The Python cURL manual - Web scraping with PycURL
Python

Vilius Dumcius
This is a guide on how to use Python cURL, using the PycURL library. You’ll learn everything about cURL, and how to use it in Python. Then, you’ll see examples of how to scrape websites using PycURL from start to finish, including GET and POST requests, as well as reading JSON data.
Let’s get started!
What is cURL
In short, cURL is a command line tool to connect to servers. You can use it to get or send data to servers, using not just HTTP, but many other protocols. For this reason, cURL is a reliable tool for generic server connections, from web scraping to loading emails.
When it comes to web scraping, cURL is a powerful tool for scraping static websites, XHR contents and loading data from APIs.
Static websites are sites that present you the entire content as a single HTML file. For example, Wikipedia serves you the entire HTML code for each page when you request it. Therefore, you don’t need to process any JS code in it, you can just load this HTML code and scrape whatever data you want from it.
As for scraping XHR contents, this is a good option for modern websites. For example, if you scrape the HTML code of a website like Reddit, there won’t be much data. Most of its contents are loaded via JS, after the initial load.
If you want, you can see the XHR requests using the browser inspector, on the network tab.
Here is an example:
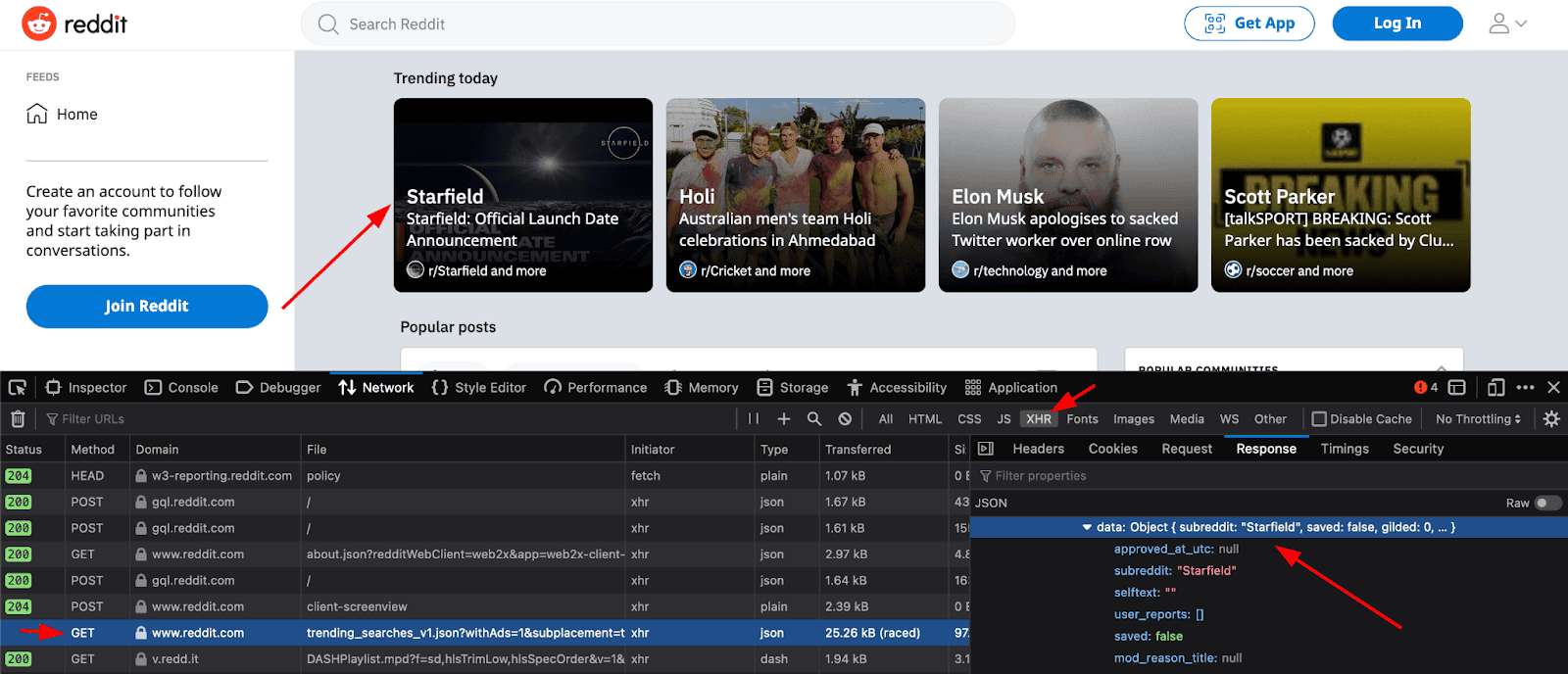
You could use cURL to mimic this GET request and get the trending searches. It might be harder to find which request loads which template parts, but after that it is quite easy to run a cURL command and scrape this data.
