What are Headless Browsers and How They Work
Expert corner

Hayk Simonyan
If you’re new to the concept, the idea of using a headless web browser might seem overwhelming. Headless browsers are essentially the same web browsers you’re familiar with, but with one key difference: they don’t have a graphical user interface (GUI). That means no buttons, tabs, address bar, or visual display.
Instead, they operate behind the scenes, interacting with websites programmatically through code and commands. This might sound strange at first, but headless browsers offer some unique advantages.
In this guide, we’ll clarify the concept of headless browsers and explore how they work, their benefits and drawbacks, and real-world use cases that can revolutionize the way you interact with the web.
The Headless Approach
The defining characteristic of a headless browser is the absence of a graphical user interface (GUI) — the familiar window with buttons, tabs, and address bars. This is a double-edged sword.
On one hand, eliminating the GUI makes headless browsers incredibly efficient and fast. They do not waste time or resources rendering visual elements like images, which enables them to operate much faster than traditional browsers.
On the other hand, without a GUI, interacting with a headless browser requires a different approach — using a command-line interface (CLI) to control the browser instead of clicking buttons and navigating visually.
While this might seem more complex initially, it opens up a world of automation and customization possibilities. This speed and efficiency are invaluable for tasks like automated testing and web scraping.
Understanding How Headless Browsers Work
While headless browsers lack a visual interface, they still navigate websites and interact with elements, just like regular browsers. The key difference is that you control them programmatically, using scripts and commands. Here’s a simplified breakdown of how it works:
1. Specify the target URL
You provide the headless browser with the web address (URL) you want to visit, just like typing it into a regular browser’s address bar.
2. Navigate with selectors
To interact with specific elements on the page (like buttons, links, or forms), you use special instructions that pinpoint the exact element you want to target.
3. Execute actions
Once you’ve selected an element, you can instruct the headless browser to perform actions on it. This could be clicking a button, filling out a form, scrolling down the page, or extracting specific data.
Think of it like giving a robot precise instructions:
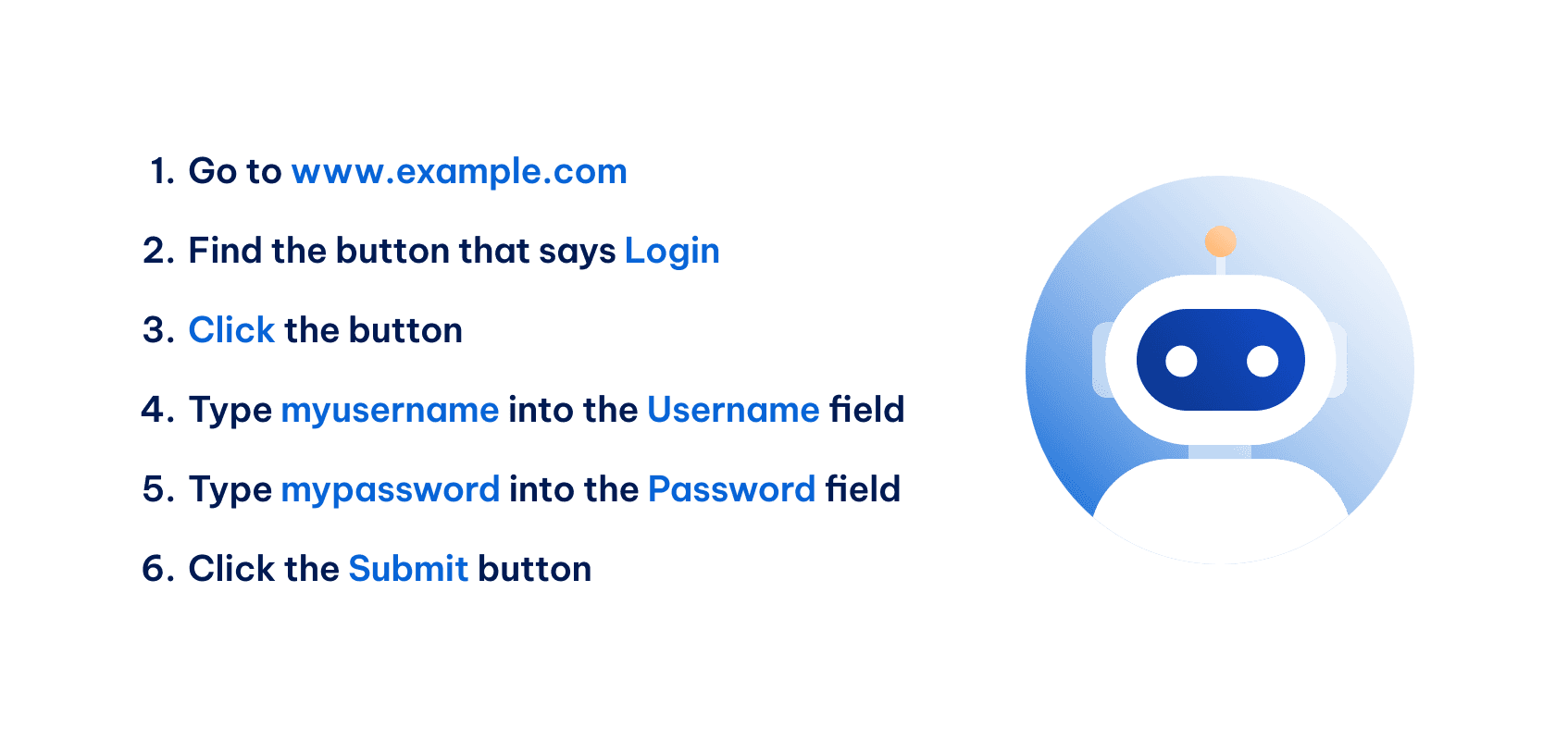
Headless browsers execute these instructions rapidly without the need to render the page visually. This is why they’re so efficient and well-suited for automation tasks.
