How to Pull Data From Any Site – An Illustrated Guide
Tutorials

Marijus Narbutas
You can pull data automatically from any site using three different methods. However, picking the right method to pull data depends on many variables, such as your technical skills, budget, and the data source format. Let’s see which method better suits you with a simple test.
Web scraping is incredibly useful for businesses. You can gather information about your competition, customers, market trends, and monitor price changes. But all these benefits come with a cost. You need to actually gather all this information first.
There are many points to consider, such as how to extract data without getting blocked and how to pull data from your targets. In addition, you need to consider what skills you’ve got to make this work, or how much you can pay someone else to do it.
Therefore, today we are going to explore the main methods you can use to pull data from any site. To make it even easier for you, there’s an illustrated guide and a diagram that you can use to pick the perfect data extraction method for you.
Let’s get started!
What Is Data Pulling?
Data pulling is extracting data from external or internal sources and adding them to a database you can manipulate. This technique is vital for modern businesses, and it’s likely that you did it at some point already without even noticing it.
If you were keeping track of supplier prices, you are pulling data. If you were checking currency exchange rates or stock valuations, you were pulling data. Even if you were just checking the number of followers and likes on your social media profiles, you were pulling data.
But the real benefits come with scale. So you need automated methods to extract data from websites. Once you gather this information, you can use it in many decisions:
- Analyze social media actions and effectiveness
- Benchmark competitors’ content on social media
- Check suppliers’ and competitors’ prices
- Gather data for original research
- Lead generation
- Pull data about your SEO performance, rankings, and keywords
- Gather and organize product reviews for your products and for competitors
- Extract news and mentions about your brand or industry.
How to Extract Data From a Website?
There are broadly three methods to pull data from a website:
- Extract data using code and programming
- Pull data using apps and no-code tools
- Pay third-party companies who did it, or who can do it for you
Each of these methods can be further divided into smaller solutions. For example, you can use an app to get data from Amazon listings. Likewise, you can use Excel to extract data from your competitor’s website. Both options don’t require coding skills and use apps, but they are quite different when it comes to implementing them.
This might still sound confusing, so let’s see which is the perfect option to pull data from any site with a diagram.
How to Pull Data From Any Website?
You can follow this diagram to discover which is the best method for your specific use case.
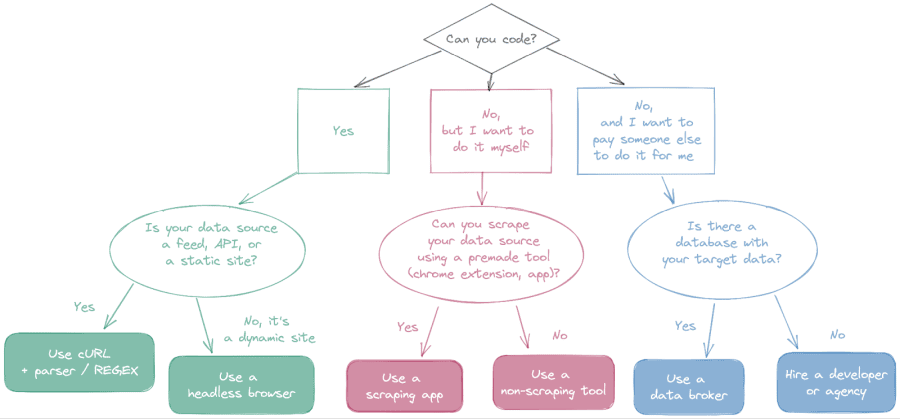
The diagram is divided into the three big branches mentioned before. If you can code, if you can’t code but still want to do it yourself, or if you just want to hire someone to do it.
Here is a summary:
- If you can code:
- Is your data source a feed, API or a static site?
- Yes: use cURL + parser / REGEX
- No: Use a headless browser
- Is your data source a feed, API or a static site?
- If you can’t code, but still want to do it yourself:
- Can you scrape your data source using a premade tool (Chrome extension, app)?
- Yes: Use a scraping app
- No: Use a non-scraping tool
- Can you scrape your data source using a premade tool (Chrome extension, app)?
- If you can’t code and want to hire-android-developers or someone else to do it:
- Is there a database with your target data?
- Yes: Use a data broker
- No: Hire a mobile app developer /agency
- Is there a database with your target data?
Let’s cover each of these use cases in detail now.
How to Pull Data From Any Site Using NodeJS, Python and Other Programming Languages
If you can code (and you want to) then the next big question is about the data source format. Is your target site a feed, API, or a static site? Quite often, sites provide APIs, RSS feeds, and other structured formats that are very easy to pull data from.
But it gets better. Most sites have these options and they don’t even know it.
Popular content management systems such as WordPress come with automatic RSS feeds generation and a REST API enabled by default. In other words, you can scrape WordPress-based store or virtually any blog you want with minimal efforts.
You can visit site.com/feed, or site.com/wp-json/wp/v2/posts and voilá!