What is a cURL equivalent in Python?
There is no native Python cURL command. You can use a library to help you connect to servers and load data, though.
PycURL is a library that allows you to run cURL via Python commands as an interface to libcurl. There are other libraries for connecting to servers as well, such as wget, urllib, httpx and even the request module.
PycURL has its own syntax, which is different from the pure cURL syntax you use on command lines. Thus you need to convert your cURL call into Python commands. If you want to just copy the raw cURL command into Python, you could use subprocess.call or a different library.
How to use PycURL
You need to install and import PycURL to use it in your projects. When it comes to the code itself, you need two variables:
- The connection variable - This variable holds the PycURL command, options, runs the connection
- The outputs variable - This variable holds the contents you receive as a response, so the connection variable writes to the output variable, and you use the output variable in your projects
Now let’s do it.
How to install PycURL
First, make sure you have Python installed. You can download the latest version from the Python downloads page. The latest version includes pip and OpenSSL so you don’t need to install them.
The right command to install PycURL depends on how Python is installed on your server. It can be as simple as:
pip install pycurl
But maybe you need something different. For example, if you installed Python on macOS, you’ll have the default Python version that comes with macOS (such as 2.7). For this reason, if you just run “python” on your terminal, you are running an older version that doesn’t include pip.
In this case, you need to run the new version using its alias, such as phyton3 or phyton3.11 (both will call phyton3.11).
If you want to install PycURL on the latest version, you can run this command:
python3.11 -m pip install pycurl
You can just use the major version number as well, such as:
python3 -m pip install pycurl
Or call pip with the version number, like this:
pip3 install pycurl
How to run PycURL
Once you have Python and PycURL installed, you can start writing some code. You can use any text editor you want, and then you use the command line to interpret that code, like this:
python main.py
Don’t forget to use the correct Python alias, in particular if you have multiple Python versions installed (such as in macOS). For example, on my mac, I need to use:
python3 main.py
Or using the full version name:
python3.11 main.py
These commands will tell the terminal to execute the python compiler for the main.py file. Therefore, make sure that you have navigated using the terminal to the right folder, otherwise it is trying to execute this command on a file that doesn’t exist.
Now let’s create the main.py file, and use this code:
import pycurl
from io import BytesIO
#set up variables
body = BytesIO()
connection = pycurl.Curl()
#curl url
connection.setopt(connection.URL, 'https://ipv4.icanhazip.com/')
#write data to the output variable
connection.setopt(connection.WRITEDATA, body)
#run the command
connection.perform()
#end the session
connection.close()
#extract the response body from the output variable
get_body = body.getvalue()
#decode the utf8 result and display the source code
print('cURL request Body:\n%s' % get_body.decode('utf8'))
And this is the result you’ll get:

This code is doing a couple of things:
- Import the libraries to execute PycURL and data buffering - You need these lines at all times
- Create variables to hold the data buffering and the cURL connection
- Set the URL in the connection variable
- Run the connection
- Close PycURL
- Extract the variable contents and print it
How to use cURL in Python with headers
As you might have noticed, the secret to running the cURL commands is to send them to the connect variable. Therefore, you can use that variable to set up headers or custom cURL options.
