Web Scraping With PHP and Proxies in 3 Steps
Tutorials

Marijus Narbutas
Web Scraping with PHP is the easiest way to get into scraping. There are many benefits to scraping sites. You can monitor competitors, suppliers, check price changes, and generate insights by looking at data trends. But you need to gather this information first.
According to W3Techs , WordPress powers 43% of the web. This means that at least 43% of the entire world wide web relies on PHP. Thus, running a PHP scraper alongside your site is much easier than learning new languages, setting up new environments, using different servers, and trying to troubleshoot everything from zero.
But even with PHP, there are quite a few challenges. Firstly, the biggest challenge is to render pages correctly (including JS code). Secondly, you need to find out how to avoid getting blocked. Finally, there are some challenges in how to extract data and interact with pages.
Our goal for today is to learn scraping with PHP. This is what you’ll learn:
- The basics of web scraping
- How to pick the right PHP web scraping tool
- How to scrape without getting blocked
- How to extract data from pages
- Interact with pages using a PHP scraper
- FAQ of common technical issues
Let’s get started!
Is PHP Good for Web Scraping?
PHP isn’t the perfect solution for web scraping, but it’s incredibly easy to learn and to get started. It’s good enough for most applications, and the barrier to entry is very low. You just need a PHP server, which you can get from virtually any shared web hosting provider.
Just keep in mind that it isn’t perfect. It can be a bit slow, and you won’t be able to run as many concurrent scraping jobs as you would be able to in NodeJS or Python. Either way, it’s more than enough if you are just starting out or running scraping jobs just for your own business.
Step 1 - Pick the Right PHP Scraping Tool
If you pick the right tool, 99% of your problems are solved. Think about it this way, if you are eating soup, what would you prefer, a fork or a spoon? The same goes for dev tools. Quite often, there are tools that you can use for a job, but they will be too limited. It’s just not worth the effort.
There are many options to pick from - Guzzle, PHP-PhantomJS, Mink, Regex, Symfony/Panther, Chrome PHP, and many more. Luckily, they all fall into four groups of tools for PHP scraping. This makes it easier to analyze them. Here they are:
a) Native PHP Functions (e.g Regex) to Extract Data From the HTML Code
Quite often, there are suggestions to fetch the HTML code of a page, then use regular expressions or other functions to extract data from them. With these functions, you can look for specific tags, then read data. That’s good enough, right?
Regex is excellent for its own things, but web scraping isn’t one of them. Regex is the fork to your soup. It will work in very specific scenarios, and it will break in most of them. Any misclosed tags, self-closing tags, dynamic elements, or sometimes even a dot out of place is enough to turn it into ashes.
If you want to learn Regex, go for it. But if you want to scrape some pages, let’s go for a robust solution.
b) HTML Parsers
This is a common suggestion as well. Some libraries take HTML code and pretend to render the page. It’s a bit better than Regex, but it’s still very limited. You are limited to the parser’s capabilities. If the parser doesn’t implement a specific browser feature, you won’t get the desired results. It’s hard to justify investing your time in a solution that is outdated out of the box.
c) Load Non-HTML Requests (an API, XHR)
This is a clever way to scrape elements without using web scrapers. In this method, you check if the target site has an API or if it loads data dynamically by looking at the XHR requests.
All that sounds complex, but it’s very simple. Open your target site, then open the developer tools and check the network tab. Select only XHR requests (you’ll need to reload the page to see all requests):
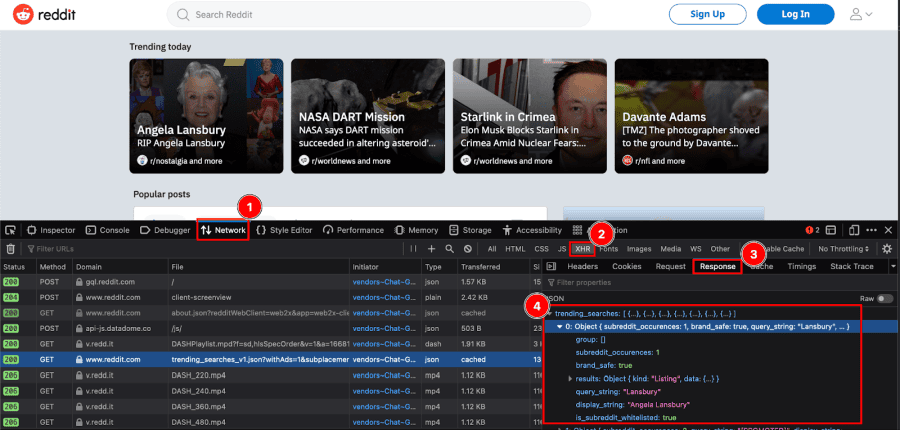
This is reddit.com. But notice how the “trending today” tab is actually loaded as a JSON object. Therefore, if you want to scrape that specific data, you just need to repeat this XHR request. So, if you visit
https://reddit.com/api/trending_searches_v1.json?withAds=1&subplacement=tile&raw_json=1&gilding_detail=1
You’ll get that same JSON object updated for the current date. The same goes for most sites and even sites you wouldn’t expect. Any WordPress site has the JSON API enabled by default. Thus, if you want to scrape it, you just need to access its endpoints.