Headless vs. Traditional Browsers: A Side-by-Side Comparison
While headless and traditional browsers share fundamental similarities, their differences open up unique opportunities. Let’s explore how they stack up:
| Feature | Headless browser | Traditional browser |
|---|---|---|
| Graphical user interface (GUI) | No | Yes |
| User interaction | Programmatic (using scripts and commands) | Direct (using a mouse and keyboard) |
| Speed and efficiency | High | Lower |
| Resource usage | Minimal | High |
| Typical environment | Servers, development | User devices |
| Ideal use cases | Web scraping, automation, testing, background tasks | Web browsing |
Both types of browsers share the same core functionality:
- Rendering engines
They use the same underlying engines to interpret HTML, CSS, and JavaScript, ensuring consistent rendering of web content.
- Web standards compliance
They run on the same rendering engines to maintain similar web standards and ensure compatibility with websites and web applications.
- Session management
Both can manage sessions, cookies, and local storage, preserving information across multiple pages or visits.
- User interaction simulation
While headless browsers interact programmatically, they can still simulate user actions like clicking, typing, and scrolling.
The Benefits of Using Headless Browsers
You may have a rough idea of the factors that set headless browsers apart from normal ones. Let’s narrow it down by presenting the benefits these tools pose for users like yourself.
Blazing-fast Speed and Efficiency
The most significant advantage of headless browsers is their speed and efficiency. By eliminating the need to render visual elements like images, stylesheets, and interactive components, headless browsers can execute tasks much faster than traditional browsers.
In fact, research has shown that headless browsers can be 2 to 10 times faster than their GUI counterparts. This dramatic speed improvement is particularly beneficial for tasks that require rapid execution, such as:
- Automated testing
Headless browsers can quickly run through test scripts, providing faster feedback and accelerating the development process.
- Web scraping
They can rapidly extract data from websites, allowing you to gather large amounts of information in a short amount of time.
Resource Optimization
Headless browsers consume significantly fewer resources than traditional browsers. This is because they don’t need to allocate memory and processing power for rendering visual elements.
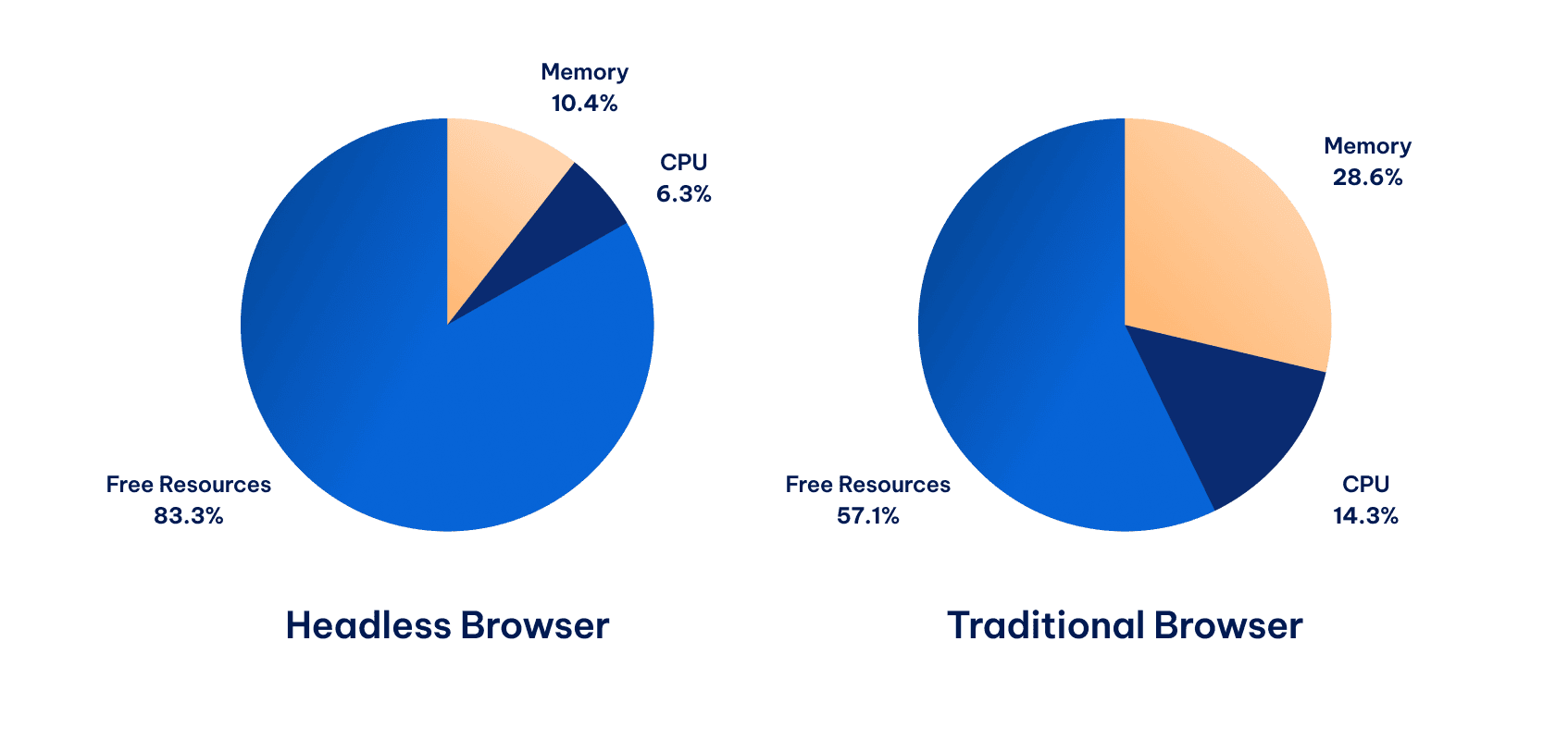
This resource efficiency is especially valuable in scenarios where you’re running multiple browser instances simultaneously, such as:
- Parallel testing
Headless browsers can run multiple tests concurrently on a single machine, saving time and resources.
- Server-side rendering
They can generate website content on the server side, reducing the load on client devices and improving page load times.
Web Automation
