages.
Why Scrape TikTok?
With 1.5 billion monthly active users, TikTok is one of the world’s largest social media platforms. Despite common stereotypes, TikTok’s audience reaches beyond just Gen Z users, also catering to millennials and even some Gen X. Unsurprisingly, web scraping TikTok unlocks a variety of business use cases.
- Marketing analytics. If TikTok is one of your marketing channels, scraping TikTok is a must when measuring your campaign reach and effectiveness. TikTok data is also invaluable for related tasks like sentiment analysis, competitor campaign monitoring, and others.
- Trend tracking. Identify emerging topics, content formats, and other trends before they get mainstream. With web scraping, our channel or campaigns can benefit from early adopter advantages and jump on the next trend in time.
- Influencer research. Hiring influencers is easier when you can do your own research about their engagement metrics and authenticity. Scraping TikTok is also crucial for protecting against fraudulent influencers who built their following with fake accounts.
- Performance insights. TikTok data is crucial for understanding what drives user engagement in niches you are trying to enter. You can analyze TikTok video data, for example, to improve the performance of your own campaigns.
Is It Legal to Scrape TikTok?
While courts in the USA and elsewhere have ruled that web scraping publicly accessible data is legal, TikTok’s Terms of Service explicitly prohibit automated data collection. So, TikTok scraping falls within a legally gray area depending on the data type and its intended use.
TikTok videos, pages, comments, like counts, and other data accessible without login are fair targets for web scraping. It might be true according to TikTok rules if you scrape TikTok for research or other non-commercial use cases.
Some data, even if in allowed paths by TikTok’s robots.txt, can be copyrighted by TikTok or its users or protected as Personally Identifiable Information (PII). In such cases, web scraping or distributing such TikTok user data can violate laws.
In all cases, you’ll still face restrictions like CAPTCHA, rate limits, or even IP bans. Non-restricted alternatives include using the official TikTok API that grants access for authorized users. Gaining such access ain’t easy, so, for a small-scale research project, it’s easier to build a Python scraper.
Laws and platform policies vary by region and use case, so if you have doubts about the legality of scraping TikTok, seek advice from a qualified legal professional and do not take this blog post as a substitute for professional commentary.
How to Scrape TikTok Data Using Python
Prerequisites for TikTok Data Scraping
Before starting, ensure you have Python 3.8 or newer installed. For scraping TikTok profile pages, we can make do with these Python libraries.
- Beautiful Soup. An HTML parser for extracting data from web pages by navigating the HTML tree. Used in most Python web scraping projects.
- Nodriver. A stealth browser automation library that is better at bypassing TikTok’s anti-scraping attempts than more common tools like Selenium.
- Requests. One of the most popular Python web scraping libraries for simple synchronous requests.
All these libraries can be installed with the following pip command:
pip install nodriver beautifulsoup4 requests
Note that a larger TikTok scraping project might require scraping multiple profiles concurrently, and we're simplifying things here for demonstration purposes. Consider adding asynchronous libraries like asyncio and aiohttp to improve performance by handling multiple requests simultaneously.
TikTok Scraper for JSON Extraction
The most reliable way to scrape TikTok profiles is to access embedded data within the <script> tag. TikTok pages contain a script tag with ID SIGI_STATE or UNIVERSAL_DATA_FOR_REHYDRATION that holds JSON data for the entire page. This includes the data for usernames, followers, and like counts that we’re after.
Such an approach helps us to extract JSON and parse it directly from the page source without needing to interact with API responses or bypass many of the advanced anti-scraping methods. Here’s what the code might look like.
import nodriver as uc
from bs4 import BeautifulSoup
import json
import asyncio
import warnings
import sys
import os
async def scrape_tiktok_profile_json(username):
"""
Scrape TikTok profile data by extracting embedded JSON from the profile page.