Custom headers are important, because you will need a proxy to scrape websites without getting blocked.
Even though web scraping is legal, website owners try to block it. They usually do it by checking the connection headers and the IP address. First, they check the headers to make sure the connection request seems like a legitimate request coming from a real browser. And they check the IP address to see if that user is loading too many pages or if they are loading pages too fast.
Therefore, if you use IPRoyal’s residential proxies service, you can change your IP address on each of your requests. This makes it impossible for website owners to detect that the pages you are loading are sent to a single place. For all they know, these are different requests, from different visitors, located in different places around the world.
To implement this, you just need the connection details you see once you sign up. You can see it in your client area:
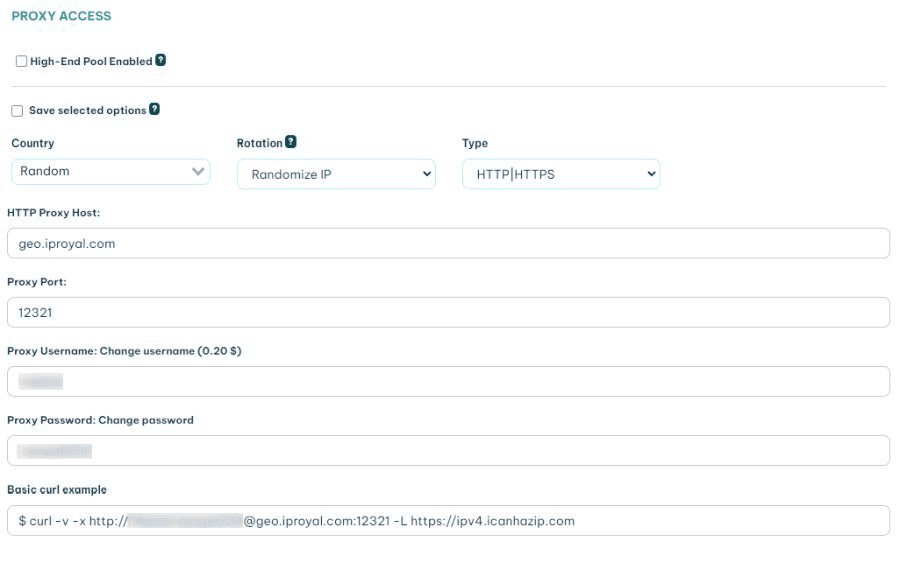
You can add in your code the http proxy url, port, your username and password, like this:
import pycurl
from io import BytesIO
#set up variables
body = BytesIO()
connection = pycurl.Curl()
host = "geo.iproyal.com"
port = "12321"
username = "username"
password = "password"
# set headers
connection.setopt(pycurl.USERAGENT, 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:8.0) Gecko/20100101 Firefox/8.0')
# set proxy
connection.setopt(pycurl.PROXY, f"http://{host}:{port}")
# proxy auth
connection.setopt(pycurl.PROXYUSERPWD, f"{username}:{password}")
#curl url
connection.setopt(connection.URL, 'https://ipv4.icanhazip.com/')
#write data to the output variable
connection.setopt(connection.WRITEDATA, body)
#run the command
connection.perform()
#end the session
connection.close()
#extract the response body from the output variable
get_body = body.getvalue()
#decode the utf8 result and display the source code
print('cURL request Body:\n%s' % get_body.decode('utf8'))
And this is the result you’ll see:

Notice how this is different from the original response, showing that the proxy connection worked.