Time is a limited resource, especially in business, and headless browsers allow you to focus your time and energy on high-impact tasks rather than tedious, repetitive activities like data entry.
Here are just a few examples of what you can automate using a headless browser:
- Form filling and submission
Imagine needing to create numerous accounts on different platforms. Manually entering data would be a nightmare! Headless browsers can automatically populate forms with information from spreadsheets or databases, saving you hours of work.
- Data extraction (web scraping)
Need to gather product details, pricing information, or contact information from multiple websites? Headless browsers excel at web scraping , extracting data quickly and efficiently, even from dynamic websites that rely heavily on JavaScript.
- Scheduling and reminders
Headless browsers can help you automate appointment bookings, calendar syncing, and other scheduling tasks, ensuring you never miss an important event or deadline.
- Content updates and management
Content managers can use headless browsers to schedule and publish content across various channels.
- Screenshot capture
You can also capture images of web pages for testing, archiving, or analysis.
Robust and Reliable Testing
In addition to automating the tasks mentioned above, you can use a headless browser to run different testing frameworks.

Unlike traditional browsers, which can be affected by user interactions and varying system configurations, headless browsers offer a stable platform for executing tests.
As such, the better option for developers is to write test scripts to facilitate automated headless browser testing. This approach is less resource intensive, offers scripted automation, and is way more efficient and faster than a UI-based browser testing process.
For example, browser testing with headless Selenium can validate various aspects, including a website’s functionality, user interface elements, and responsiveness across different screen sizes.
You can also integrate a headless testing environment into your CI/CD pipeline for higher-quality code and faster feedback through parallel testing. Doing this can significantly improve the software development cycle.
Server Side Execution
Headless browsers are particularly useful for server-side execution tasks because they run without the need to load images or apply CSS. In fact, setting up a headless browser on your server can save you a lot of time and resources. Tasks such as automated web scraping and automated tests will be much smoother.
In addition, headless testing on the server side reduces exposure to client-side vulnerabilities. This is due to better control over the browser testing process by scripting various actions like logging in, filling firms, and interacting with web pages without manual intervention.
In a similar manner, headless browsers offer significant advantages for server-side rendering, a technique where web page content is generated on the server before being sent to the client’s browser.