Args:
username: TikTok username without @ symbol
Returns:
dict: Profile data containing username, followers, and likes
None: If scraping fails
"""
browser = None
try:
print(f"Starting scrape for @{username}...")
browser = await uc.start(headless=False)
print("Browser started successfully")
page = await browser.get(f"https://www.tiktok.com/@{username}")
print(f"Loaded profile page for @{username}")
await asyncio.sleep(5)
html_content = await page.get_content()
print(f"Retrieved HTML content ({len(html_content)} characters)")
soup = BeautifulSoup(html_content, 'html.parser')
script_tag = soup.find('script', {'id': '__UNIVERSAL_DATA_FOR_REHYDRATION__'})
if not script_tag:
script_tag = soup.find('script', {'id': 'SIGI_STATE'})
if script_tag:
json_text = script_tag.string
data = json.loads(json_text)
try:
if '__DEFAULT_SCOPE__' in data:
user_info = data['__DEFAULT_SCOPE__']['webapp.user-detail']['userInfo']
elif 'UserModule' in data:
user_info = list(data['UserModule']['users'].values())[0]
else:
print("Unknown JSON structure")
print("Available keys:", list(data.keys()))
return None
profile_data = {
'username': user_info['user']['uniqueId'],
'followers': user_info['stats']['followerCount'],
'likes': user_info['stats']['heartCount']
}
print("Successfully extracted data from JSON")
return profile_data
except (KeyError, IndexError) as e:
print(f"Error parsing JSON structure: {e}")
return None
else:
print("No JSON script tag found")
return None
except Exception as e:
print(f"Error during scraping: {e}")
import traceback
traceback.print_exc()
return None
finally:
if browser:
browser.stop()
print("Browser closed")
async def main():
"""Main entry point to properly handle async context."""
profile = await scrape_tiktok_profile_json("iproyal_cz")
if profile:
print("\n=== Profile Data ===")
print(f"Username: @{profile['username']}")
print(f"Followers: {profile['followers']:,}")
print(f"Likes: {profile['likes']:,}")
else:
print("\nFailed to retrieve profile data")
return profile
if __name__ == "__main__":
warnings.filterwarnings("ignore")
sys.stderr = open(os.devnull, 'w')
try:
asyncio.run(main())
finally:
sys.stderr = sys.__stderr__
Adding Proxies to Your TikTok Scraper
You'll likely need to access more than a few TikTok users with your scraper. Without a proxy, IP-based blocking and detection are almost impossible to avoid. We'll be using IPRoyal's residential proxies that use Chicago-based IPs to route your traffic for this task.
Refer to the quick-start guide when purchasing and setting up your proxies. In short, the credentials for proxy authentication can be found in the dashboard.
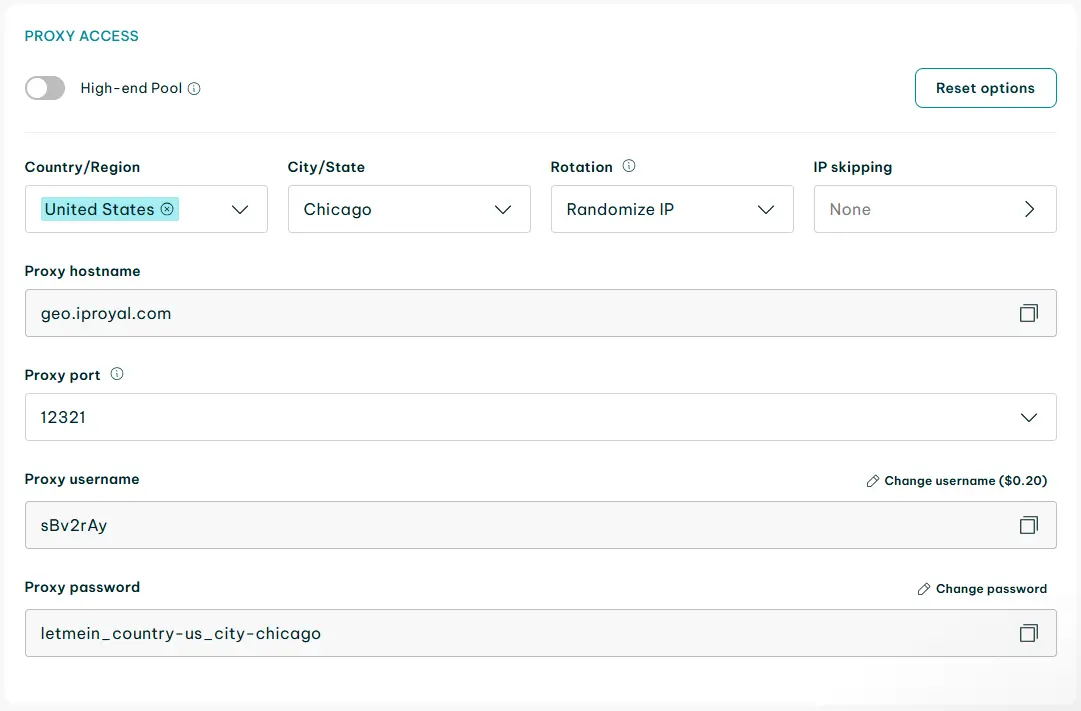
To add proxy support, we'll need to modify the browser configuration that our previous Nodriver TikTok scraper uses. Here's what an authenticated proxy configuration might look like.