In addition, most modern sites load data dynamically using XHR. These are resources loaded after the page is first rendered. You can request these resources just like the website itself did, and read the outputs directly.
For example, the Reddit’s homepage loads the “trending today” items via XHR. You can see these requests by opening the developer tools, then go to the “network” tab in your browser. You’ll see something like this:
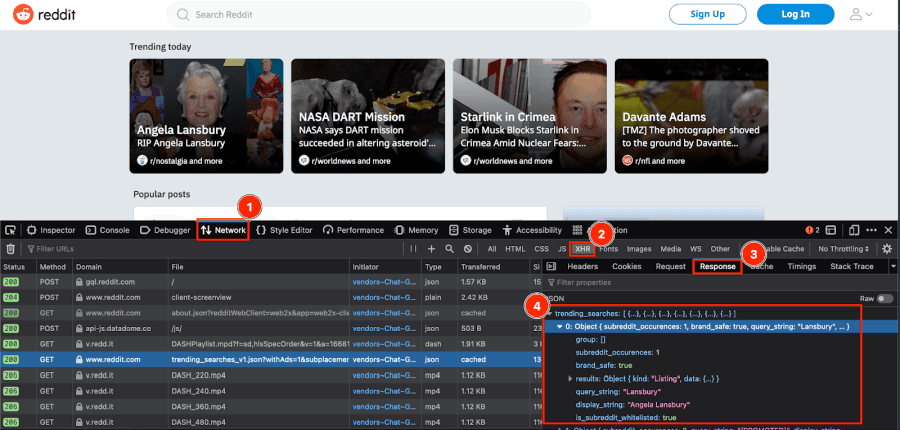
Now you just need to mimic that same request. For any of these cases, you can use cURL and REGEX or a parser. However, there’s an important step - you need to avoid getting blocked.
How to Extract Data Without Getting Blocked
Even though web scraping is legal, a lot of sites are constantly trying to block unwanted bots. For this reason, you need to stay under the radar. Make sure that you can’t be detected. And even if you are, you can start it again.
You can do this by using the IPRoyal’s Residential Proxy service . With it, instead of using just one IP in all requests (your own), each request you make comes from a different IP address. Consequently, this makes it much harder for site owners to ever connect the dots and see that you are the same user requesting these different pages.
You can sign up for the Residential Proxies. After that, you get access to a client area, where you can see your connection details:
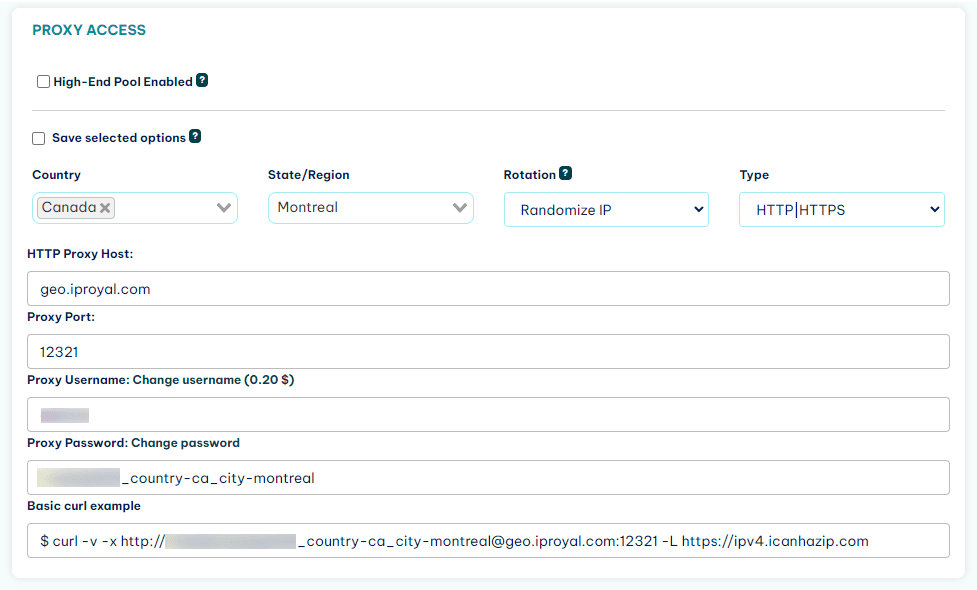
Just use these details in your connection and you are in stealth mode.