In this case, the code is quite similar, but there are some new elements:
- More variables to easily hold the proxy data (host, port, username, password)
- connection.setopt(pycurl.USERAGENT, 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:8.0) Gecko/20100101 Firefox/8.0') - this is a custom user agent, otherwise PycURL will identify itself as PycURL, which would be quite easy to block for site owners
- connection.setopt(pycurl.PROXY, f"http://{host}:{port}") - again the setopt is used to set up the proxy URL and port
- connection.setopt(pycurl.PROXYUSERPWD, f"{username}:{password}") - and finally the username and password
You can use the same logic for any custom headers you want to use, as long as they are added using setopt.
PycURL examples
Now let’s understand how PycURL can be useful in your web scraping projects. In particular, let’s explore the different connection types along with some examples of when you can use them.
PycURL GET example
GET connections are the simplest form of browser connections. That’s the same as typing an address in the URL bar. You can use GET requests to scrape simple websites, like Wikipedia.
You can use a library such as the HTMLParser from Python.
Here is a simple example, starting from the connection request:
import pycurl
from io import BytesIO
#curl url
connection.setopt(connection.URL, 'https://en.wikipedia.org/wiki/Yoda')
#write data to the output variable
connection.setopt(connection.WRITEDATA, body)
#run the command
connection.perform()
#end the session
connection.close()
#extract the response body from the output variable
get_body = body.getvalue()
#start parsing the contents
from html.parser import HTMLParser
class MyHTMLParser(HTMLParser):
def handle_starttag(self, tag, attrs):
#if it’s a meta tag
if (tag == "meta") :
#if the meta property is og:title
if ( attrs[0][1] == 'og:title') :
#then display the meta contents
print("Found a title:", attrs[1][1])
parser = MyHTMLParser()
This is the result:

In this example, we connect to Wikipedia, and save the response in a variable. Then we parse this variable.
The meta tags in this document all have two attributes as a list:
- [“property”, “value”]
- [“content”, “value”]
This happens because the HTML code for them is something like this:
<meta property=”propertyname” content=”propertyvalue” />
Therefore, if you want to check the property of a tag, you can access it using attrs[0][1], which is what we did to check if it’s “og:title”. Then, to check the content of that property, you can use attrs[1][1], and that’s what we do to display the contents.
This is just a simple example, but you can scrape entire pages with this method, saving different tags in lists and then processing them later.
PycURL POST example
Sometimes you may need to send POST requests to a page. For example, you might need to fill in a product request form, or maybe send a search form. In this case, you can use this syntax:
import pycurl
from io import BytesIO
from urllib.parse import urlencode
#curl url
connection.setopt(connection.URL, 'https://httpbin.org/post')
#post fields
fields = {'search': 'test query'}
#adding the fields to the request
connection.setopt(connection.POSTFIELDS, urlencode(fields))
#write data to the output variable
connection.setopt(connection.WRITEDATA, body)
#run the command
connection.perform()
#end the session
connection.close()
#extract the response body from the output variable
get_body = body.getvalue()
#decode the utf8 result and display the source code
print('cURL request Body:\n%s' % get_body.decode('utf8'))
And this is the result:
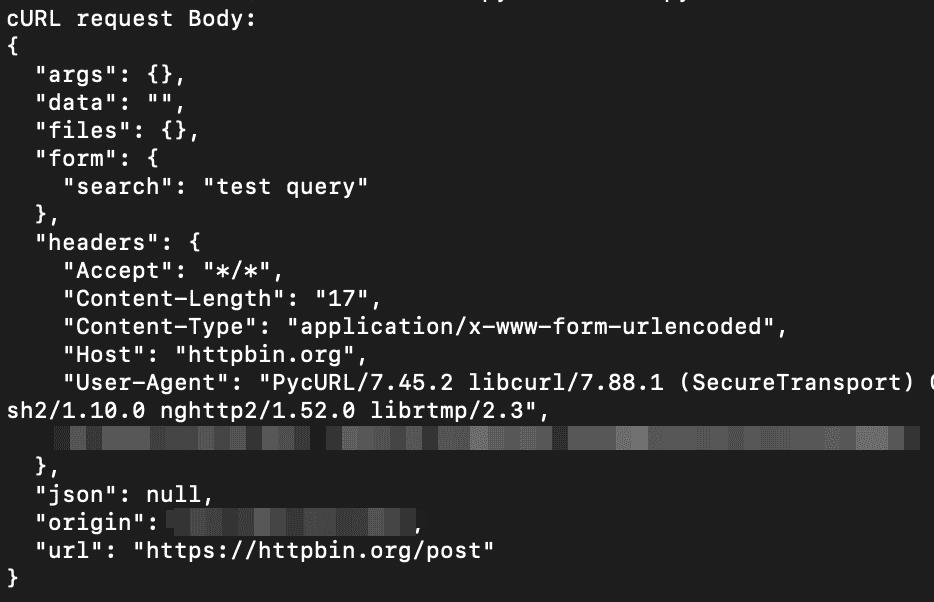
In this case, you need to load the urllib library to encode the post variables. Then, you just need to define these variables and add them to your request.