# Configure browser with authenticated proxy
proxy_host = "geo.iproyal.com"
proxy_port = 12321
proxy_username = "sBv2rAy"
proxy_password = "letmein_country-us_city-chicago"
# Build proxy server URL
proxy_server = f"http://{proxy_host}:{proxy_port}"
# Browser configuration with proxy authentication
browser_config = {
'headless': True,
'proxy_server': proxy_server,
'proxy_username': proxy_username,
'proxy_password': proxy_password
}
# Start browser with proxy settings
browser = uc.start(**browser_config)
print(f"Browser started with proxy: {proxy_host}:{proxy_port}")
TikTok Data Structure
Using embedded JSON might not always work. If you're scraping TikTok frequently, you'll notice that its extraction might fail due to page structure changes or loading issues. To avoid complications, we need a fallback method that extracts TikTok user data directly from HTML elements. First, we need to find relevant attributes.
- Open the TikTok profile page in a browser, preferably Chrome.
- Right-click and choose Inspect to open DevTools.
- Use the element selector (top-left icon in DevTools) to hover over profile elements.
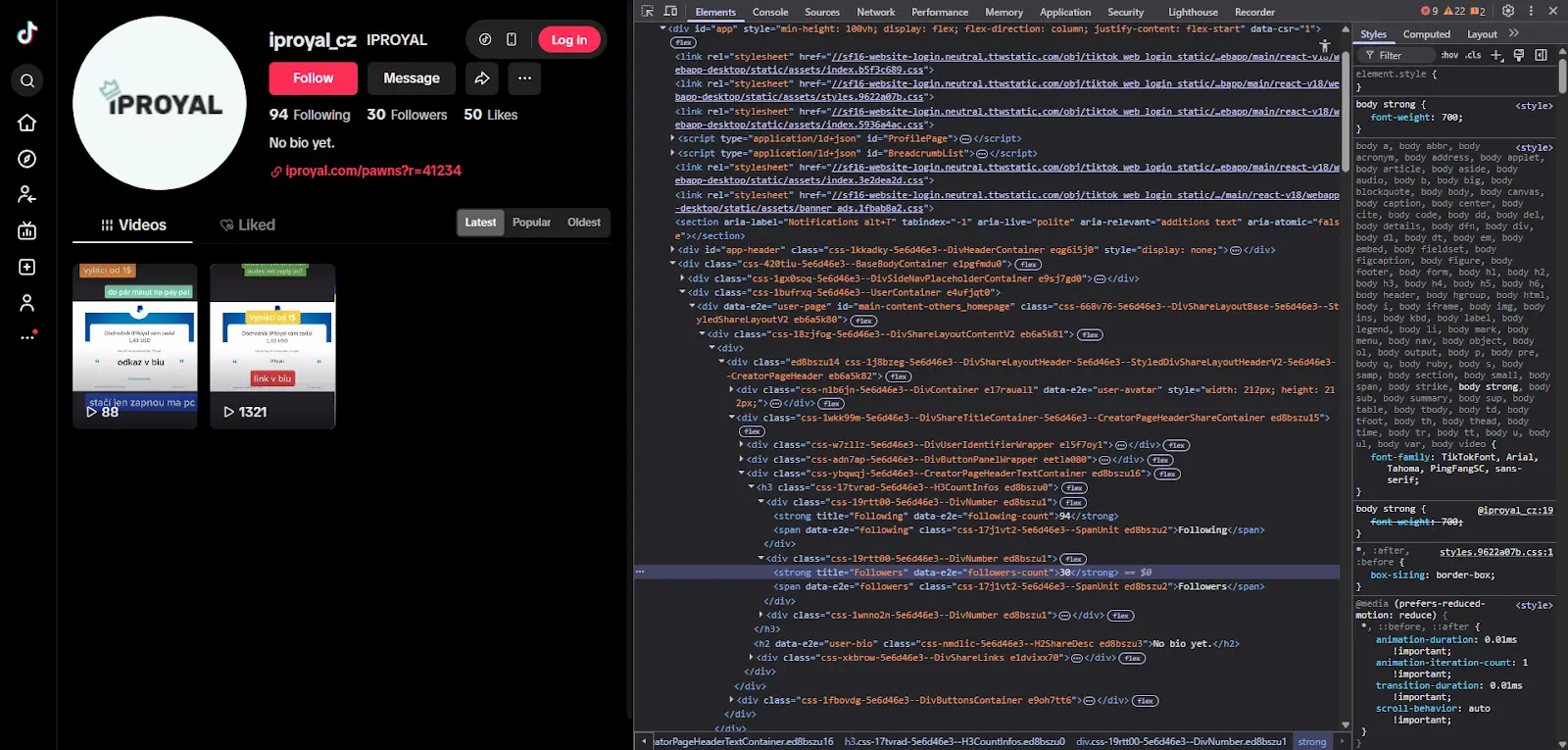
Here are the most common attributes to look for when inspecting TikTok profile pages with DevTools. We'll be using the top three for our TikTok scraper.
- Username:
<h1 data-e2e="user-title">iproyal_cz</h1> - Followers:
<strong data-e2e="followers-count">30,<strong> - Likes:
<strong data-e2e="likes-count">94</strong> - Following:
<strong data-e2e="following-count">567</strong> - Display Name:
<h2 data-e2e="user-subtitle">Display Name</h2> - Bio:
<h2 data-e2e="user-bio">Profile bio text</h2>
Building a Fallback Strategy
Now that we know the relevant data-e2e attributes, we can leave the JSON extraction as the primary method, but if it fails, use HTML attributes. Here’s how the fallback code might look.
# Fallback to HTML attribute extraction
print("Using HTML attribute extraction...")
def safe_extract(selector, attribute='data-e2e'):
"""Safely extract text from element"""
element = soup.select_one(f'[{attribute}="{selector}"]')
return element.text.strip() if element else 'N/A'
profile_data = {
'username': safe_extract('user-title'),
'followers': safe_extract('followers-count'),
'likes': safe_extract('likes-count')
}
print("Successfully extracted data from HTML attributes")
The safe_extract() function searches for TikTok profile elements with specific data-e2e attributes. If no element is found, it returns 'N/A'. Here's how the complete web scraping script for TikTok profiles with proxy integration and fallback might look.
import nodriver as uc
from bs4 import BeautifulSoup
import json
import asyncio
import warnings
import sys
import os
async def scrape_tiktok_profile(username):
"""
Scrape TikTok with JSON extraction and HTML fallback using authenticated proxy
Args:
username: TikTok username without @ symbol
Returns:
dict: Profile data containing username, followers, and likes
None: If scraping fails
"""
browser = None
try:
print(f"Starting scrape for @{username}...")