If for any reason your connection method doesn’t allow authentication, you can whitelist your IP address on the whitelist tab:
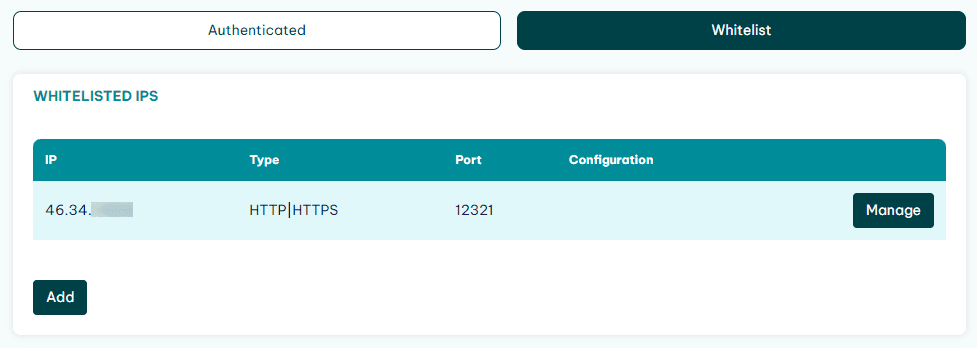
Therefore, you can connect from 177.104.xxx.xxx without the username:password combo.
Back to how you can pull data, with cURL you can pass the proxy details as shown in the demo connection in the client area:
curl -v -x http://[user:password]@proxyURL.com -L https://[targetsite.com]
This is a demo request with the verbose mode, just so you can see what is happening there.
cURL is a flexible library to connect with websites and request their GET data , and it is widely available in many programming languages. It returns the request body: HTML code - for sites, JSON - for APIs, XML - for feeds.
From there, you can use a basic parser to understand the return code and process it.
A big caveat is that this combo won’t allow you to render dynamic pages. In these cases, you’ll need a headless browser. These browsers allow you to use residential proxies as well.
A headless browser is a browser that is controlled by code. Therefore, you can send commands to it and get the return data. There are many options for headless browsers to pull data. You can use a PHP headless browser, a nodeJS headless browser and many others.
If you want a complete toolbox, you might want to consider web crawling with Python. This technique allows you to discover new links and add them to your scraping jobs.
How to Extract Data From Any Site Without Coding?
There is an entire world of tools to pull data from websites. You can get Chrome extensions for LinkedIn, Twitter, Facebook, Google and others. There are apps that you can install on your computer or run from the browser that allow you to gather data and automate tasks.
Here are some tools that you can use:
- Data Miner
- Web Scraper
- Data Scraper
- Grepsr
- ScreamingFrog
- Apify
- iwebscraping
Most of these tools only work with specific sites, though. They are built for a specific purpose. And if that’s what you want, lucky you! There are some general-purpose tools as well, such as Cheat Layer, but they aren’t nearly as flexible as scraping with code.
But the final solution to extracting data without coding comes from a weird question.
Can Excel Pull Data From a Website?
Yes, it can. You can use Excel, Google Sheets, and other non-scraping tools to pull data from your target websites. The trick here is to find ways to proxy your requests, to make sure you won’t get blocked.
Just like with the coding option, you can proxy your requests using many methods. These involve everything from proxying all connections in your computer to using the Excel’s options panel to add proxy details on the data connection panel.
In addition, you can use other tools such as Make (formerly Integromat), Zapier, or even no-code builders like Budibase to pull data. You can use their HTTP requests options with proxy headers.
They can act as a bridge for your other tools, like Google Sheets. This is quite handy when adding a proxy in tools like Google Sheets, or even Excel on Mac is too hard.
Here is an example of a method to pull data from a site using Google Sheets and Make:
- Use Make to load the HTTP request with proxy details
- Save the response (body) in a database (local Make DB or external database connection)
- Use Google Sheets to load this saved resource as a page and extract it using the IMPORTXML function.
That’s it. You can pull data from any site without coding now.
How to Pay for Web Scraping Services?
Finally, there’s the last group. If you can’t code and you don’t want to do it yourself, you can pay for it.
If you want data that is readily available, such as domain names, business lists, data from popular sites (Amazon, eBay, government data, research data), you can buy it.
There are many options for data brokers, and the big plus side is that you can access all data at once, along with a lot of historical data. Some brokers can include future updates in their purchase options, making it easy to keep up with data changes.
But if what you want is an edge case, then you’ll need to hire someone to do it for you. There are some agencies and freelancers who can take your scraping requests and build bots for them. That’s a great way to get all the information you want, without worrying about how you can extract it.
Conclusion
Today you learned how you can pull data from any site. There are three big methods to extract data, depending on if you can code, if you can’t but still want to build your scraper, and if you just want to pay someone else to do it for you.
You can quickly check the diagram to see which one is your case, and find the best tips for pulling data to your needs on the respective section.
We hope you’ve enjoyed it, and see you again next time!
FAQ
Is it legal to extract data from websites?
Yes. According to a supreme court ruling, if it’s public data, you can scrape it. No matter what the terms say, or what the robots.txt file says.
Just make sure that you don’t overload your target website though. DDoSing a site is a form of hacking and can be punished by law.
How can we extract data?
You can extract data from websites using coding scrapers, premade or no-code tools or paying for services that provide you this data. The right option for you depends on your skillset, your budget and your data source format.
How do I extract a CSV file from a website?
There is a simple way to turn websites into CSV files. You can use Excel along with its functions to import from the web, then add multiple xPaths so that you can load each data point on the correct column.