For instance, you can see TechCrunch’s latest posts here:
https://techcrunch.com/wp-json/wp/v2/posts
The same goes for most custom post types, such as pages and products. So if you want to monitor the prices of a WooCommerce store, you can load this information directly from your target’s API.
When it comes to actually loading this data using PHP, it’s as simple as using one function: cURL. We won’t dive too deep into cURL here, given that we have something even better for you - and you can use it to load XHR requests as well.
It’s time to meet your best partner for PHP web scraping: headless browsers.
d) Headless Browsers
At the end of the day, scraping basically emulates user behavior via code, and headless browsers allow you to do exactly that. With headless browsers, you can open and command browser actions via code.
This is possible because browsers like Firefox and Chrome provide an API that allows developers to interact with them. Therefore, you can do anything you want. You can fill in forms, press keys, move the mouse cursor, click, and take screenshots (including full page or cropped screenshots). You can even run arbitrary JS code, which opens the door to doing literally anything you can imagine.
In this tutorial, we are using Chrome PHP , a very well-maintained library to control Chromium-based browsers. If you want to follow along, you can install it using composer:
composer require chrome-php/chrome
In case you never used composer, it helps you manage code libraries by loading all its dependencies. Thus, when you download chrome-php/crhome, you are creating multiple folders, including Symfony, evenement, monolog and others.
In case you don’t want to use composer at all, you could use https://php-download.com/ or even https://github.com/Wilkins/composer-file-loader. Once you have ChromePHP installed, you can run it from the command line or just create a file like this one:
<?php
use HeadlessChromium\BrowserFactory;
//don't forget to load the library and dependencies
require_once 'vendor/autoload.php';
$browserFactory = new BrowserFactory();
// starts headless chrome
$browser = $browserFactory->createBrowser();
try {
// creates a new page and navigates to an URL
$page = $browser->createPage();
$page->navigate('http://ipv4.icanhazip.com')->waitForNavigation();
// get the IP from a tag
$el = $page->dom()->querySelector('pre');
//get the text from the element
$text = $el->getText();
//output the result
echo "Your IP Address is $text";
} finally {
// close the connection
$browser->close();
}
?>
Then open this file in your browser and it’s all set.
Step 2 - PHP Scraping Without Getting Blocked
There are many ways to detect website scraping. Whether you are loading the XHR request, an API, or using a headless browser, you will get blocked if you’re not careful. Thus, you need to use proxies to blend in and stay under the radar.
The easiest way to implement this in your scraping efforts is by using IPRoyal’s residential proxies service . With it, you can load sites using residential IP addresses, rotating addresses each time.
So, when you load the first page, you are visiting from the US, and on the next page, the target site thinks that you are in Spain. For all they know, these are two different users checking two different pages. Therefore, they can’t block you.
Once you sign up to IPRoyal, you get access to the client area, where you can see your credentials:
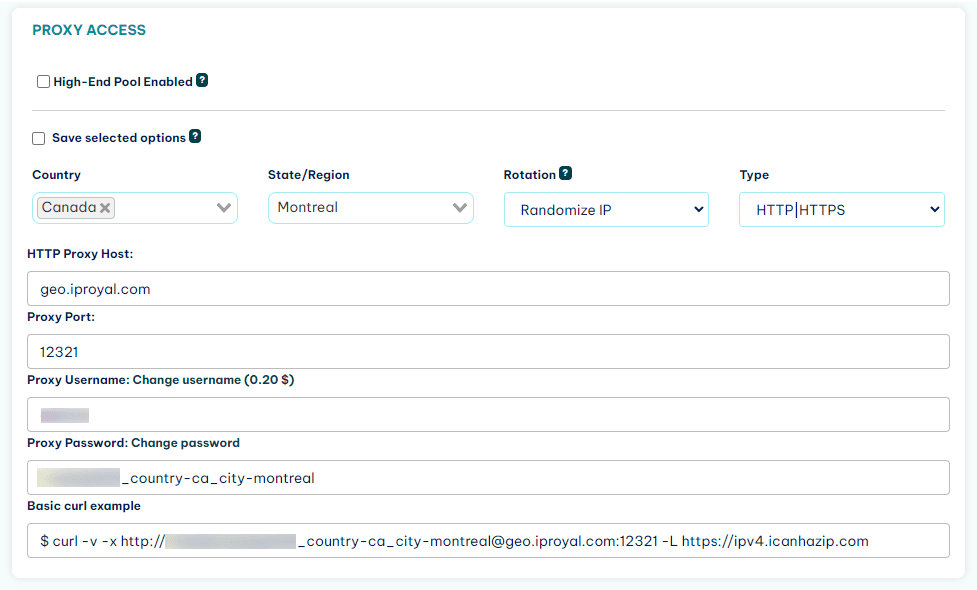
What About Proxy Authentication?