proxy_host = "geo.iproyal.com"
proxy_port = 12321
proxy_username = "sBv2rAy"
proxy_password = "letmein_country-us_city-chicago"
proxy_server = f"http://{proxy_host}:{proxy_port}"
browser_config = {
'headless': True,
'proxy_server': proxy_server,
'proxy_username': proxy_username,
'proxy_password': proxy_password
}
browser = await uc.start(**browser_config)
print(f"Browser started with proxy: {proxy_host}:{proxy_port}")
page = await browser.get(f"https://www.tiktok.com/@{username}")
print(f"Loaded profile page for @{username}")
await asyncio.sleep(5)
html_content = await page.get_content()
print(f"Retrieved HTML content ({len(html_content)} characters)")
soup = BeautifulSoup(html_content, 'html.parser')
print("Attempting JSON extraction...")
script_tag = soup.find('script', {'id': '__UNIVERSAL_DATA_FOR_REHYDRATION__'})
if not script_tag:
script_tag = soup.find('script', {'id': 'SIGI_STATE'})
if script_tag:
try:
json_text = script_tag.string
data = json.loads(json_text)
if '__DEFAULT_SCOPE__' in data:
user_info = data['__DEFAULT_SCOPE__']['webapp.user-detail']['userInfo']
elif 'UserModule' in data:
user_info = list(data['UserModule']['users'].values())[0]
else:
raise KeyError("Unknown JSON structure")
profile_data = {
'username': user_info['user']['uniqueId'],
'followers': user_info['stats']['followerCount'],
'likes': user_info['stats']['heartCount']
}
print("Successfully extracted data from JSON")
return profile_data
except (KeyError, IndexError, json.JSONDecodeError) as e:
print(f"JSON extraction failed: {e}")
print("Falling back to HTML attribute extraction...")
print("Using HTML attribute extraction...")
def safe_extract(selector, attribute='data-e2e'):
"""Safely extract text from element"""
element = soup.select_one(f'[{attribute}="{selector}"]')
return element.text.strip() if element else 'N/A'
profile_data = {
'username': safe_extract('user-title'),
'followers': safe_extract('followers-count'),
'likes': safe_extract('likes-count')
}
print("Successfully extracted data from HTML attributes")
return profile_data
except Exception as e:
print(f"Error during scraping: {e}")
import traceback
traceback.print_exc()
return None
finally:
if browser:
browser.stop()
print("Browser closed")
async def main():
"""Main entry point to properly handle async context."""
profile = await scrape_tiktok_profile("iproyal_cz")
if profile:
print("\n" + "="*40)
print("PROFILE DATA")
print("="*40)
print(f"Username: @{profile['username']}")
print(f"Followers: {profile['followers']}")
print(f"Likes: {profile['likes']}")
print("="*40)
else:
print("\nFailed to scrape profile data")
if __name__ == "__main__":
warnings.filterwarnings("ignore")
sys.stderr = open(os.devnull, 'w')
try:
asyncio.run(main())
finally:
sys.stderr = sys.__stderr__
Scraping TikTok Video Metadata
Scraping TikTok video metadata, such as like and comment counts, can follow a similar approach. TikTok video pages also embed JSON data and use data-e2e attributes so that we can write the same web scraping logic for our TikTok scraper.
import nodriver as uc
from bs4 import BeautifulSoup
import json
import time
def scrape_tiktok_video(video_url):
"""
Scrape TikTok video metadata: likes and comment count
Args:
video_url: Full TikTok video URL (e.g., https://www.tiktok.com/@username/video/1234567890)
"""
browser = None
try:
print(f"Starting scrape for video: {video_url}")
# Start browser
browser = uc.start(headless=True)
print("Browser started successfully")
# Navigate to the video page
page = browser.get(video_url)
print("Video page loaded")
# Wait for content to load
time.sleep(5)
# Extract HTML content
html_content = page.get_content()
soup = BeautifulSoup(html_content, 'html.parser')
# Method 1: Try JSON extraction first
print("Attempting JSON extraction...")