Many modern websites, especially Single-Page Applications (SPAs) , depend on JavaScript to generate content dynamically. Granted, this goes a long way in boosting user experience, as these pages only load the necessary information based on user actions rather than rendering the full page.
However, it can also create a problem when search engine crawlers fail to access the full-page content when they initially crawl it, which can hurt your SEO.
Fortunately, a headless browser can render dynamic content on the server side, ensuring it is available to users and search engines, even for complex JavaScript-heavy web applications.
Limitations of Headless Browsers
While headless browsers offer numerous advantages, they’re not a one-size-fits-all solution. They also come with certain limitations that are important to consider.
The Invisible User Experience
The most obvious limitation of headless browsers is the absence of a graphical user interface (GUI). While this improves speed and efficiency, it also means you don’t get visual feedback during interactions. This can make debugging and troubleshooting difficult, as you can’t see what’s happening on the screen.
For instance, if a headless browser encounters an error while executing a script, you won’t have the visual cues that a traditional browser provides to help you diagnose the problem. Instead, you’ll need to rely on error messages and logs, which can be less intuitive and require more technical expertise to interpret.
Debugging Challenges in the Dark
Debugging issues in a headless environment can be more challenging than in a traditional browser. Without visual feedback, identifying the root cause of an error can be like searching for a needle in a haystack.

In most cases, browser tests generate a screenshot if something goes wrong. However, headless browser testing does not provide this feature. Instead, you have to depend on the error message to identify which selector couldn’t be found, making the process more complex.
The Need for Technical Expertise
To use headless browsers, you need to have a basic understanding of the Command-Line Interface (CLI), which involves typing commands and scripts instead of clicking buttons.
Additionally, automating tasks with headless browsers often requires writing scripts in languages like JavaScript or Python. It’s also helpful to have a basic understanding of HTML, CSS, and JavaScript to understand how websites are structured and how to interact with them programmatically.
As such, the benefits these web applications pose may not be available to everyone, especially users who lack the prerequisite technical background.
Examples of Headless Browsers
We are now entering the home stretch of our discussion. Now that you understand the power of headless browsers, let’s explore some popular options that you can use to harness their capabilities.
Headless Chrome
It’s no secret that Google Chrome is one of the most popular web browsers today. You can also use the web application in headless mode. Headless Chrome offers excellent compatibility with modern web standards, robust JavaScript support, and a vast ecosystem of tools and libraries.
It provides rich DevTools Protocol API, seamless integration with Puppeteer for browser automation, and is widely used for testing, automation, and web scraping.
Headless Firefox
Headless Firefox is another popular option, especially for those who prefer Mozilla’s open-source ecosystem. While it shares many similarities with Headless Chrome, it might be slightly less efficient in terms of performance.
To put this into perspective, Chrome’s headless mode achieves 30% improved performance compared to the UI version. In contrast, headless Firefox is only 3.68% better than its UI option.
Headless Firefox uses Mozilla’s Gecko rendering engine, which is known for its standards compliance and performance. It’s also compatible with Selenium WebDriver , a widely used framework for browser automation.
Other Headless Browsers
While Headless Chrome and Firefox are the most popular choices, other options exist such as PhantomJS , which was once popular but has since seen a decline in usage due to the rise of Headless Chrome.
Another option is HTMLUnit , which is a Java-based headless browser primarily used to test web applications.
It’s worth mentioning that Apple’s WebKit engine , which is used in Safari, can also be run in headless mode, although it’s not as widely adopted for automation tasks.
In addition to the browsers themselves, several libraries and frameworks make it easier to work with headless browsers, providing higher-level APIs and simplifying common tasks:
- Puppeteer
A Node.js library designed for controlling Chrome or Chromium. Puppeteer offers a comprehensive API for automating browser interactions, making it ideal for web scraping, testing, and other tasks.
- Playwright
Although it’s another Node.js library, Playwright supports multiple browsers (Chrome, Firefox, and WebKit) through a unified API, making it more versatile than Puppeteer.
- Selenium
A well-established suite of tools for browser automation. While primarily used for testing, Selenium can also be used for web scraping and other tasks. It supports multiple languages and browsers.
Conclusion
Headless browsers have revolutionized web development, testing, and automation. By operating without a graphical interface, they deliver unmatched speed, efficiency, and customization.
They empower developers to build better websites, testers to streamline quality assurance, and businesses to automate tasks for increased productivity.
While headless browsers aren’t a universal solution due to their technical nature and lack of visual feedback, their advantages often outweigh their limitations.
If you’re seeking a powerful tool for automation, testing, or server-side rendering, exploring headless browsers could be the key to unlocking new levels of efficiency and innovation in your web projects.
When choosing a headless browser, consider factors like browser compatibility, your preferred programming language, ease of use, performance requirements, and the level of community support available.