Now it’s time to present to you the first big problem. Chrome doesn’t allow you to use proxy authentication headers. This means that you can set up the IP for your proxy server when you start your browser, like this:
$browser = $browserFactory->createBrowser([
'customFlags' => [ '--proxy-server=http://geo.iproyal.com:12321' ]
]);
But you just can’t pass the username/password information to the proxy server. Luckily, there are two solutions - a one-click solution and a lengthy solution.
The one-click solution is to whitelist your IP on IPRoyal. Click on the Whitelist tab, then add your IP address there. All connections from this IP won’t require credentials.
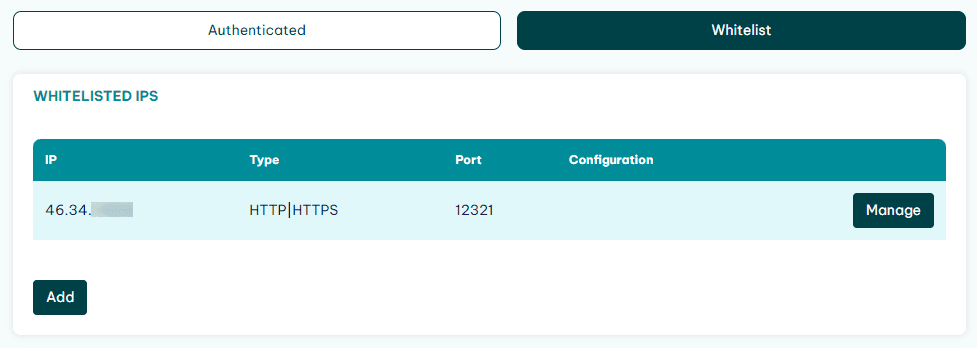
This works fine if you have fixed IPs or if you can manually update this information before you start scraping. If that isn’t possible, you can use mitmproxy. With it, you can basically set up a “bridge” proxy. Instead of connecting directly to IPRoyal, you’ll connect to this bridge, and that little guy connects with IPRoyal sending your credentials.
You can even install mitmproxy on your own computer so that all connections to a specific port of your localhost go to IPRoyal. Thus, your PHP code will look like this:
$browser = $browserFactory->createBrowser([
'customFlags' => [ '--proxy-server=http://localhost:3128' ]
]);
And this 3128 port is the one that connects to http://geo.iproyal.com:12321 using your credentials.
Step 3 - Extract Scraped Data With PHP
Now you can safely connect to any site. It’s time to start scraping! You can extract data using many methods, but there are three methods that cover most of your bases:
a) Screenshot / Generate PDFs
Once you are connected to a page, you can take screenshots using this code:
$page->screenshot()->saveToFile('/foo/bar.png');
And you can save PDFs using this code:
$page->pdf(['printBackground' => false])->saveToFile('/foo/bar.pdf');
Each of these methods has lots of options. Here is a summary of the screenshot options:
- Resize the browser window on launch:
$browser = $browserFactory->createBrowser([ 'windowSize' => [1920, 1000] ]);
- Screenshot format (default is png):
$screenshot = $page->screenshot([ 'format' => 'jpeg' ]);
- Image quality:
$screenshot = $page->screenshot([ 'quality' => 90 ]);
- Crop a screenshot area:
$clip = new Clip($x, $y, $width, $height); $screenshot = $page->screenshot([ 'clip' => $clip ]);
- Full page screenshot:
$screenshot = $page->screenshot([ 'captureBeyondViewport' => true, 'clip' => $page->getFullPageClip() ]);
And these are the PDF options:
$options = [
'landscape' => true, // default to false
'printBackground' => true, // default to false
'displayHeaderFooter' => true, // default to false
'preferCSSPageSize' => true, // default to false (reads parameters directly from @page)
'marginTop' => 0.0, // defaults to ~0.4 (must be a float, value in inches)
'marginBottom' => 1.4, // defaults to ~0.4 (must be a float, value in inches)
'marginLeft' => 5.0, // defaults to ~0.4 (must be a float, value in inches)
'marginRight' => 1.0, // defaults to ~0.4 (must be a float, value in inches)
'paperWidth' => 6.0, // defaults to 8.5 (must be a float, value in inches)
'paperHeight' => 6.0, // defaults to 8.5 (must be a float, value in inches)
'headerTemplate' => '<div>foo</div>', // valid HTML code
'footerTemplate' => '<div>foo</div>', // valid HTML code
'scale' => 1.2, // defaults to 1.0 (must be a float)
];
b) Echo / Save to Variables
Another option to work with variables is to echo or save them. You can use methods to query a CSS selector or an xPath, and then get the text contents of that tag. Here is an example:
//CSS selector
$el = $page->dom()->querySelector('pre');
//get the text from the element
$text = $el->getText();
//output the result
echo "Your IP Address is $text";
You can do the same with xPath:
$elem = $page->dom()->search('//div/*/a');
And even get attributes instead of the text contents:
$attr = $elem->getAttribute('class');
c) Execute JavaScript Functions
You can use PHP scraping along with JavaScript functions. That’s pretty neat! This is possible because the headless browsers will execute a JS snippet and then also send back the results as if you were checking the console log. Here is a simple demo:
//connecting to a URL
page = $browser->createPage();
$page->navigate('https://en.wikipedia.org/wiki/Operation_Sandwedge')->waitForNavigation();
//run JS code to get a tag by ID
$evaluation = $page->evaluate('document.getElementById("firstHeading").textContent');
$value = $evaluation->getReturnValue();
// output it
echo $value;
This code loads a wiki page, then it returns the contents of an ID. You could use a similar approach to pre-process your data if you want.
For example, you can run a JS snippet on a page to get the lowest price of a price list. This saves you processing time later, and allows you to ignore that page if the price is above a threshold.
And that’s it. With these three steps, you are basically ready to set up a headless browser, safely connect to your target pages, and extract data. Now let’s see some bonus content.
How to Interact With Your Target Pages
Sometimes just loading a page isn’t enough to scrape pages using PHP successfully. Maybe you need to fill in a form. Sometimes you need to scroll down to trigger a lazy loading script. Whatever you need, there are a few Chrome PHP methods to help you.
You can interact with the mouse using precise commands:
$page->mouse()
->move(20, 40) // Moves mouse to position x=20; y=40
->click() // left-click on position set above
->click(['button' => Mouse::BUTTON_RIGHT]; // right-click on position set above
->scrollUp(100); // scroll up 100px
Or you can just select a specific element and click on it:
$page->mouse()->find('#myID')->click(); // find and click on an element with id "myID"
$page->mouse()->find('.myclass', 5); // find and click on the 5th (or last) element with class "myclass"
There are methods to use the keyboard as well:
$page->keyboard()
->typeRawKey('Tab') // type a key, such as Tab
->typeText('test'); // type the text "test"
You can fill in form fields by clicking on them, then typing:
$elem->click();
$elem->sendKeys('[email protected]');
Conclusion
Today you learned how to perform web scraping with PHP. You went from the basic steps of picking the right tool to complex page interactions. In the meantime, you’ve also learned the importance of using a residential proxy to avoid getting blocked.
By the end of the day, you should be able to extract data from any site using PHP. In addition, you can pull this data to your own servers since PHP is widely used in web development. You can also spice this up by connecting your Node.js scraper to other PHP libraries, such as a WordPress site, using a plugin.
We hope you enjoyed it, and see you again next time!
FAQ
Fatal error: Uncaught HeadlessChromium\Exception\OperationTimedOut
Sometimes the Chromium app takes too long to load. If this happens whenever you execute your scraper, try increasing its time limit. You can do it on the browser call:
$browser = $browserFactory->createBrowser([
'startupTimeout' => 60 // time in seconds
]);
Fatal error: in vendor\chrome-php\chrome\src\Browser\BrowserProcess.php on browser process
This usually happens when the app isn’t installed or if you are using a different app name. You can fix this by providing the correct app name when you start up the browser factory:
$browserFactory = new BrowserFactory( chromeBinary: '/Applications/Google Chrome.app/Contents/MacOS/Google Chrome' );
Uncaught RuntimeException: Chrome process stopped before startup completed
This could be the same issue as above. Maybe the app name is wrong. Also, it’s worth checking if your current Chrome version is compatible with Chrome PHP. They claim to support Chrome 65+.
Fatal Error HeadlessChromium\BrowserFactory not found
Don’t forget to include the ChromePHP files in your project. You can do it with this code line:
require_once 'vendor/autoload.php';
Wrong object type or Uncaught Error: Call to a member function getText() on null
If you see fatal errors or weird messages regarding the object types, check if the web crawling process is working. And check if the selectors return valid elements. Sometimes there is empty data, which means that there’s something wrong when loading the pages or the elements.