script_tag = soup.find('script', {'id': '__UNIVERSAL_DATA_FOR_REHYDRATION__'})
if not script_tag:
script_tag = soup.find('script', {'id': 'SIGI_STATE'})
if script_tag:
try:
data = json.loads(script_tag.string)
# Navigate JSON structure for video data
if '__DEFAULT_SCOPE__' in data:
video_detail = data['__DEFAULT_SCOPE__']['webapp.video-detail']
video_info = video_detail['itemInfo']['itemStruct']
elif 'ItemModule' in data:
# Alternative structure
video_info = list(data['ItemModule'].values())[0]
else:
raise KeyError("Unknown JSON structure")
# Extract video metadata
video_data = {
'likes': video_info['stats']['diggCount'],
'comments': video_info['stats']['commentCount'],
'shares': video_info['stats']['shareCount'],
'views': video_info['stats']['playCount']
}
print("Successfully extracted data from JSON")
return video_data
except (KeyError, IndexError, json.JSONDecodeError) as e:
print(f"JSON extraction failed: {e}")
print("Falling back to HTML attribute extraction...")
# Method 2: Fallback to HTML attributes
print("Using HTML attribute extraction...")
def safe_extract(selector, attribute='data-e2e'):
"""Safely extract text from element"""
element = soup.select_one(f'[{attribute}="{selector}"]')
return element.text.strip() if element else 'N/A'
video_data = {
'likes': safe_extract('like-count'),
'comments': safe_extract('comment-count')
}
print("Successfully extracted data from HTML attributes")
return video_data
except Exception as e:
print(f"Error during scraping: {e}")
return None
finally:
if browser:
browser.stop()
print("Browser closed")
# Test the scraper
if __name__ == "__main__":
video_url = "https://www.tiktok.com/@iproyal_cz/video/6936900534645509382"
video_data = scrape_tiktok_video(video_url)
if video_data:
print("\n" + "="*40)
print("VIDEO METADATA")
print("="*40)
print(f"Likes: {video_data['likes']}")
print(f"Comments: {video_data['comments']}")
print("="*40)
else:
print("\nFailed to scrape video data")
Common Challenges in TikTok Scraping
The approach to TikTok scraping we applied works for smaller projects, collecting metadata. If you need large-scale or real-time data, other tools will be needed. In most cases, you'll use Playwright together with various third-party tools and APIs. Yet, with enough scale, even advanced web scraping approaches don't avoid common challenges.
- IP blocks. TikTok aggressively blocks IP addresses that make too many requests in a short period. It's recommended to use the best proxies for TikTok , distribute requests between different regions, and implement scraping rate limits.
- CAPTCHA and bot detection. TikTok uses advanced CAPTCHA systems and behavior analysis to identify automated browsers. Only minimal, single scraping attempts may ignore some of TikTok's defenses. Consider CAPTCHA solvers or test stealth tools and better TikTok proxies for everything else.
- Dynamic content loading. Some TikTok scraping tasks might require dealing with JavaScript elements, such as infinite scroll and pagination on comments. This makes simple HTTP requests insufficient. Implementing wait times for specific elements and testing them constantly might be a viable solution.
- Frequent HTML structure changes. TikTok updates its frontend regularly, which makes web scraping more difficult. If TikTok scraping isn't a one-time project, you'll need to maintain your scraper. This includes periodic reviews, error logging, and adding new fallbacks to your TikTok scraper.
- Cryptographic headers. TikTok's internal API requires cryptographically signed headers to validate request authenticity. Dealing with security headers, such as X-Gorgon and X-Khronos, is needed when dealing with TikTok's API responses to scrape at scale or download video files directly. An often-used solution is to use third-party signature generators .
Long-term TikTok scraping success often relies on how well you are managing your proxy pool and the quality of user agents you use. With TikTok's heightened security, you need to implement proxy and user agent rotation for at least every tenth request and monitor your success rates and scraping behavior.
Conclusion
TikTok scraping is a constant arms race, and what works today may break tomorrow. While no guide can prepare you for everything, ours aims to cover the fundamental ideas that, with enough practice and resilience, will bring you the desired TikTok user data.