PycURL XHR or API connection
If you want to use PycURL to load XHR assets or connect to an API you can use GET or POST requests. The right request depends on what you are doing. For example, some API endpoints require you to send some data for processing.
Let’s load Reddit's trending items we saw at the beginning of this tutorial. Notice that the trending items are loaded as a GET request, thus you don’t need to send any post fields:

Next, right click that item and copy the URL. It looks something like this:
https://www.reddit.com/api/trending_searches_v1.json?withAds=1&subplacement=tile&raw_json=1&gilding_detail=1
Then you just need to load this URL with cURL and process the JSON data.
This is the code to do it:
import pycurl
from io import BytesIO
import json
#curl url
connection.setopt(connection.URL, 'https://www.reddit.com/api/trending_searches_v1.json?withAds=1&subplacement=tile&raw_json=1&gilding_detail=1')
#write data to the output variable
connection.setopt(connection.WRITEDATA, body)
#run the command
connection.perform()
#end the session
connection.close()
#extract the response body from the output variable
get_body = body.getvalue()
#save json data in a variable
json_data = json.loads(get_body.decode('utf8'))
#print the variable:
print(json_data)
And this is the result:

Conclusion
Today we looked at how you can use PycURL to run cURL in Python. By the end of the day you should be able to perform requests and scrape data from all types of sites, static or dynamic.
We hope you’ve enjoyed it, and see you again next time!
FAQ
No module named 'pycurl'
This means that pycurl isn’t installed in your Python compiler. If you haen’t already, run pip install pycurl. If you have installed it, double check if you don’t have more than one Python version, you ar probably using the wrong one to run your script.
If none of this works, it’s time to reinstall it and check again.
Pip install pycurl not working
This usually happens when you either don’t have pip or you might not have one of the libraries it needs to install pycurl (such as openssl).
Double check if you are running the correct pip command (and pip3 when applicable). If that doesn’t work, you’ll probably need to delete the current python version, including pip, and install it all again.
ImportError: pycurl: libcurl link-time version is older than compile-time version
This error happens when the cURL version that PycURL is using is an older version. In turn, this happens when you have more than one cURL install, and the old one is the default version.
In this case, remove PycURL, install the latest cURL version, add the environment variables, with commands like these:
export LDFLAGS="-L$HOME/curl-7.86.0/lib -L/opt/homebrew/opt/openssl@3/lib"
export CPPFLAGS="-I$HOME/curl-7.86.0/include -I/opt/homebrew/opt/openssl@3/include"
export PATH="$(HOME)/curl-7.86.0/bin:$PATH"
Then run this command:
pip install --no-cache-dir --compile
--install-option="--with-openssl" pycurl
This should be the magic bullet to reinstall PycURL using the correct cURL version this time.


